目录
1.什么是xml文档?
请看如下截图,xml文档的一般格式:

如果还想深入了解xml文件,可以参考详细博客,链接如下:
https://blog.csdn.net/com_ma/article/details/73277535
2.提取xml文档的信息
python和java都有对应处理xml文档的库,我们只要熟悉需要使用到的方法即可。举例如下:图一中import xml.dom.minidom是调用的处理xml文档的库,图二则展示了其中的一些方法。

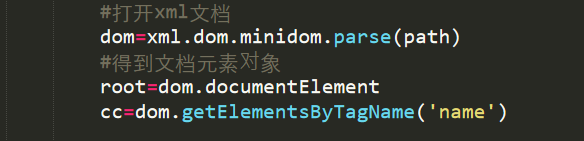
3.遍历多个xml文档,并进行数据分析
详细代码与解析如下(根据个人需要而编写,所以不能照搬照抄,仅供参考)
#coding=utf-8
import xml.dom.minidom
import os
import sys
rootdir='G:/Datasets/rider_voc_aug/Annotations'#存有xml文件的文件夹的绝对路径
list=os.listdir(rootdir)#列出文件夹下所有的目录与文件
classes_list=[]
classes_count_imag=[1,1,1,1,1,1,1]#统计含有各个目标的图片数
classes_count_object=[1,1,1,1,1,1,1]#统计各个目标的总数
for i in range(0,len(list)):
path=os.path.join(rootdir,list[i])
if os.path.isfile(path):
#用于区分imag和object
flag=[0,0,0,0,0,0,0]
#打开xml文档
dom=xml.dom.minidom.parse(path)
#得到文档元素对象
root=dom.documentElement
cc=dom.getElementsByTagName('name')
for i in range(len(cc)):
c1=cc[i]
#如果是新的目标则将其加入classes_list数组中
if classes_list.count(c1.firstChild.data)==0:
classes_list.append(c1.firstChild.data)
#统计imag和object的个数
else:
for j in range(0,len(classes_list)):
if(classes_list[j]==c1.firstChild.data):
if(flag[j]==0):
classes_count_imag[j]+=1
flag[j]=1
classes_count_object[j]+=1
#print(classes_list)
#print(len(classes_list))
for i in range(len(classes_list)):
print("目标%20s imga:%10d个 object:%10d个"%(classes_list[i],classes_count_imag[i],classes_count_object[i]))