kafka生产者工作流程
消息产生分析
1.写入方式:
producer采用推(push)模式将消息发布到broker,每条消息都会被追加(append)到分区Partition上,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障了kafka的吞吐率)
2.分区Partition
消息发送时都被送到一个topic上,其本质就是一个目录,而topic是由一些partition Logs分区日志组成,一个topic可以由多个Partition组成。如下图:
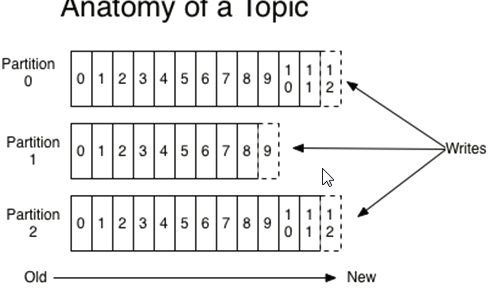
每个Partition上的消息都是有序的,生产的消息都会被不断追加到Partition log上,其中的每一个消息都会被赋予一个唯一的offset值。
分区原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成。因此整个集群就可以适应任意大小的数据了
(2)可提高并发,因为可以以Partition为单位读写
分区的原则
(1)指定了partition,则直接使用
(2)未指定partition但指定了key,通过对key的value进行hash出一个partition
(3)partition和key都未指定,则使用轮询一个partition
3.副本Replication
同一个partition可能会有多个replication(对用着server.properties配置中的default.replication.factior=N)。没有replication的情况下,一旦broker宕机,其上所有的partition的数据都不可被消费,同时producer也不能再将数据存于其上的partition,引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选择一个Leader,producer和Consumer只与这个leader交互,其他replication作为follower从leader中复制数据
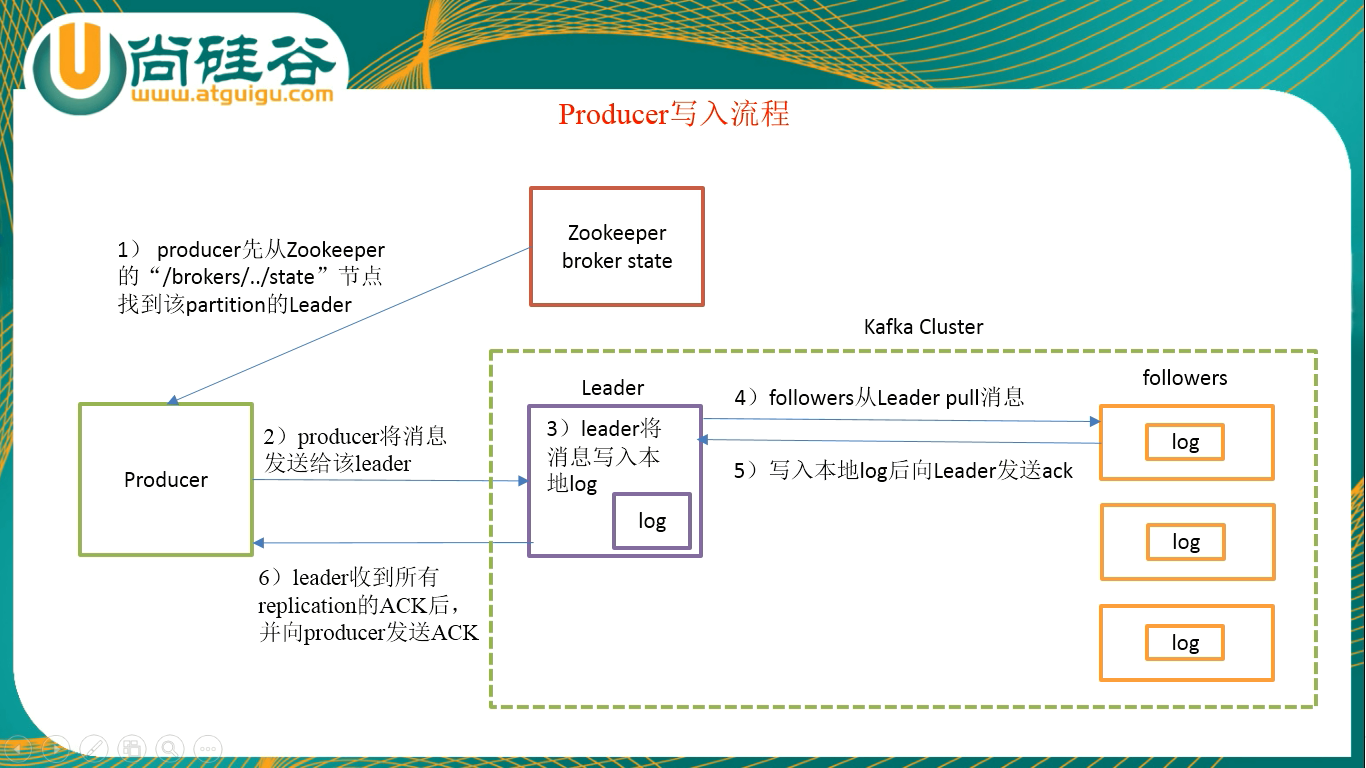
(1)Zookeeper记录了Leader是哪一个
(2)Producer不与Follwers交互
4.存储方式
物理上把topic分成一个或者多个partition(对应server.properties中的num.partitions=3配置),每个partition物理上对应也给文件夹,该文件夹存储该partition的所有消息和索引文件,
kafka命令:
kafka-topics.sh --create --topic first --zookeeper localhost:2181 --replication-factor 3 --partitions创建3个副本:first0,first1,first2