机器学习
1. 机器学习概念
主要是研究如何使计算机从给定的数据中学习规律,即从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对位置或无法观测的数据进行预测
2. 样本数据
样本数据就是的(x,y),其中x叫做输入数据(input data),y叫做输出数据(output data)或者叫做一个更加专业的名字——标签(label)。通常x和y都是高维矩阵,样本标签y根据需求不同有各种形式:二值型,多值型连续型
3.样本分布
分布(distribution):样本空间的全体样本服从的一种规律
独立同分布(independent and identicallydistributed,简称i,i,d.):获得的每个样本都是独立
地从这个分布上采样获得的
4.特征
特征:对象在某方面的表现或性质的事项
特征向量的作用主要有两个:
降低数据维度:通过提取特征向量,把原始数据的维
度大大较低,简化模型的参数数量。
提升模型性能:一个好的特征,可以提前把原始数据
最关键的部分提取出来,因此可以提高学习机的性能
5.数据集
对于一个学习机而言,不是所有的数据都用于训练学习模型,而是会被分为三个部分:训练数据、交叉验证数据、测试数据。
训练数据(training data):训练数据用于训练学习模型,通常比例
不低于总数据量的一半。
交叉验证数据(cross validation data):用于衡量训练过程中模型
的好坏。
测试数据(testing data):用于衡量最终模型的性能好坏,这也
是模型性能好坏的衡量指标
6.算法分类
机器学习中问题分为4大类:
分类(classification):预测是离散值
二分类(binary classification):只涉及两个类别的分类任务
正类(positive class):二分类里的一个
反类(negative class):二分类里的另外一个
多分类(multi-class classification):涉及多个类别的分类
回归(regression):预测值是连续值
聚类(clustering):把训练集中的对象分为若干组
关联
7.学习任务分类
机器学习分为监督学习和无监督学习。
监督学习(supervised learning):数据附带了要预测的附加属性。从已有数据中发现关系:由多个输入映射一个输出。并用数学模型表示,将新数据用这数学模型运算得到新的输出。
无监督学习(unsupervised learning):将已有数据进行分类:只有输入,没有输出,将输入的数据按照学习到的标准进行分类。
8.预测和泛化
预测(prediction):判断一个东西的属性
泛化(generalization)能力:学得的模型适用于新样本的能力
9.误差与过拟合
误差(error):学习器对样本的实际预测结果与样本的真实值之间的差异
过拟合(overfitting):学习能力过强,以至于把训练样本所包含的不太一般的特性都学到了.
欠拟合(underfitting):学习能太差,训练样本的一般性质尚未学好
10.评估方法
10.1留出法
将数据集D划分为两个互斥的集合,一个作为训练集S,一个作为测试集T,满足D=S∪T且S∩T=∅ ,常见的划分为:大约2/3-4/5的样本用作训练,剩下的用作测试。
需要注意的是:训练/测试集的划分要尽可能保持数据分布的一致性,以避免由于分布的差异引入额外的偏差,常见的做法是采取分层抽样
10.2 交叉验证法
将数据集D划分为k个大小相同的互斥子集,满足D=D1∪D2∪…∪Dk,Di∩Dj=∅ (i≠j),同样地尽可能保持数据分布的一致性,即采用分层抽样的方法获得这些子集。交叉验证法的思想是:每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就有K种训练集/测试集划分的情况,从而可进行k次训练和测试,最终返回k次测试结果的均值。交叉验证法也称“k折交叉验证”,k最常用的取值是10。
10.3自主法
自助法
给定包含m个样本的数据集D,每次随机从D 中挑选一个样本,将其拷贝放入D’,然后再将该样本放回初始数据集D 中,使得该样本在下次采样时仍有可能被采到。重复执行m 次,就可以得到了包含m个样本的数据集D’。可以得知在m次采样中,样本始终不被采到的概率取极限为

11.性能度量
在回归任务中,即预测连续值的问题,最常用的性能度量是“均方误差”MSE
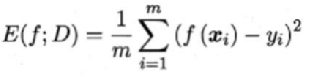
在分类任务中,即预测离散值的问题,最常用的是错误率和精度,错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,易知:错误率+精度=1。

查准率/查全率/F1
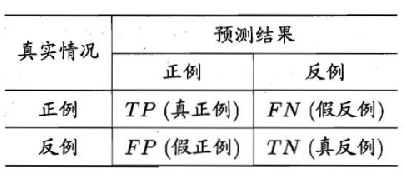

OC与AUC
学习器对测试样本的评估结果一般为一个实值或概率,设定一个阈值,大于阈值为正例,小于阈值为负例,因此这个实值的好坏直接决定了学习器的泛化性能,若将这些实值排序,则排序的好坏决定了学习器的性能高低。
ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC(Receiver Operating Characteristic)曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏.进行模型的性能比较时,若一个学习器A的ROC曲线被
另一个学习器B的ROC曲线完全包住,则称B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。ROC曲线下的面积定义为AUC(Area Under ROC Curve),不同于P-R的是,这里的AUC是可估算的,即AOC曲线下每一个小矩形的面积之和。易知:AUC越大,证明排序的质量越好,AUC为1时,证明所有正例排在了负例的前面,AUC为0时,所有的负例排在了正例的前面
