一. TIME模块
python提供了一个time和calendar模块可以用于格式化日期和时间。
时间间隔一秒为单位。
每个时间戳都以1970年1月1日午夜经过多长时间来表示。
1.时间戳
函数time.time()用于获取当前时间戳。
import time print(time.time()) 结果: 1553066028.9183624
2.时间元祖:
很多python函数用一个元组装起来的9组数字来处理时间。
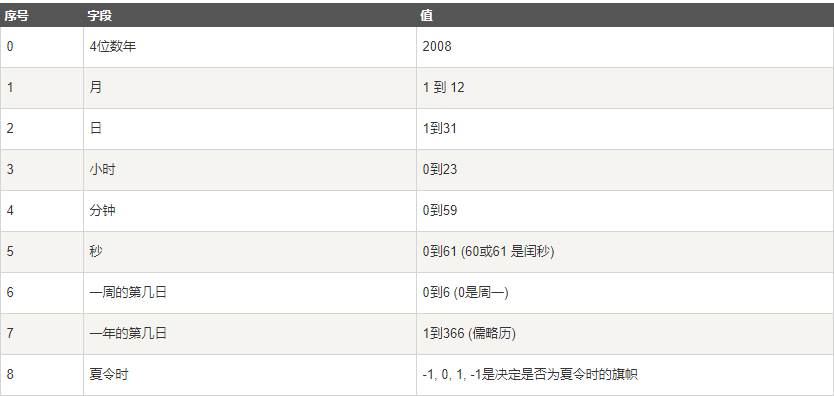
上述就是struct_time元组,且具有如下属性:
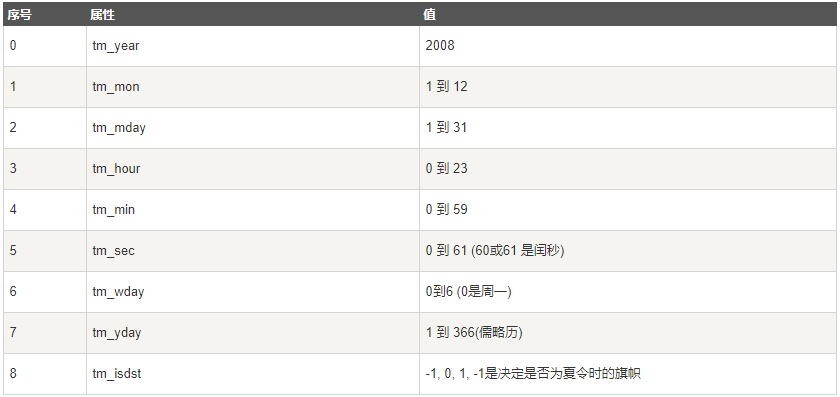
tm_yday 显示是一年的第几天。
怎么去获取当前时间?
从返回浮点数的时间戳向元组时间转换,用localtime函数
import time
localtime=time.localtime(time.time())
print('本地时间:',localtime)
结果:
本地时间: time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=15, tm_min=24, tm_sec=52, tm_wday=2, tm_yday=79, tm_isdst=0)
#这里是命名元组,可以索引,步长。
3.格式化时间
time模块中的strftime方式来格式化日期。
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
#这里的格式可以改变的
结果:
2019-03-20 15:31:35
4.时间格式转换:

import time
#TIME 模块
#2019-03-20 将时间退后一个月。
f=time.strptime('2019-03-20 10:40:00','%Y-%m-%d %H:%M:%S')
将格式化时间转换成时间元组(结构化时间)
print(f)
new_T=time.mktime(f)+30*24*60*60
#将时间元组(结构化时间)转换成时间戳,在进行运算
print(new_T)
new_t=time.localtime(new_T)
#将计算后的时间戳转化成结构化时间。
print(new_t)
print(time.strftime('%Y-%m-%d %H:%M:%S',new_t))
#将结构化时间转化成格式化时间
结果:
2019-04-19 10:40:00
实现了从格式化时间》时间元组》时间戳》时间元组》格式化时间。timestamp(时间戳)
import time
#当前时间求前一个月时间
new_T=time.time()-28*24*60*60
f1=time.localtime(new_T)
print(f1)
print(time.strftime("%Y-%m-%d %H:%M:%S",f1))
结果:
2019-02-20 16:21:01
实现了从时间戳》时间元组》格式化时间。
二.COLLECTION 模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
A.namedtuple能够用来创建类似于元组的数据类型,除了能够用索引来访问数据,能够迭代,更能够方便的通过属性名来访问数据。
from collections import namedtuple
friend=namedtuple('friend',['name','age','email'])
f1=friend('林冲',28,'178*****[email protected]')
print(f1)
print(f1.email)
f2=friend('李逵',age=29,email='15***[email protected]')
print(f2)
name,age,email=f2
print(name,age)
结果:
friend(name='林冲', age=28, email='178*****[email protected]')
178*****[email protected]
friend(name='李逵', age=29, email='15***[email protected]')
李逵 29
from collections import namedtuple
def get_name():
name=namedtuple('name',['first','middle','last'])
return name('JOHN',"you know nothing",'snow')
name=get_name()
print(name.first,name.middle,name.last)
结果:
JOHN you know nothing snow
B.deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:提供了两端都可以操作的序列。在序列的前后都能执行添加或删除操作。
import collections
d=collections.deque() #创建双向队列
d.append('Ada lace') #右侧添加元素
d.appendleft('I love ')
print(d)
结果:
deque(['I love ', 'Ada lace'])
import collections
d=collections.deque() #创建双向队列
d.append('Ada lace') #右侧添加元素
d.appendleft('I love ')
print(d)
d.clear() #清空队列
print(d)
结果:
deque(['I love ', 'Ada lace'])
deque([])
import collections
d=collections.deque()#创建双向队列
d.append('蓝天白云。。。') #右侧添加元素
d.appendleft('爱就像 ')
print(d)
d.extendleft([3,2,1]) #从左侧队列扩展列表元素
print(d)
结果:
deque(['爱就像 ', '蓝天白云。。。'])
deque([1, 2, 3, '爱就像 ', '蓝天白云。。。'])
import collections
d=collections.deque()#创建双向队列
d.append('蓝天白云。。。') #右侧添加元素
d.appendleft('爱就像 ')
d.extend([3,2,1]) #从左侧队列扩展列表元素
print(d)
print(d.index(3)) #该方法返回查找对象的索引位置,如果没有找到对象则抛出异常。
print(d.index('爱就像 ',0,1)) #从索引0到1,定义了查找区间
结果:
deque(['爱就像 ', '蓝天白云。。。', 3, 2, 1])
2
0
C.Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter
L=Counter({'k':1})
l1=Counter([1,2,'ada',1])
print(L)
print(l1) #显示元素和出现次数
结果:
Counter({'k': 1})
Counter({1: 2, 2: 1, 'ada': 1})
https://www.jb51.net/article/115578.htm(关于defaultdict的文章)
from collections import defaultdict
li = [('红色',1),('黄色',1),('绿色',1),('蓝色',1),('红色',5),('绿色',1),('绿色',1),('绿色',1)]
d = defaultdict(list)
for i in li:
d[i[0]].append(i[1])
dd = dict(d)
print(dd)
for em in dd:
dd[em] = sum(dd[em])
print(dd)
结果:
{'红色': [1, 5], '黄色': [1], '绿色': [1, 1, 1, 1], '蓝色': [1]}
{'红色': 6, '黄色': 1, '绿色': 4, '蓝色': 1}