今天遇到一个案例,有点价值写下来,以后多看看 SQL: select t.order_id, t.spec_name, t.staff_code, t.staff_code as xxbStaffCode, t.channel_id as xxbChannelId, t.area_code, t.create_time, t.id_card from zmkm_intent_order t, zmkm_order_ext_val s where t.order_id = s.order_id and exists (select 1 from JS_SERVICE.zmkm_order_ext_val k where k.order_Id = t.order_id and k.param_id = '100007' and k.ext_val = '18190044') and t.deal_flag = 0 and t.area_code = '0516'; 执行计划:
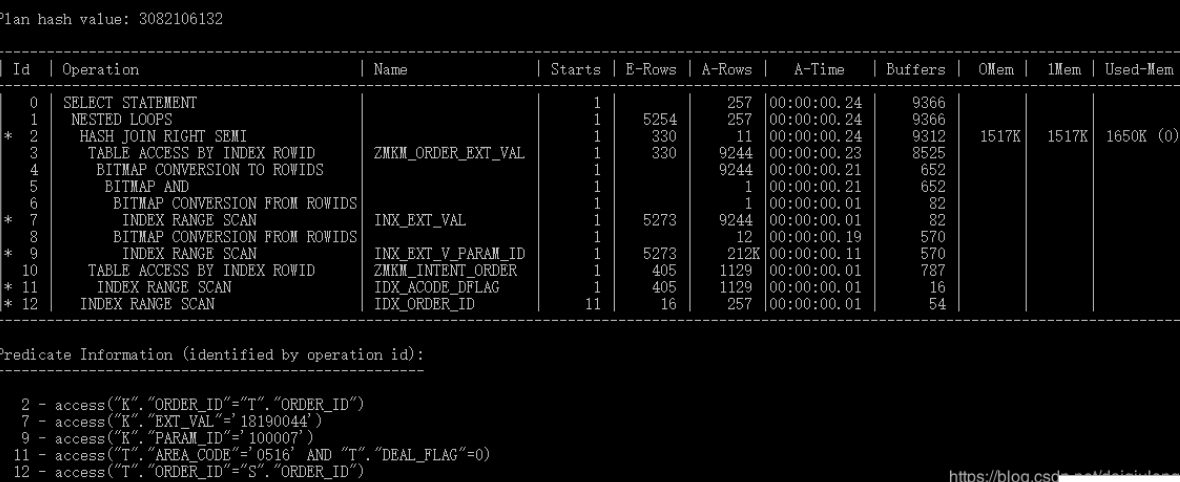
SQL的性能瓶颈在ID = 3.仔细看E-rows 才330条, 偏小很多。 但是为啥是 330呢。 分别explain plan for select count(1) from zmkm_order_ext_val k where k.param_id = '100007'; select count(1) from zmkm_order_ext_val k where k.ext_val = '18190044' rows 第一个是21万, 第二个是5千。但是BITMAP CONVERSION TO ROWIDS参与后就330. 就是因为rows 估算成330,导致这个搞成驱动表。 因此导致两个索引合并后真实数据量是9千, 大量的回表K。造成了性能问题。 如果这边搞成被驱动表, 那么显然就是根据索引访问K。并且此时驱动表的数据也不多,大概是 1000多条 NL下去也是不错的。 想到这边差不多知道答案了。期间尝试 数次 cardinality hint 无果。 SQL> alter session set "_b_tree_bitmap_plans"=false; 会话已更改。 已选择352行。 执行计划 ---------------------------------------------------------- Plan hash value: 141468126 ---------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5254 | 815K| 2288 (1)| 00:00:28 | | 1 | NESTED LOOPS | | 5254 | 815K| 2288 (1)| 00:00:28 | | 2 | NESTED LOOPS SEMI | | 330 | 44880 | 1627 (0)| 00:00:20 | | 3 | TABLE ACCESS BY INDEX ROWID| ZMKM_INTENT_ORDER | 405 | 39285 | 7 (0)| 00:00:01 | |* 4 | INDEX RANGE SCAN | IDX_ACODE_DFLAG | 405 | | 1 (0)| 00:00:01 | |* 5 | TABLE ACCESS BY INDEX ROWID| ZMKM_ORDER_EXT_VAL | 269 | 10491 | 4 (0)| 00:00:01 | |* 6 | INDEX RANGE SCAN | IDX_ORDER_ID | 16 | | 2 (0)| 00:00:01 | |* 7 | INDEX RANGE SCAN | IDX_ORDER_ID | 16 | 368 | 2 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 4 - access("T"."AREA_CODE"='0516' AND "T"."DEAL_FLAG"=0) 5 - filter("K"."EXT_VAL"='18190044' AND "K"."PARAM_ID"='100007') 6 - access("K"."ORDER_ID"="T"."ORDER_ID") 7 - access("T"."ORDER_ID"="S"."ORDER_ID") 统计信息 ---------------------------------------------------------- 1 recursive calls 0 db block gets 4518 consistent gets 0 physical reads 0 redo size 13485 bytes sent via SQL*Net to client 725 bytes received via SQL*Net from client 25 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 352 rows processed alter session set "_b_tree_bitmap_plans"=false;--- 加入这个后逻辑读减少到 4518。 但是还有其他办法吗?? 答案是有的。 看到有问题的执行计划, 就是在两个索引合中取数据, 那么如果建立组合索引, 把该要的数据全部集中在索引中。 那么就没有必要在两个索引中取数据了。 建立索引 index ( PARAM_ID,EXT_VAL, ORDER_ID); 也就是9万多数据。 应该在7百个逻辑读左右。 结合另一张表访问也是7百个逻辑读。 不过此时hash 。 能控制在 1600 逻辑读左右。 1 适合用sqlprofile 立即绑定执行计划 ,适合线上快速改变执行计划 2 适合实施简单方便, 因为有些时候 DBA和业务是隔开的, 让业务绑定执行计划,反正我是没有去交接过。 不如扔一个建索引语句,说建立一下即可。 --------------------- 作者:越烟 来源:CSDN 原文:https://blog.csdn.net/daiqiulong2/article/details/88824518 版权声明:本文为博主原创文章,转载请附上博文链接!