首先需要安装lxml库
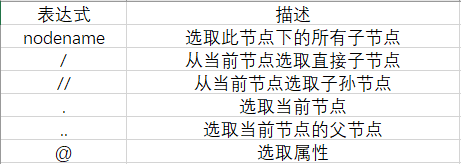
XPath常用规则
etree模块
etree模块可以自动修正HTML文本,调用tostring()方法即可输出修正后的HTML代码,但结果是bytes类型,这里利用decode()方法将其转成str类型
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html>first item</a></li>
<li class="item-1"><a href="link2.html>second item</a></li>
<li class="item-inactive"><a href="link3.html>third item</a></li>
<li class="item-1"><a href="link4.html>fourth item</a></li>
<li class="item-0"><a href="link5.html>fifth item</a></li>
</ul>
</div>
'''
html=etree.HTML(text)
result=etree.tostring(html)
print(result.decode("utf-8"))
输出
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html>first item</a></li> <li class=" item-1=""/><a href="link2.html>second item</a></li> <li class=" item-inactive=""/><a href="link3.html>third item</a></li> <li class=" item-1=""/><a href="link4.html>fourth item</a></li> <li class=" item-0=""/><a href="link5.html>fifth item</a></li> </ul> </div> "/></li></ul></div></body></html>
另一种直接读取文本文件
html=etree.parse("test.html",etree.HTMLParser())
所有节点
一般会用//开头的XPath规则来选取所有符合要求的节点。
html=etree.parse("test.html",etree.HTMLParser())
result=html.xpath('//*')
print(result)
输出:
[<Element html at 0x20b3f697a48>, <Element body at 0x20b3f697a88>, <Element div at 0x20b3f697ac8>, <Element ul at 0x20b3f697b08>, <Element li at 0x20b3f697b48>, <Element a at 0x20b3f697bc8>, <Element a at 0x20b3f697c08>, <Element a at 0x20b3f697c48>, <Element a at 0x20b3f697ec8>, <Element a at 0x20b3f697b88>]
这里使用*代表匹配所有节点,也就是整个HTML文本中的所有节点都会被获取。
子节点
通过/或//即可查找元素的子节点或者子孙节点
result=html.xpath('//li/a') #获取li节点的所有直接a子节点
/用于获取子节点,//用于获取子孙节点
父节点
用…来实现,也可以通过parent::来获取父节点
属性匹配
用@进行属性过滤
result=html.xpath('//li[@class="item-0"]')
输出:[<Element li at 0x1dbd11ee948>]
文本获取
用XPath中的text()方法获取节点中的文本
result=html.xpath('//li[@class="item-0"]//text()')
属性获取
用@符号即可
result=html.xpath('//li/a/@href')
属性多值匹配
contain()方法第一个参数传入属性名称,第二个参数传入属性值,只要属性包含所传入的属性值,就可以完成匹配
多属性匹配
同时匹配多个属性可以使用运算符and来连接

按序选择
选取第一个结果,传入数字1
最后一个结果括号中传入last()
小于3的结果即<3
倒数第三个结果即-2