7.1.2 处理流
除了dumps()和loads(),pickle还提供了一些便利函数来处理类似文件的流。可以向一个流写多个对象,然后从流读取这些对象,而无须事先知道要写多少个对象或者这些对象有多大。
import io
import pickle
import pprint
class SimpleObject:
def __init__(self,name):
self.name = name
self.name_backwards = name[::-1]
return
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('preserve'))
data.append(SimpleObject('last'))
# Simulate a file.
out_s = io.BytesIO()
# Write to the stream.
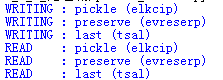
for o in data:
print('WRITING : {} ({})'.format(o.name,o.name_backwards))
pickle.dump(o,out_s)
out_s.flush()
# Set up a readable stream.
in_s = io.BytesIO(out_s.getvalue())
# Read the data.
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print('READ : {} ({})'.format(
o.name,o.name_backwards))
这个例子使用两个BytesIO缓冲区来模拟流。第一个缓冲区接受腌制的对象,它的值被填入第二个缓冲区,load()将读取这个缓冲区。简单的数据库格式也可以使用pickle来存储对象。shelve模块就是这样一个实现。
除了存储数据,pickle对于进程间通信也很方便。例如,os.fork()和os.pipe()可以用来建立工作进程,从一个管道读取作业指令,并把结果写至另一个管道。管理工作线程池以及发送作业和接收响应的核心代码可以重用,因为作业和响应对象不必基于一个特定的类,使用管道或套接字时,在转储各个对象之后不要忘记刷新输出,以便将数据通过连接推送到另一端。参见multiprocessing模块来了解一个可重用的工作线程池管理器。
运行结果: