前言
上一篇文章《从0开始学大数据(3):Hadoop本地模式和伪分布模式的应用》我们学习了Hadoop的运行模式——伪分布模式的配置,这篇文章我们来学习另外一种Hadoop的运行模式——完全分布式模式。
配置完全分布式模式
首先我们来分析下我们的整体步骤:
- 1.准备三台客户机(关闭防火墙、静态ip、主机名称)
- 2.安装jdk
- 3.配置环境变量
- 4.安装hadoop
- 5.配置环境变量
- 6.安装ssh
- 7.配置集群
- 8.启动测试集群
通过前面的知识学习,我们的1-5步应该都没有问题了,只需要学习下面的三步就行,下面我们就来学习知识。
准备三台客户机
首先,我们通过Paralles虚拟机对我之前的Centos100进行克隆,然后对配置进行修改
配置静态IP
- 切换用户
sudo su root。遇见sudoers文件问题可以查看这篇文章。 - 使用命令
vi /etc/sysconfig/network-scripts/ifcfg-eth0修改静态IP地址。 - 命令
vi /etc/sysconfig/network添加HOSTNAME=hadoop102。 - 命令
vi /etc/hosts添加ip地址 主机名 - 重启
reboot
忘记了回顾下这篇文章《从0开始学大数据(1):Parallels Desktop下CentOS系统的安装和静态IP地址配置》
安装hadoop
下面说下简单步骤:
- 切换用户
sudo su root - 在
/opt路径下,创建module和software来安装和存放安装包 - 使用命令
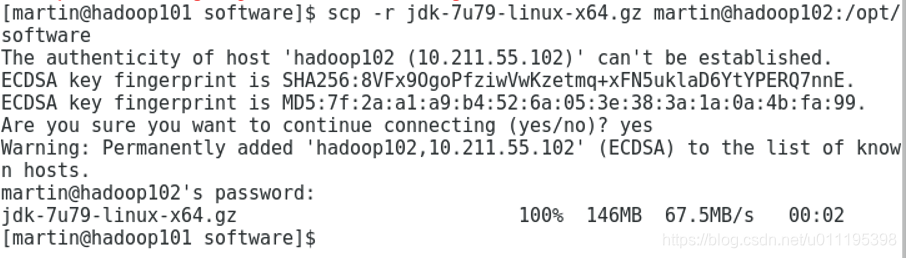
chown martin:martin module/ software的拥有者改为martin用户 - 通过scp命令,虚拟机之间的安装包可以互传,这里传输时候密码最好都设置为一致的,不然以后写脚本很麻烦。
scp -r jdk-7u79-linux-x64.gz martin@hadoop102:/opt/software
-r:表示递归文件或者文件夹
jdk-7u79-linux-x64.gz:传递的文件或者文件夹
martin@hadoop102:/opt/software:用户@主机名:制定路径
更多信息可以查看《Linux scp命令》
- 安装jdk,使用命令
tar -zxvf [JDK安装包] -C [指定路径]完成安装。 - 安装hadoop,使用命令
tar -zxvf [Hadoop安装包] -C [指定路径]完成安装。
忘记了回顾下这篇文章《从0开始学大数据(2):大数据的概论和Hadoop安装》,按照上面的步骤,我们创建出三台虚拟机。
配置无密登陆
平常在我们使用登陆的ssh命令的时候,都需要输入密码这种方式比较麻烦,所以我们可以使用ssh生成密钥对,并且将公钥推送给我们想要登陆的服务器集群,这样就配置好无密登陆了。
- 进入~/.ssh文件
cd ~/.ssh
- 使用ssh命令生成密钥对。
ssh-keygen -t rsa
- 使用命令将公钥推送到某一台集群上
ssh-copy-id hadoop103
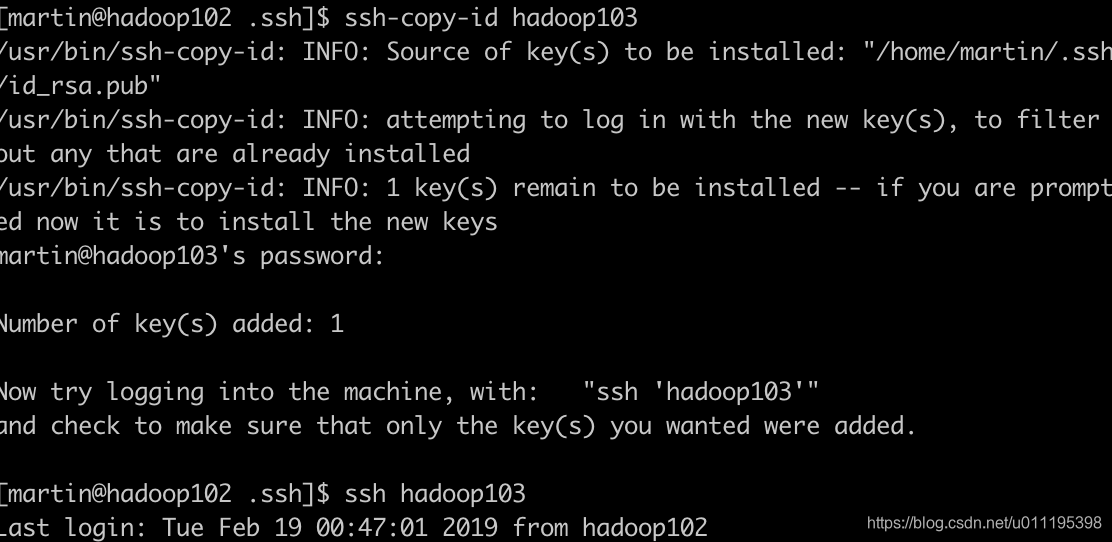
这里需要注意的是,我们需要将免密登陆配置在hadoop102,hadoop103,hadoop103上,后面启动集群的时候如果没有配置无法启动起来。
rsync远程同步工具
rsync命令是一个远程数据同步工具。
- 基本语法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
命令 命令参数 要拷贝的文件路径/名称 目的用户@主机:目的路径
r : 递归 -v:显示复制过程 -l:拷贝符号链接
编写集群分发脚本xync脚本
我们在hadoop102配置好文件后,如果需要同步到各个服务器(hadoop103,hadopp104)上,只需要执行该脚本就不用登陆每台服务器修改同步了,非常方便。
- 在
/usr/local/bin目录下创建xsync文件
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
在编写脚本的时候如果出现中文乱码,由于我是mac使用iterm2去链接的,可以看这篇文章《iTerm2连接远程,中文乱码》。
- 修改脚本 xsync 具有执行权限
chmod 777 xsync
- 调用脚本形式:xsync 文件名称
xsync [文件或文件夹]
在编写的时候,我们可能找不到我们的命令,可以看这篇文章《centos7配置全局变量》
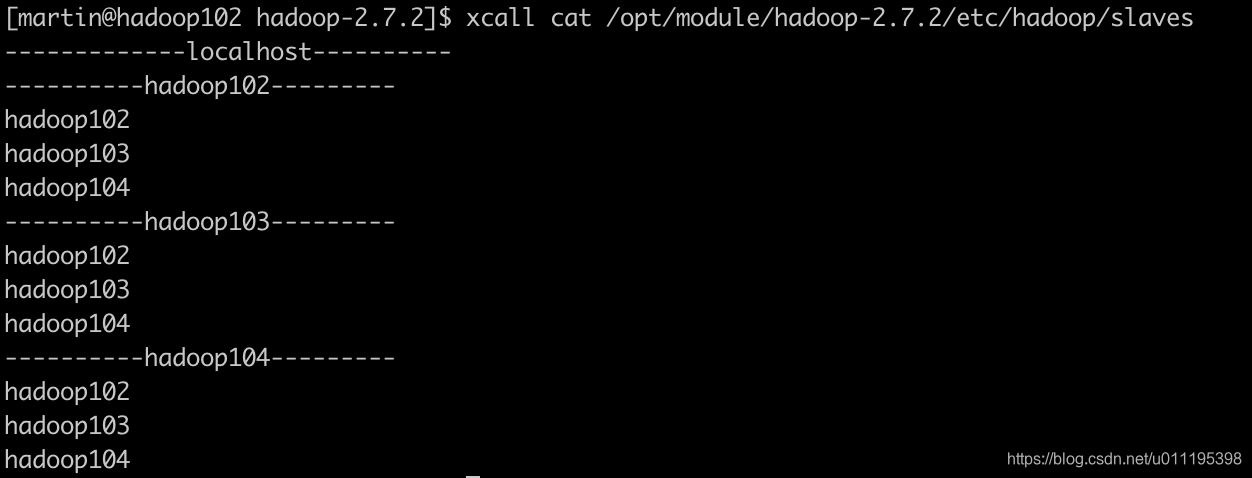
编写分发脚本xcall脚本
编写此脚本的目的是可以在所有主机上同时执行相同的命令。
#!/bin/bash
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
echo -------------localhost----------
$@
for((host=102; host<=104; host++)); do
echo ----------hadoop$host---------
ssh hadoop$host $@
done
- 案例演示
配置集群
这里,我们需要将NameNode,dataNode,NodeManager分布的配置在每一台服务器上。首先,我们需要清楚每台服务器配置什么,下面是准备配置的表格。
| Hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| NameNode | SecondaryNameNode | – |
| DataNode | DataNode | DataNode |
| NodeManager | ResourceManager | NodeManager |
配置文件
- core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
-
HDFS
hadoop-env.sh

- hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property> </configuration> - slaves
配置数据节点hadoop102 hadoop103 hadoop104
-
YARN
yarn-env.sh

- yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> </configuration> -
mapreduce
mapred-env.sh

- mapred-site.xml
<configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
同步文件
进入/opt/module/hadoop-2.7.2/etc执行命令
xsync hadoop/
启动集群
二次启动需要做得准备工作
如果之前我们启动过后,并没有启动成功,那么会在服务器上留下一些日志和数据,这个时候,我们需要使用Xcall工具删除。
xcall rm -rf /opt/module/hadoop-2.7.2/data/ /opt/module/hadoop-2.7.2/logs/
这里的路径需要些绝对路径,否则无法找到
正式启动
- 格式化
第一次我们启动,需要格式化namenode,也就是目录。
bin/hdfs namenode -format
- namenode和datanode服务开启
开启我们的目录和数据节点
sbin/start-dfs.sh
日志
[martin@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
Starting namenodes on [hadoop102]
hadoop102: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-martin-namenode-hadoop102.out
hadoop103: datanode running as process 26996. Stop it first.
hadoop104: datanode running as process 23860. Stop it first.
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-martin-datanode-hadoop102.out
Starting secondary namenodes [hadoop104]
hadoop104: secondarynamenode running as process 24426. Stop it first.
[martin@hadoop102 hadoop-2.7.2]$ jps
8368 Jps
7959 DataNode
7835 NameNode
- 启动Yarn
注意:NameNode和ResourceManager如果不是同一台机器,不能在NameNode上启动yarn,应该在ResourceManager所在的机器上启动yarn。
那么我们就需要在hadoop103上去执行启动命令,在启动前,我们需要去使用hadoop103去配置无密登陆。
sbin/start-yarn.sh
日志
[martin@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
starting yarn daemons
resourcemanager running as process 8853. Stop it first.
hadoop104: nodemanager running as process 5715. Stop it first.
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-martin-nodemanager-hadoop103.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-martin-nodemanager-hadoop102.out
[martin@hadoop103 hadoop-2.7.2]$ jps
10494 Jps
10352 NodeManager
26996 DataNode
8853 ResourceManager
集群启动及测试
启动完成后,我们可以输入网址http://hadoop102:50070/explorer.html#/到浏览器中访问下。
上传文件到集群
- 创建文件夹
[martin@hadoop102 ~]$ hadoop fs -mkdir -p /user/martin
[martin@hadoop102 ~]$ hadoop fs -lsr /
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - martin supergroup 0 2019-02-19 23:46 /user
drwxr-xr-x - martin supergroup 0 2019-02-19 23:46 /user/martin
- 上传文件
[martin@hadoop102 hadoop-2.7.2]$ mkdir input
[martin@hadoop102 hadoop-2.7.2]$ cd input
[martin@hadoop102 input]$ touch helloworld.txt
[martin@hadoop102 input]$ vi helloworld.txt
[martin@hadoop102 input]$ cd ..
[martin@hadoop102 hadoop-2.7.2]$ hadoop fs -put input/helloworld.txt /user/martin/input/
- 上传文件后查看文件存放在什么位置
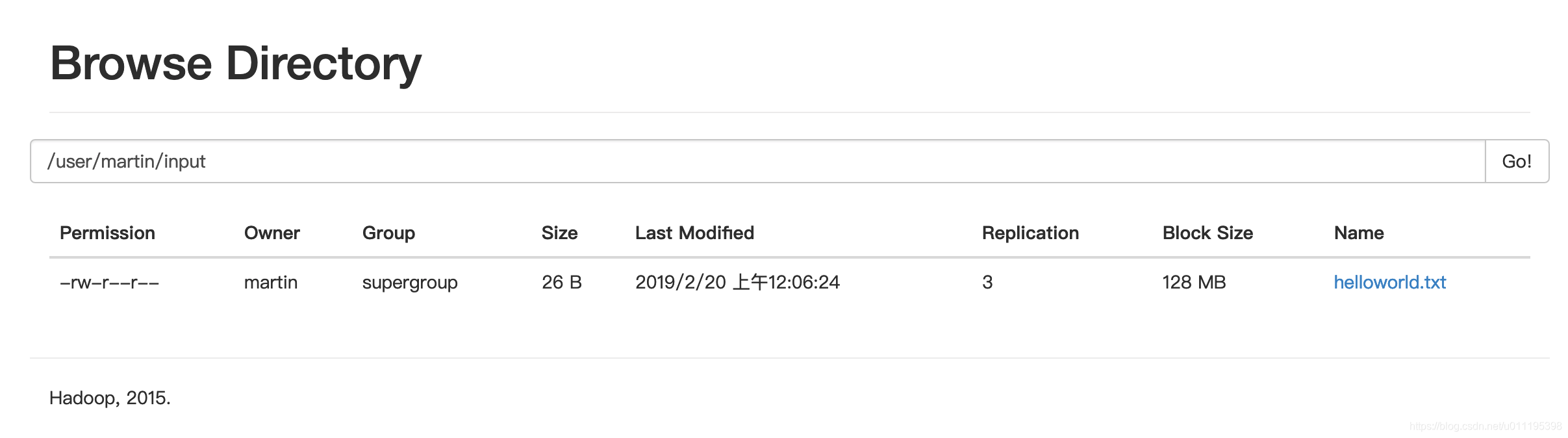
[martin@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr /
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - martin supergroup 0 2019-02-19 23:46 /user
drwxr-xr-x - martin supergroup 0 2019-02-20 00:06 /user/martin
drwxr-xr-x - martin supergroup 0 2019-02-20 00:06 /user/martin/input
-rw-r--r-- 3 martin supergroup 26 2019-02-20 00:06 /user/martin/input/helloworld.txt
[martin@hadoop102 hadoop-2.7.2]$ hadoop fs -cat /user/martin/input/helloworld.txt
welcome to hadoop world .
文件过大后是如何存放的?
当我们存储的数据超过128M的时候,数据将会分块进行存储,一直到文件存储不需要分块为止,下面我来演示一下。
hadoop fs -put /opt/software/hadoop-2.7.2.tar.gz /user/martin/input/
通过命令,我们将超过128M的hadoop安装包上传到了系统中。我们就分别用Block0和Block1来进行存储。
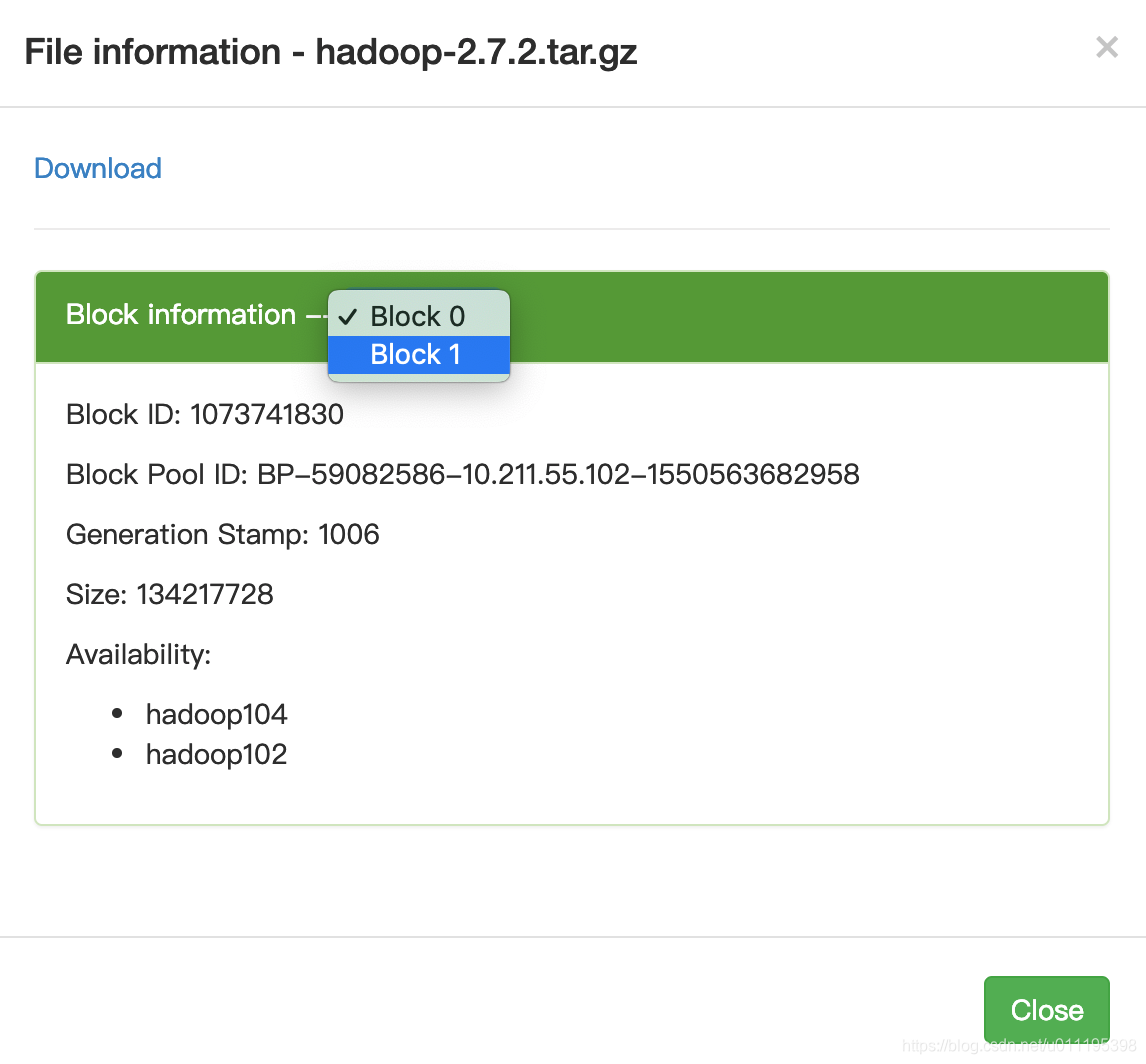
经过查找,我们再hadoop104中查找到了路径/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-59082586-10.211.55.102-1550563682958/current/finalized/subdir0/subdir0针对存储Block ID: 1073741830的位置就是存储我们hadoop安装包的块数据。

我们可以通过验证,证明我们的猜想,执行下面的命令:
[martin@hadoop104 subdir0]$ touch hadoop_tmp
[martin@hadoop104 subdir0]$ cat blk_1073741830 >> hadoop_tmp
[martin@hadoop104 subdir0]$ cat blk_1073741831 >> hadoop_tmp
[martin@hadoop104 subdir0]$ tar -zxvf hadoop_tmp
hadoop-2.7.2/
hadoop-2.7.2/NOTICE.txt
hadoop-2.7.2/etc/
hadoop-2.7.2/etc/hadoop/
...
[martin@hadoop104 subdir0]$ ll
total 604024
-rw-rw-r--. 1 martin martin 26 Feb 20 00:14 blk_1073741828
-rw-rw-r--. 1 martin martin 11 Feb 20 00:14 blk_1073741828_1004.meta
-rw-rw-r--. 1 martin martin 134217728 Feb 20 00:57 blk_1073741830
-rw-rw-r--. 1 martin martin 1048583 Feb 20 00:57 blk_1073741830_1006.meta
-rw-rw-r--. 1 martin martin 63439959 Feb 20 00:57 blk_1073741831
-rw-rw-r--. 1 martin martin 495635 Feb 20 00:57 blk_1073741831_1007.meta
drwxr-xr-x. 9 martin martin 149 May 22 2017 hadoop-2.7.2
-rw-rw-r--. 1 martin martin 197657687 Feb 20 01:08 hadoop_tmp
通过上面的命令,我们可以看到当blk_1073741830和blk_1073741831合并后的文件就是我们上传的之前hadoop安装包。
下载
hadoop fs -get /user/martin/input/helloworld.txt ./
Hadoop启动停止方式
- 关闭namenode和datanode
[martin@hadoop102 hadoop]$ stop-dfs.sh
Stopping namenodes on [hadoop102]
hadoop102: stopping namenode
hadoop103: stopping datanode
hadoop102: stopping datanode
hadoop104: stopping datanode
Stopping secondary namenodes [hadoop104]
hadoop104: stopping secondarynamenode
- 关闭yarn
[martin@hadoop102 hadoop]$ stop-yarn.sh
stopping yarn daemons
no resourcemanager to stop
hadoop104: no nodemanager to stop
hadoop103: stopping nodemanager
hadoop102: no nodemanager to stop
配置集群的常见问题
- 防火墙没关闭,或者没有启动yarn
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
- 主机名配置错误
- ip地址配置错误
- ssh没有配置好
- root用户和atguigu两个用户启动集群不同一
- 配置文件修改不细心
- 未编译源码
- datanode不被datanode识别问题
Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
- 不识别主机名称
Namenode在format初始化的时候会形成两个标识,blockPoolId和clusterId。新的datanode加入时,会获取这两个标识作为自己工作目录中的标识。
一旦namenode重新format后,namenode的身份标识已变,而datanode如果依然持有原来的id,就不会被namenode识别。
解决办法,删除datanode节点中的数据后,再次重新格式化namenode。
小结
这篇文章我们主要是学习了如何去配置hadoop的完全分布式并且启动集群和测试集群的操作,下篇文章主要讲解HDFS。