论文链接: Graph Convolutional Networks for Text Classification
Idea:
- 基于一个数据集内的共现词和文档构建一个文本异构图网络。
- 在文本图网络中,单词和文档向量初始化形式为one-hot,在文档已知类标签的监督下,联合学习单词和文档的向量化表示。
- 图网络能够有效的处理关系型(结构化)数据,可以以图的形式保留全局性结构化信息在图嵌入形式中。
Method
Graph Convolutional Networks (GCN)
GCN是一种直接操作在图上的多层神经网络,并根据节点的邻域属性来生成节点的嵌入式向量表达。在一个图中G=(V,E),V和E分别代表节点集合和边集合。在该模型中,假设每个节点都与其自己自连接,(v,v)∈![]() E。X ∈
E。X ∈ ![]() Rn*m代表一个包含n个节点的矩阵,其每个节点特征向量的维度为m,节点v的原始特征向量为xv。邻域矩阵为A,由于假设节点都是自连接的,所以A的主对角线上的元素都为1。当GCN网络只有一层的时候,其只能捕获节点周围的直接邻域信息,换句话说当网络层数较多时能够捕获节点周围较大的邻域信息。例如,节点特征维度为k的节点特征矩阵L,L(1)∈
Rn*m代表一个包含n个节点的矩阵,其每个节点特征向量的维度为m,节点v的原始特征向量为xv。邻域矩阵为A,由于假设节点都是自连接的,所以A的主对角线上的元素都为1。当GCN网络只有一层的时候,其只能捕获节点周围的直接邻域信息,换句话说当网络层数较多时能够捕获节点周围较大的邻域信息。例如,节点特征维度为k的节点特征矩阵L,L(1)∈![]() Rn*k。
Rn*k。
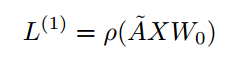
![]() A为归一化对称邻近矩阵,Wo为权重矩阵,最后加激活函数。对于多层GCN来说:
A为归一化对称邻近矩阵,Wo为权重矩阵,最后加激活函数。对于多层GCN来说:
![]()
J为所处的网络层数,L(0)=X。
Text Graph Convolutional Networks (Text GCN)
论文中构建了一个大型的异构文本图网络,图中包含单词节点和文档节点,以至于全局共现词可以被明确的构建出。如下图所示,文本图网络中的节点的数量为文档节点个数(数据集的大小)加上数据集中包含的不重复单词的个数(词汇表的大小)。

论文中设置X=I作为一个单位矩阵,这意味着单词和文档都以one-hot这种形式来作为文本图网络的输入。模型基于某个单词在某个文档中出现的概率构建文档-单词边,基于单词在整个数据集中出现的共现概率构建单词-单词边。其中文档-单词边上的权重是基于TF-IDF(逆文档频率)来确定的。论文发现使用TF-IDF是优于仅仅使用单词在文档中出现的频率。为了利用全局性的单词共现概率,该模型设置了一个固定长度大小的窗口,去收集整个数据集中的单词共现次数。两个节点之间的权重是通过PMI(逐点互信息)来计算的。论文中也发现了使用PMI是优于仅仅使用单词之间的共现次数的。具体来说,节点i和节点j边上的权重被定义为如下:

两个节点之间的逐点互信息计算如下:
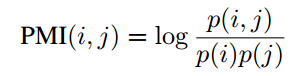
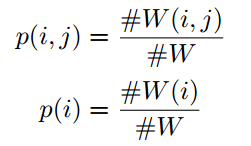
#W(i)是在整个数据集上滑动窗口中包含单词i的数量,#W(i,j)是在整个数据上滑动窗口中同时包含单词i和j的数量,#W是在整个数据集上滑动窗口的总的数量。PMI为正数的时候代表两个单词之间具有较高的语义关联度,相反,PMI为负数的时候代表两个单词之间的语义关联程度较小或者是没有语义关联。所以,论文只采纳两个单词间PMI值大于0这种情况。
在构建出文本图表示后,在其上添加两层的GCN网络。在第二层GCN网络上,其节点(word/document)嵌入表示具有和被标注集相同的尺寸大小。之后,其被丢入softmax分类器中:
![]()
损失函数被定义为和标签数据之间的交叉熵损失:
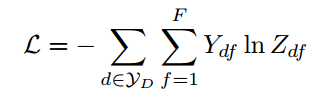
YD是被标签文档的集合,F是输出特征向量的维度,同时,F也和总类别的个数相同。Y是标签矩阵。权重矩阵W0和W1通过梯度下降算法训练。
从图网络的信息传递原理来讲,一个两层的GCN最多允许节点之间的信息传播路径为2。所以,在该模型中虽然没有明确的定义文档-文档边,但是路径为2的GCN允许两个文档之间进行信息交互。
Experiment
Text GCN相对于baselines方法取得成功的原因论文中认为有如下两个方面:(1)GCN可以捕捉到文档-单词关系,单词-单词关系。(2)在GCN网络中,一个节点新的状态是由它本身和它的二阶邻域加权求平均取得的。

GCN在五个数据集上和众多的baseline方法的具体对比如上图所示。
Parameter Sensitivity
论文中详细对比了在不同数据集上超参数变化对实验结构的影响。

滑动窗口的大小如上图所示,在15大小的时候比较合适。节点向量维度如下图所示在200维时比较合适。

Effects of the Size of Labeled Data
不同比例的有监督标签数据对模型的影响如下图所示:

Document Visualization
下图展示了,在GCN网络第一层网络节点特征维度为200,和在GCN网络第二层网络节点特征为20时可视化表达。

Word Visualization

上图展示了在20NG数据集上,word embedding的可视化展示。其代表数据集中每个单词和20个类别的相关程度。下表还展示了四个类别中,单词与其相关程度最高的十个单词。