简介
- SparkSQL is not about SQL,Spark SQL is about more than SQL:这俩说明了SparkSQL不仅仅只是一个SQL的功能,它的功能远超于它的字面意思。
- 官方介绍:Spark SQL是Spark处理数据的一个模块,跟基本的Spark RDD的API不同,Spark SQL中提供的接口将会提供给Spark更多关于结构化数据和计算的信息。其本质是,Spark SQL使用这些额外的信息去执行额外的优化,这儿有几种和Spark SQL进行交互的方法,包括SQL和Dataset API,当使用相同的执行引擎时,API或其它语言对于计算的表达都是相互独立的,这种统一意味着开发人员可以轻松地在不同的API之间进行切换。
- Spark SQL is Apache Spark’s module for working with structured data:spark是apache的一个模块,它是用来处理结构化的数据,例如具有schema结构的json, parquet, avro, csv等格式的文件。
为何使用SparkSQL
- 使用SQL来进行大数据处理,这本身就为传统的RDBMS人员降低了要求,因为这不需要使用人员掌握像mapreduce的编程方法。
- SparkSQL 可以支持SQL API,DataFrame和Dataset API多种API,这意味着开发人员可以采用DataFrame和Dataset API 进行编程,这和采用Spark core 的RDD API 进行编程有很大的不同,首先,并不像使用RDD进行编程时,开发人员在采用不同的编程语言和不同的方式开发应用程序时,其应用程序的性能千差万别,但如果使用DataFrame和Dataset进行开发时,资深开发人员和初级开发人员开发的程序性能差异很小,这是因为SparkSQL 使用Catalyst optimizer 对执行计划做了很好的优化。
- 其次,SparkSQL既然对底层使用了很好的优化方式,这就让开发人员在不熟悉底层优化方式时也可以进行很好的程序开发,降低了开发人员对程序开发的门槛。
- 最后,SparkSQL 对外部数据源(External Datasource)做了很好的支持,像对关系型数据库,如mysql,可以使用外部数据源的方式使用SparkSQL对数据库里面的数据直接进行处理,而不需要像以前使用sqoop导入导出。
Spark SQL和Hive On Spark的区别
- 很多人误以为Spark SQL 和 Hive On Spark是一个东西,其实不然,这里对二者做一个简单的介绍:Spark SQL的前身是Shark, Shark 刚开始也是使用了hive里面一些东西的,但随着后来的发展,Shark始终不能很好的支持Hive里面的一些功能,这是因为在版本的更迭和Hive的多年发展,有些东西并不能始终支持,Shark 终止后,SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive On Spark 是Hive 想要将底层的执行引擎在Spark上做很好的支持,并且想要对Hive的底层执行引擎做更多的支持.
SparkSQL 架构
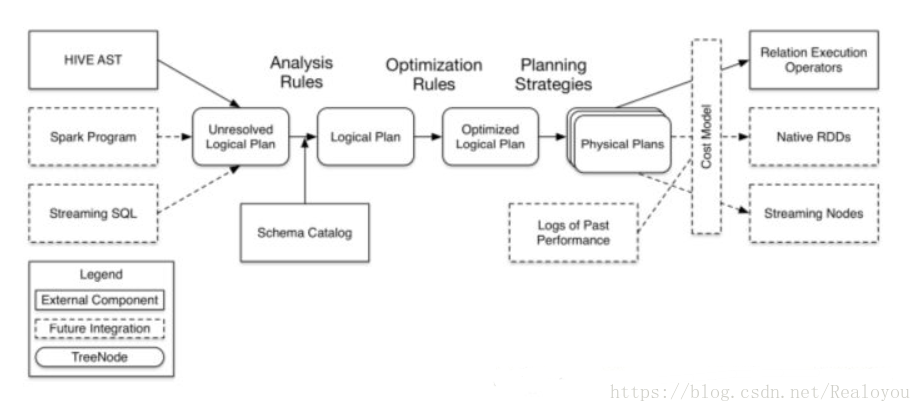
* SparkSQL架构分为前,后,中,三个部分,其中中间部分的Catalyst optimizer是架构的核心,也是SparkSQL 优化的关键所在。
前
- 前部分描述了不同的访问方式
1)典型的我们可以使用hive,HQL语句就是一个字符串,那么这个字符串如何才能够被Catalyst进行解析呢,或者说如何将一个HQL语句翻译成spark的作业呢,他要经过解析的,生成一个抽象语法树,这是第一种访问方式。
2)第二种访问方式,我们可以通过spark的应用程序,编程的方式来操作,编程的时候我们可以使用SQL,也可以使用dataframe或者是dataset api。
3)第三种是Streaming SQL,也就是说流和SQL综合起来使用。
优化中心
- 1)前部分的三个访问方式过来以后他首先会生成一个Unresolved Logical Plan,也就是一个没有解析的一个执行计划,这个执行计划会和我们的元数据,也就是metastore里面的schema一个表信息进行整合然后生成一个Logical Plan(逻辑执行计划)。
2)这个逻辑执行计划是最原始的,中间还会做各种优化也很多规则作用上去,也就是图中的Optimization Rules,然后进行优化以后生成优化过后的逻辑执行计划,就是图中的Optimized Logical Plan。
3)那么优化过后的逻辑执行计划生成完了以后,才会生成物理执行计划,也就是我们spark的一个作业。
查看SQL执行计划
- 启动spark-sql
查看
1. spark-sql> explain extended 2. > select t1.id * (2+3), t2.name 3. > from test1 t1 join test1 t2 4. > on t1.id = t2.id and t1.id>10;解析
1. == Parsed Logical Plan == 2. 1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection(字段)、哪些是Data Source(表)等,从而判断SQL语句是否规范; 3. 'Project [unresolvedalias(('t1.id * (2 + 3)), None), 't2.name] 4. +- 'Join Inner, (('t1.id = 't2.id) && ('t1.id > 10)) 5. :- 'SubqueryAlias t1 6. : +- 'UnresolvedRelation `test1` 7. +- 'SubqueryAlias t2 8. +- 'UnresolvedRelation `test1` 9. == Analyzed Logical Plan == 10. 2.分析逻辑执行计划,解析字段类型、表和查询条件; 11. (id * (2 + 3)): int, name: string 12. Project [(id#32 * (2 + 3)) AS (id * (2 + 3))#36, name#35] 13. +- Join Inner, ((id#32 = id#34) && (id#32 > 10)) 14. :- SubqueryAlias t1 15. : +- SubqueryAlias test1 16. : +- CatalogRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#32, name#33] 17. +- SubqueryAlias t2 18. +- SubqueryAlias test1 19. +- CatalogRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#34, name#35] 20. == Optimized Logical Plan == 21. 3.优化逻辑规划,一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize); 23. Project [(id#32 * 5) AS (id * (2 + 3))#36, name#35] 24. +- Join Inner, (id#32 = id#34) 25. :- Project [id#32] 26. : +- Filter (isnotnull(id#32) && (id#32 > 10)) 27. : +- CatalogRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#32, name#33] 28. +- Filter (isnotnull(id#34) && (id#34 > 10)) 29. +- CatalogRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#34, name#35] 30. == Physical Plan == 31. 4.物理执行计划(Physical Plan),按Operation-->Data Source-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。 32. *Project [(id#32 * 5) AS (id * (2 + 3))#36, name#35] 33. +- *SortMergeJoin [id#32], [id#34], Inner 34. :- *Sort [id#32 ASC NULLS FIRST], false, 0 35. : +- Exchange hashpartitioning(id#32, 200) 36. : +- *Filter (isnotnull(id#32) && (id#32 > 10)) 37. : +- HiveTableScan [id#32], CatalogRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#32, name#33] 38. +- *Sort [id#34 ASC NULLS FIRST], false, 0 39. +- Exchange hashpartitioning(id#34, 200) 40. +- *Filter (isnotnull(id#34) && (id#34 > 10)) 41. +- HiveTableScan [id#34, name#35], CatalogRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#34, name#35] 42. Time taken: 1.419 seconds, Fetched 1 row(s) 43. 18/04/22 06:04:43 INFO CliDriver: Time taken: 1.419 seconds, Fetched 1 row(s)Tree和Rule
SparkSQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。