一、引言
爬取过大众点评的朋友应该会遇到这样的问题,在网页中看起来正常的文字,在其源代码中变成了下面这样:
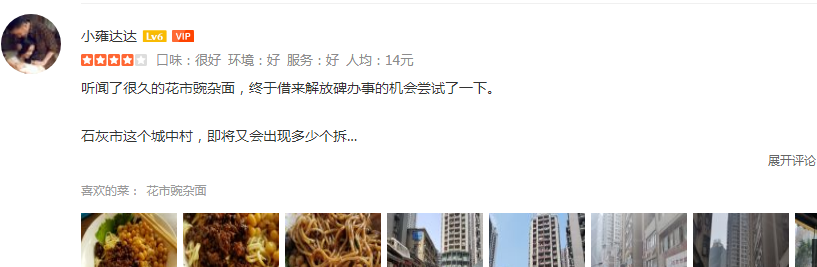

究其原因,是因为大众点评在内容上设置的特别的反爬机制,与某些网站替换底层字体文件不同,大众点评使用随机替换的SVG图片来替换对应位置的汉字内容,使得我们使用常规的手段无法获取其网页中完整的文字内容,经过观察我发现,所有可以被SVG图像替换的文字都保存在下图所示的地址中:
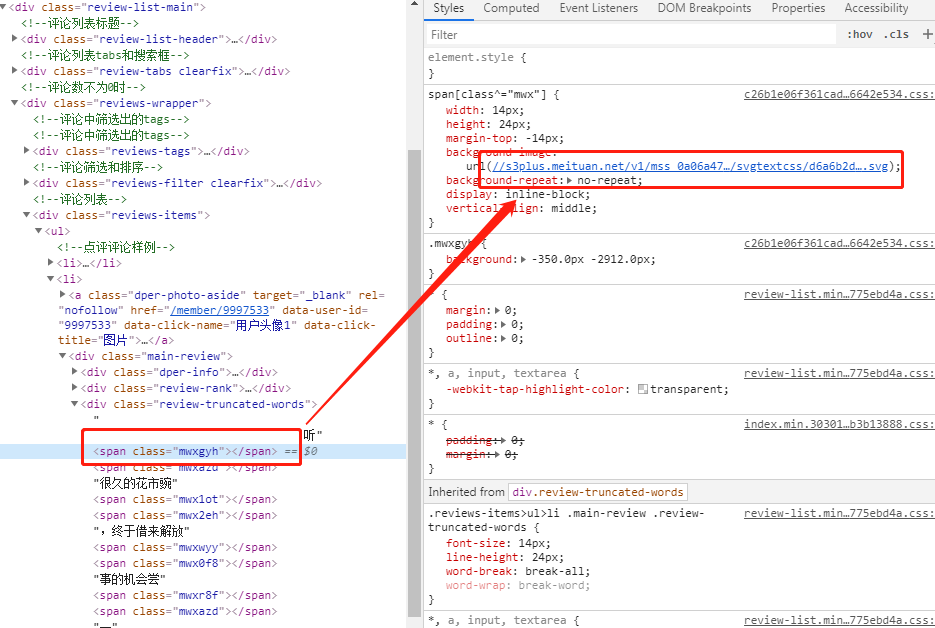
打开该页面后可以发现其包含了所有可以被SVG替换的文字:
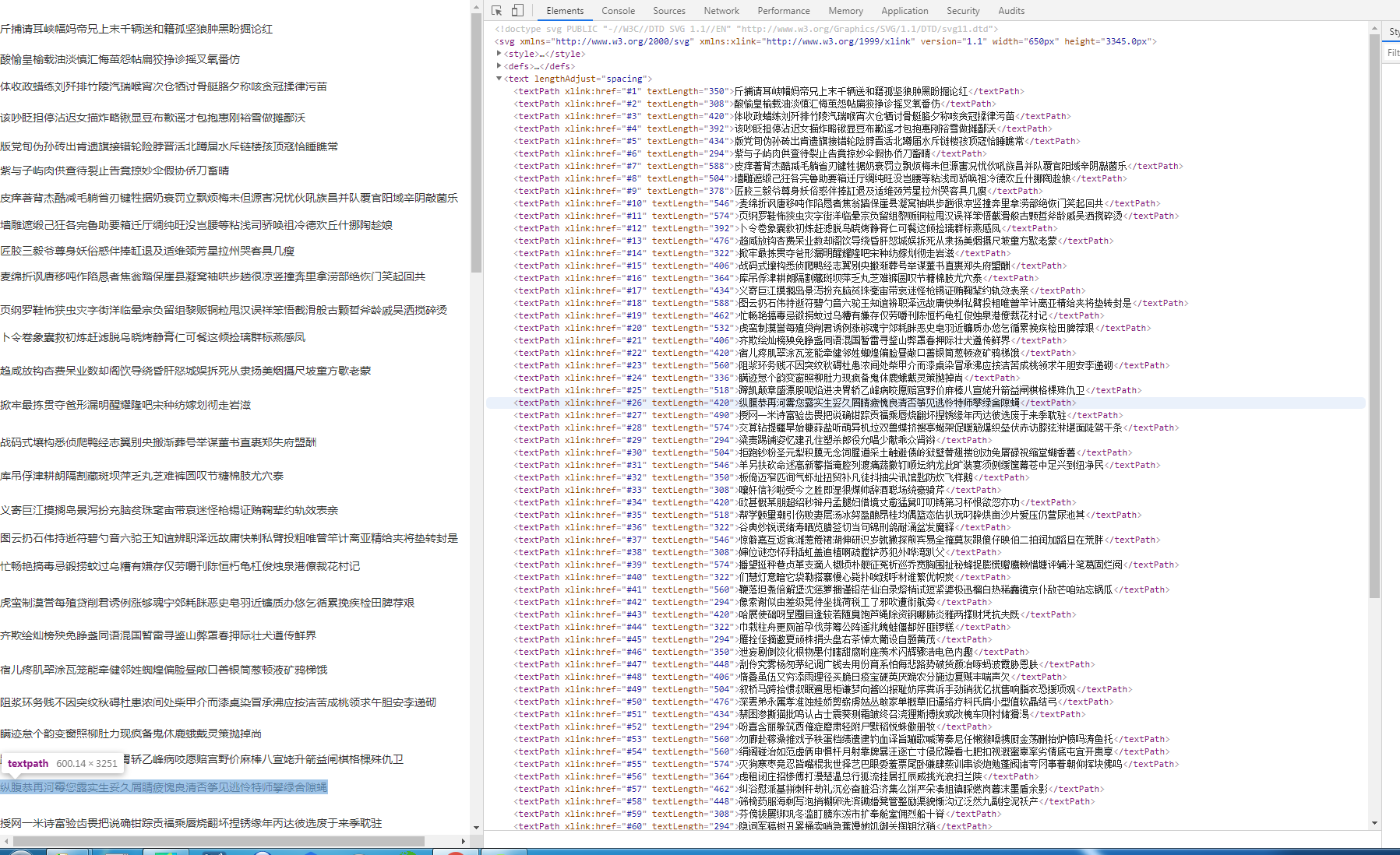
在查阅了他人针对该问题提出的相关文章后,获悉他们使用的方法是先找到源代码中SVG图像对应的<span>标签,其属性class与下图红框中所示第一个以及第二个px值存在一一映射关系,且该关系全量保存在旁边对应的css中:
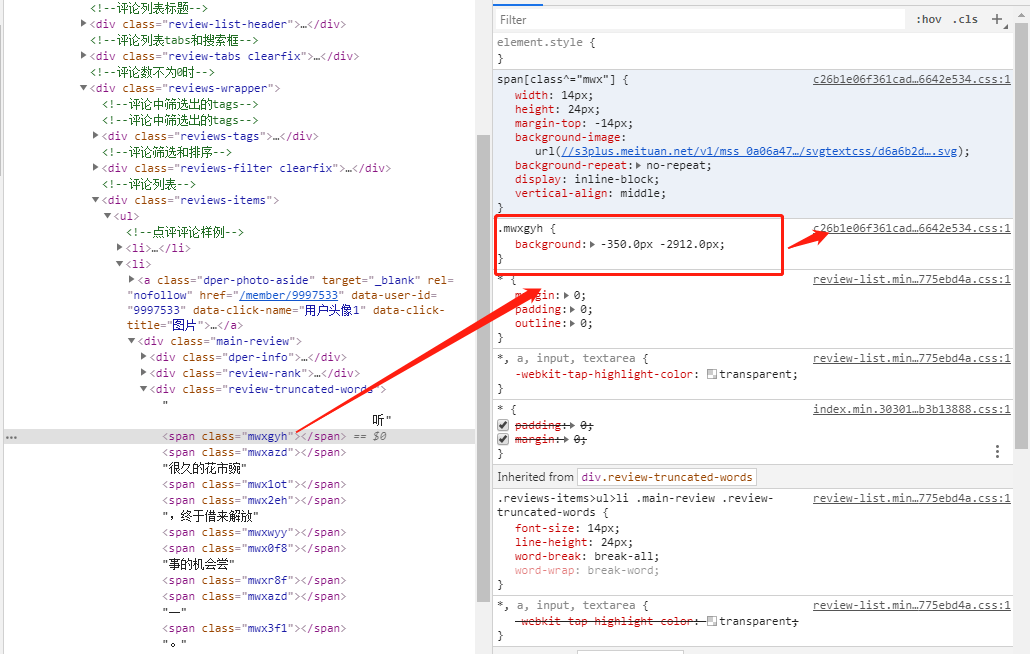
右键该链接,选择open in new tab,在跳转的新页面中便隐藏了全量的class属性与两个对应的px之间的映射关系:

按照前人的经验,这两个px通过一个公式与之前的SVG界面中所有汉字的行列位置构建起一一对应关系,但他们的做法是自己去手动猜测规则,建立公式从而破解从class属性到SVG文字行列位置的一一映射关系,但这样的方式显然已经被大众点评后台人员知晓,于是乎,更变态的是,他们这套映射规则几乎每天都会发生一次更新,至少我在写这篇文章的前一天遇到的情况,与今天所遭遇的情况完全不同,这就使得前人总结的那套靠脑力去猜测的方法吃力不讨好,于是我摒弃了去猜测规则,而是选择去学习规则,即利用机器学习算法来解决这个看起来较为棘手的问题;
二、基于决策树分类器的破解方法
这里我选择使用较为经典的CART分类树来训练算法,从而实现对其映射规则的学习,在训练算法前,我们需要收集适量的样本数据来构造带标签的训练集,从而支撑之后的有监督学习过程;
2.1 收集训练数据
通过观察,我发现大众点评的页面中被SVG替换的文字并不确定,即每一次刷新页面,都可能有新的文字被替换成SVG,旧的SVG图像被还原为文字,借助这个机制,我们可以通过对某一确定的页面多次刷新,每次用正则提取评论内容标签下,所有符合单个汉字格式条件和<span class="xxxxx"></span>格式条件的片段,用下面的正则就可以实现:
'(<span class="[a-z0-9]+">)|([\u4e00-\u9fa5]{1})'
每次将符合上述任一条件的一个片段按照其在整段文字中出现的顺序拼接起来,构造位置一一对应的编码列表和文字列表,并在重复的页面刷新过程中,通过识别从SVG图像恢复成普通文字的现象,得到汉字与其class编码的一一对应关系,再将这些已证实对应关系的汉字-编码作为我们构造训练集的基础,自变量为通过该文字编码在CSS页面中索引到的两个px值(用正则即可轻松实现),因变量为该文字在SVG页面中对应的行列位置,因为每行的文字数量不太一致,所以这里需要写一个简单的算法从SVG页面源代码中抽取每个汉字的行列位置并保存起来,以上步骤我的代码实现如下,这里为了跳过模拟登陆,我选择了在本地Chrome浏览器登录自己的大众点评账号并保持登录,再利用selenium来挂载本地浏览器配置文件,从而达到自动登录的目的:
def OfferLocalBrowser(headless=False):
'''
这个函数用于提供自动登录大众点评的Chrome浏览器
:param headless: 是否使用无头Chrome
:return: 返回浏览器对象
'''
option = webdriver.ChromeOptions()
option.add_argument(r'user-data-dir=C:\Users\hp\AppData\Local\Google\Chrome\User Data')
if headless:
option.add_argument('--headless')
browser = webdriver.Chrome(options=option)
return browser
def CollectDataset(targetUrl,low=3,high=6,page=3,refreshTime=3): ''' :param targetUrl: 传入可翻页的任意商铺评论页面地址 :param low: 设置随机睡眠防ban的随机整数下限 :param high: 设置随机睡眠防ban的随机整数上限 :param page: 设置最大翻页次数 :param refreshTime: 设置每个页面重复刷新的时间 :return: 返回收集到的汉字列表和编码列表 ''' '''初始化用于存放所有采集到的样本词和对应的样本词编码的列表,CL用于存放所有编码,WL用于存放所有词,二者顺序一一对应''' CL,WL = [],[] browser = OfferLocalBrowser(headless=False) for p in tqdm(range(1,page+1)): for r in range(refreshTime): '''访问目标网页''' html = browser.get(url=targetUrl.format(p)) if '3s 未完成验证,请重试。' in str(browser.page_source): ii = input() '''将原始网页内容解码''' html = browser.page_source '''解析网页内容''' obj = BeautifulSoup(html,'lxml') '''提取评论部分内容以方便之后对评论汉字和SVG图像对应编码的提取''' raw_comment = obj.find_all('div',{'class':'review-words Hide'}) '''初始化列表容器以有顺序地存放符合汉字或SVG标签格式的内容''' base_Comment = [] '''利用正则提取符合汉字内容规则的元素''' firstList = re.findall('(<span class="[a-z0-9]+">)|([\u4e00-\u9fa5]{1})',str(raw_comment)) '''构造该页面中长度守恒的评论片段列表''' actualList = [] '''按顺序将所有汉字片段和<span>标签片段拼接在一起''' for i in range(len(firstList)): for j in range(2): if firstList[i][j] != '': actualList.append(firstList[i][j]) '''打印当前界面所有评论片段的长度''' print(len(actualList)) '''在每个页面的第一次访问时初始化汉字列表和编码列表''' if r == 0: wordList = ['' for i in range(len(actualList))] codeList = ['' for i in range(len(actualList))] '''将actualList中粗糙的<span>片段清洗成纯粹的编码片段,汉字部分则原封不定保留,并分别更新wordList和codeList''' for index in range(len(actualList)): if '<' in actualList[index]: codeList[index] = re.findall('class="([a-z0-9]+)"',actualList[index])[0] else: wordList[index] = actualList[index] '''随机睡眠防ban''' time.sleep(np.random.randint(low,high)) '''将结束重复采集的当前页面中发现的所有汉字-编码对应规则列表与先前的规则列表合并''' CL.extend(codeList) WL.extend(wordList) print('总列表长度:{}'.format(len(CL))) browser.quit() return WL,CL
2.2 数据预处理
通过上面的步骤我们已经得到朴素的汉字-编码样本,接下来我们将其与SVG页面内容和CSS页面内容串联起来,从而构造能够输入决策树分类器进行训练的数据形式,这部分的主要代码如下,因为在最开始我并没有确定因变量到底是哪几个,于是下面的代码中我采集了SVG页面中每个文字的行下标,列下标,所在标签的textLength属性值,所在行的字符个数(虽然后面证明后两个属性是我多想了
-_-!):
def CreateXandY(wordList,codeList,cssUrl,SvgUrl): ''' 这个函数用于传入朴素的汉字列表、编码列表、CSS页面地址,SVG页面地址来输出规整的numpy多维数组格式的自变量X,以及标签Y :param wordList: 汉字列表 :param codeList: 编码列表 :param cssUrl: CSS页面地址 :param SvgUrl: SVG页面地址 :return: 返回自变量X,因变量Y ''' def GetSvgWordIpx(SvgUrl=SvgUrl): ''' 这个函数用于爬取SVG页面,并返回所需内容 :param SvgUrl: SVG页面地址 :return: 单个汉字为键,上面所列四个属性为汉字键对应嵌套的字典中对应值的字典文件 ''' '''访问SVG页面''' SvgWord = requests.get(SvgUrl).content.decode() '''初始化汉字-候选因变量字典''' Svg2Label = {} '''提取SVG页面中所有汉字所在的text标签内容列表,每个列表对应页面中一行文字''' rawList = re.findall('(<textPath xlink:href="#[0-9]+" textLength="[0-9]+">.*?</textPath>)', SvgWord) '''抽取每个汉字及其对应的四个候选因变量''' for row in range(len(rawList)): wordPreList = re.findall('[\u4e00-\u9fa5]{1}', rawList[row]) for word in wordPreList: Svg2Label[word] = { 'RowIndex': [], 'ColIndex': [], 'textLength': [], 'Nchar': [] } Svg2Label[word]['RowIndex'] = row + 1 Svg2Label[word]['ColIndex'] = wordPreList.index(word) + 1 Svg2Label[word]['textLength'] = int(re.search('textLength="(.*?)"', rawList[row]).group(1)) Svg2Label[word]['Nchar'] = len(wordPreList) return Svg2Label '''访问CSS页面''' CodeWithIpx = requests.get(cssUrl).content.decode() '''初始化编码-px值字典''' code2ipx = {} '''初始化针对样本数据的编码-汉字字典''' code2word = {} '''从样本中抽取采集到的确切的汉字-编码关系''' for code, word in tqdm(zip(codeList, wordList)): if code != '' and word != '': code2ipx[code] = re.search( '.%s{background:-(.*?).0px -(.*?).0px;}' % code, CodeWithIpx).groups() code2word[code] = word Svg2Label = GetSvgWordIpx() '''生成自变量和因变量''' X = [] for key, value in code2ipx.items(): X.append([int(value[0]), int(value[1])]) X = np.array(X) Y = [] for key, value in code2ipx.items(): Y.append([Svg2Label[code2word[key]]['ColIndex'], Svg2Label[code2word[key]]['Nchar'], Svg2Label[code2word[key]]['RowIndex'], Svg2Label[code2word[key]]['textLength']]) Y = np.array(Y) return X,Y,Svg2Label,CodeWithIpx
2.3 训练决策树分类模型
通过上面的工作,我们成功构造出规整的训练集,考虑到需要学习到的映射关系较为简单,我们分别构造因变量为行下标、因变量为列下标的模型,并直接用全部数据进行训练(最开始我有想过过拟合的问题,但后面发现这里的映射规则非常简单,甚至可能是线性的,因此这里直接这样虽然显得不严谨,但经过后续测试发现这种方式最为简单高效),具体代码如下:
def GetModels(X,Y): ''' :param X: 因变量 :param Y: 自变量 :return: 用于预测行下标的模型1和预测列下标的模型2 ''' if 'model1.m' not in os.listdir(): '''这个模型的因变量为对应汉字的行下标''' model1 = DecisionTreeClassifier().fit(X, Y[:, 2]) '''这个模型的因变量是对应汉字的列下标''' model2 = DecisionTreeClassifier().fit(X, Y[:, 0]) '''本地持久化保存训练好的模型''' joblib.dump(model1,'model1.m') joblib.dump(model2,'model2.m') else: model1,model2 = joblib.load('model1.m'),joblib.load('model2.m') return model1,model2
接下来我们来写用于挂载模型并对汉字和SVG标签混杂格式的字符串进行预测解码的函数:
def Translate(s,baseDF,model1,model2): ''' 这个函数用于对汉字和SVG标签格式混杂的字符串进行预测解码 :param s: 待解码的字符串 :param baseDF: 存放所有汉字与其行列下标的数据框 :param model1: 模型1 :param model2: 模型2 :return: 预测解码结果 ''' result = '' for ele in s: for u in range(2): if ele[u] != '' and '<' in ele[u]: row_ = model1.predict(np.array( [int(re.search('.%s{background:-(.*?).0px -(.*?).0px;}' % re.search('<span class="([a-z0-9]+)">',ele[u]).group(1), CodeWithIpx).groups()[i]) for i in range(2)]).reshape(1, -1)) col_ = model2.predict(np.array( [int(re.search('.%s{background:-(.*?).0px -(.*?).0px;}' % re.search('<span class="([a-z0-9]+)">',ele[u]).group(1), CodeWithIpx).groups()[i]) for i in range(2)]).reshape(1, -1)) answer = baseDF['字符'][(baseDF['Row'] == row_.tolist()[0]) & (baseDF['Col'] == col_.tolist()[0])].tolist()[0] result += answer else: result += ele[u] return result
其中baseDF是利用之前从SVG页面抽取的字典中得到的字符串,格式如下:
baseDF = pd.DataFrame({'字符': [key for key in Svg2Label.keys()],
'Row': [Svg2Label[key]['RowIndex'] for key in Svg2Label.keys()],
'Col': [Svg2Label[key]['ColIndex'] for key in Svg2Label.keys()]})
至此,我们所有需要的功能都以模块化的方式编写完成,下面我们来对任意挑选的页面进行测试;
2.4 测试
这里我们挑选某火锅店的前三页评论,每个页面重复刷新三次,用于采集训练数据,并在某生鲜店铺任选的某页评论上进行测试,代码如下:
'''测试''' wordList,codeList = CollectDataset(targetUrl = 'http://www.dianping.com/shop/72452707/review_all/p{}?queryType=sortType&queryVal=latest', low = 3, high = 6, page = 3, refreshTime = 3) X,Y,Svg2Label,CodeWithIpx = CreateXandY(wordList=wordList,codeList=codeList, cssUrl = 'http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/c26b1e06f361cadaa823f1b76642e534.css', SvgUrl = 'http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/d6a6b2d601063fb185d7b89931259d79.svg') model1,model2 = GetModels(X,Y) browser = OfferLocalBrowser() browser.get('http://www.dianping.com/shop/124475710/review_all?queryType=sortType&&queryVal=latest') obj = BeautifulSoup(browser.page_source,'lxml') rawCommentList = obj.find_all('div',{'class':'review-words'}) baseDF = pd.DataFrame({'字符': [key for key in Svg2Label.keys()], 'Row': [Svg2Label[key]['RowIndex'] for key in Svg2Label.keys()], 'Col': [Svg2Label[key]['ColIndex'] for key in Svg2Label.keys()]}) for i in range(len(rawCommentList)): s = re.findall('(<span class="[a-z0-9]+">)|([\u4e00-\u9fa5]{1})',str(rawCommentList[i])) print(Translate(s,baseDF,model1,model2))
解码效果如下,我特意选择在与火锅店评论相差很远的生鲜类店铺下进行测试,以避免潜在的过拟合现象干扰,测试效果如下,从而证明了我们的分类器在对规则学习上的成功(大众点评的朋友们该更新加密算法了)
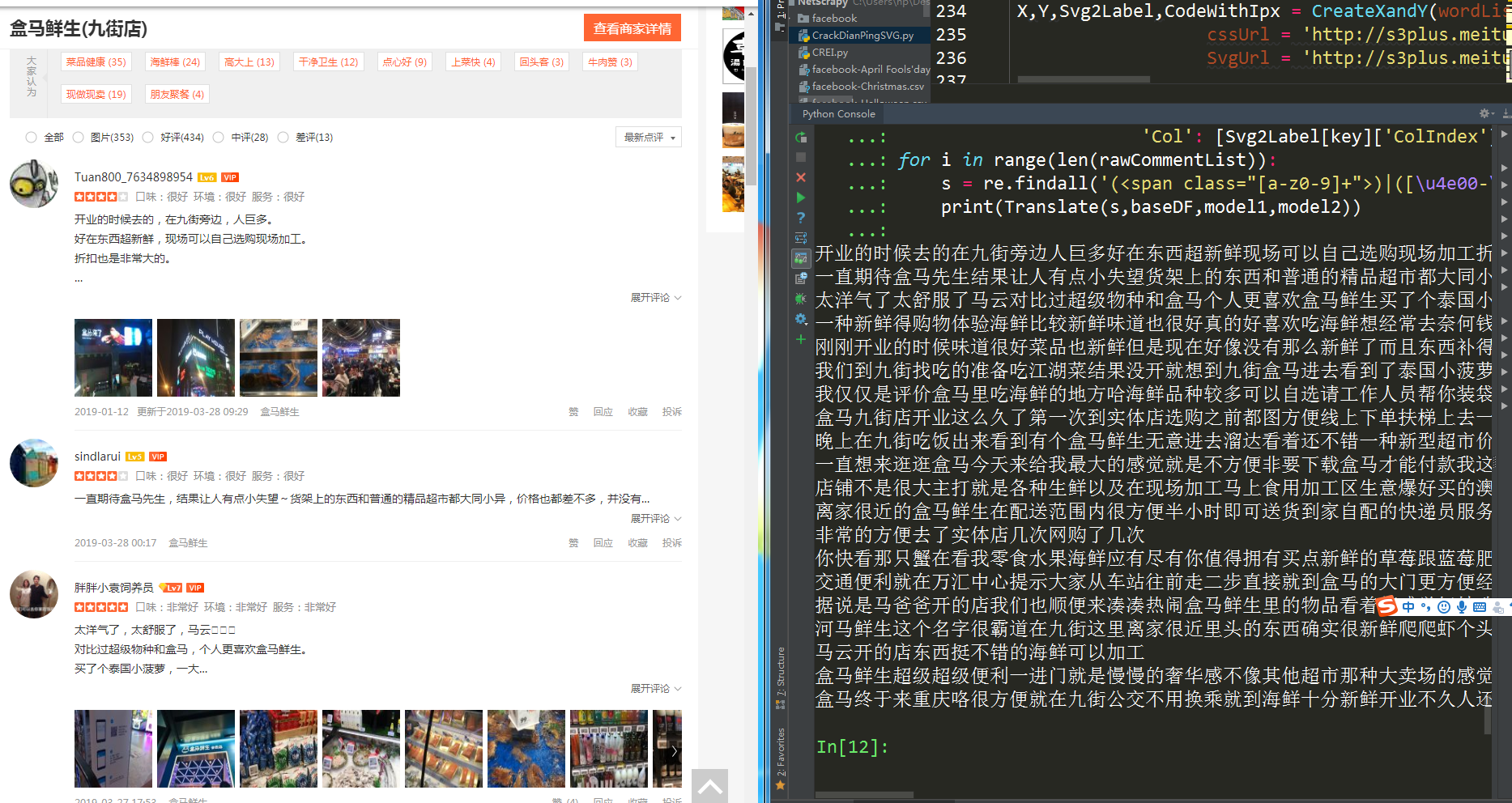
以上就是本文全部内容,如有疑问欢迎评论区讨论,本文由博客园费弗里原创,首发于博客园,转载请注明出处。