Receptive Field Block Net for Accurate and Fast Object Detection
论文地址:https://arxiv.org/abs/1711.07767
代码地址:https://github.com/ruinmessi/RFBNet
Abstract
目前领先的目标检测器都以CNN为网络主干结构,例如ResNet-101 和 Inception,深度网络在特征表现上很强大,但是计算成本很高。相反,一些轻量级检测器能完成实时处理任务,但是准确率稍差。这篇论文中,我们利用人工机制增强轻量级特征,尝试构建一个快速而准确的检测器。受人类视觉系统中感受野(Receptive Fields)的结构启发,我们提出了一个新的 RF Block(RFB) 模块,它将感受野的大小和离心率(eccentricity)纳入考虑范畴,增强特征的可区分性和鲁棒性。我们进一步将 RFB 和 SSD 组合在一起,构建 RFB Net 检测器。为了证明它的效率,实验主要在2个 benchmarks 进行测试,结果显示 RFB Net 能够超过目前最优秀的检测器,并能保持实时的速度。
1. Introduction
近些年来,Region-based CNN(R-CNN)以及它的衍生模型,如Fast R-CNN 和 Faster R-CNN,极大地提升了各种目标检测领域 benchmarks 和比赛上的成绩,如 Pascal VOC,MS COCO,和 ILSVRC。它们将检测问题分为2个阶段,第一阶段提出图片上的候选框,第二阶段则对每个候选框根据CNN深度特征进行分类。在这些方法中,CNN 角色至关重要,它学到的特征具有高度的可区分性,而且对物体位置的变动具有很好的鲁棒性。ResNet, Inception, Mask R-CNN, FPN等方法利用优化的特征来获得更好的结果,但是这些特征的计算成本都很高,这样推理的速度就会很慢。
为了加快检测速度,单阶段框架开始被提出来,其中不再包括目标候选框生成部分。尽管 YOLO 和 SSD 都说能达到实时效果,但是都牺牲了准确率,和 state of art 的双阶段方法比都掉了10%-40%的准确率。最近,Deconvolutional SSD (DSSD) 和 RetinaNet 的提出极大地改善了精度得分,可以和双阶段检测器一较高下。但是,它们的性能提升基本来自于很深的 ResNet-101模型,这就降低了它的效率。
要建一个快速而精确的检测器,一个合理的方法应该是增强轻量级网络的特征表现力,利用一定的人工机制,而不是一味地增加网络深度。另一方面,神经科学领域的发现显示,在人类的视皮层上,population Receptive Field (pRF) 的大小和它在视网膜上的位置有函数关系,如图1所示。它强调了中心附近区域的重要性,对不明显的空间移动不再那么敏感。一些较浅的模型很巧合地利用了这个机制来设计和学习池化层,表现都不错。

目前的深度学习模型,通常将感受野设为一样的大小,这可能会降低特征的可区分性以及鲁棒性。Inception 使用了不同大小的感受野,通过多个分支,不同卷积核的CNNs来实现了这个想法。它的衍生模型在目标检测(双阶段框架)和分类任务上取得优异的成绩。但是,Inception 所有的卷积核都是在同一个中心点采样。
受人类视觉系统中感受野的启发,这篇论文提出了一个新的模块,Receptive Field Block(RFB),来增强轻量级CNN 学到的特征,以此提升检测器的速度和精度。引入 RFB 的出发点通过模拟人类视觉的感受野加强网络的特征提取能力,在结构上 RFB 借鉴了Inception的思想,主要是在 Inception 的基础上加入了膨胀卷积层(dilated convolution),从而有效增大了感受野(receptive field)。尤其,RFB 利用多分支的池化操作,对不同大小的感受野有不同的卷积核,使用膨胀卷积层(dilated Conv layer)来控制离心率,对它们进行变形操作,进而产生最终的结果。我们然后将 RFB 模块加在 SSD 上(一个实时的轻量级主干结构),然后构建一个更先进的单阶段检测器(RFB Net)。由于这样的一个简单的模块,RFB Net 的性能能和目标最优秀的检测器相比较,而且速度更快。此外, RFB 模块更加地通用,对网络结构的约束很少。
这篇论文的主要贡献如下:
- 提出了RFB 模块来模拟人类视觉系统中的感受野的功能,目的增强轻量网络的深度特征。
- 构建出 RFB Net 检测器,将 SSD 最顶层的卷积层替换为 RFB,提升是明显的,而且计算成本被控制的很好;
- 证明 RFB Net 在 Pascal VOC 和 MS COCO 上获得 state of art 的成绩,而且速度是实时的,然后还将它和 MobileNet 连接起来,证明了 RFB 的通用性能。

图中虚线部分就是 RFB 结构。RFB结构主要有2个特点:

- 不同尺寸卷积核的卷积层构成的多分支结构,这部分可以参考 Inception 结构。用不同大小的圆形表示不同尺寸卷积核的卷积层。
- 引入膨胀卷积层,膨胀卷积层之前应用在分割算法 DeepLab 中,主要作用是增加感受野,和 Deformable 卷积有异曲同工之妙。在图中 RFB 结构用不同的 rate 表示膨胀卷积层的参数。在 RFB 结构最后会将不同尺寸和 rate 的卷积层输出进行 concatenate,达到融合不同特征的目的。在上图中,RFB结构用3种不同大小和颜色的输出叠加来展示。
在上图的最后一列,将融合后的特征与人类视觉感受野做对比,从图可以看出是非常接近的,这也是这篇论文的出发点,换句话说就是模拟人类视觉感受野进行 RFB 结构的设计。
2. Related Work
双阶段检测器: R-CNN 将候选框选取步骤(如 Selective Search)和分类步骤(通过CNN模型)直接结合起来,获得了很大的精度提升,开启了目标检测领域的深度学习时代。它的衍生模型又改进了双阶段框架,获得了业内领先的成绩。此外,一众的扩展版本进一步提升了检测准确率,如R-FCN和FPN,以及 Mask R-CNN。
**单阶段检测器:**最具代表性的单阶段检测器有YOLO 和 SSD。它们在整张特征图上预测多个目标的置信度和位置。这两个检测器采用轻量级的主干网络来加速,但是它们的精度和双阶段模型比,明显差不少。
最近,绝大多数的单阶段检测器(SSD,RetinaNet)都用 ResNet-101 代替之前的轻量级主干网络,并运用了一些特殊的技巧,如 deconvolution, 和 Focal Loss,这使得它们的成绩甚至能超过双阶段方法。但是,这极大地牺牲了它们在速度上的优势。
感受野: 我们的目标是提升高速度,单阶段检测器的性能,而且不会带来太多计算成本。因此,我们没有使用很深的主干网络,而是使用 RFB,模拟人类视觉系统中的感受野机制,来增强轻量模型的特征表现力。
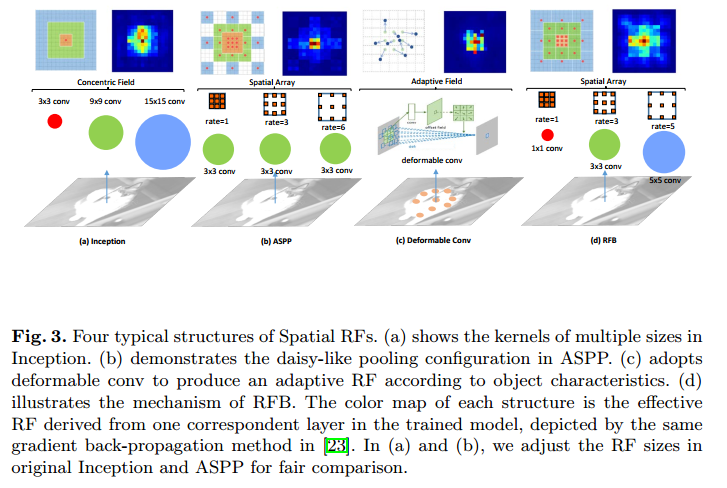
RFB 实际上和 Inception block 及 ASPP 方法不同,它强调感受野大小和离心率之间的关系,较大的权值被赋给中心附近的位置,表明它们比远处位置的更重要。图3提供了4个常用的空间感受野结构。
3. Method
在这一部分,我们将重新了解下人类的视觉皮层,引入我们的 RFB 单元,介绍如何模拟这样一个机制,然后描述 RFB Net 检测器的结构以及训练/测试框架。
3.1 Visual Cortex Revisit
在过去的几十年中,通过核磁共振(fMRI)非侵入性地测量人类大脑活动已经实现,感受野模型也已成为一个重要的科学工具,用于预测人脑的反应和了解大脑的工作原理。因为人脑科学仪器经常观测到许多神经元的池化响应,这些模型因此通常被叫做pRF模型。基于fMRI和pRF模型,检测大脑皮层中诸多 visual field maps 之间的关系也就成为了可能。在每个皮层 map,研究人员发现 pRF 的大小和离心率是正相关的,而相关的系数在不同的 visual field maps 上变动的,如图1所示。
3.2 Receptive Field Block
RFB 是一个多分支的卷积模块。它的内部结构能被分为两个部分:拥有不同卷积核的多分支卷积层,和后面的膨胀池化或卷积层。前部分和 Inception 中的结构一致,负责模拟多个大小的 pRFs;后半部分产生人类视觉系统中 pRF 大小和离心率之间的关系。图2 是关于 RFB 和它对应的空间池化区域图。
Multi-branch convolution layer
根据CNN中感受野的定义,它很简单且很自然地运用不同的核来获得多个大小的感受野,这与固定大小感受野相比应该是要结果更优的。
我们采用 Inception 家族中最新的版本,即 Inception V4 和 Inception-ResNet V2。
- 首先,我们在每个分支中使用 bottleneck 结构,它由一个 的卷积层构成,降低特征图的通道数,再加一个 的卷积层。
- 其次,我们替换 的卷积层为两个摞在一起的 的卷积层,降低参数的个数以及较深的非线性层的个数。
- 同样的原因,我们使用一个 和一个 的卷积层来代替原来的 卷积层。
- 最终,我们使用了 ResNet 中的 shortcut 结构和 Inception-ResNet V2。
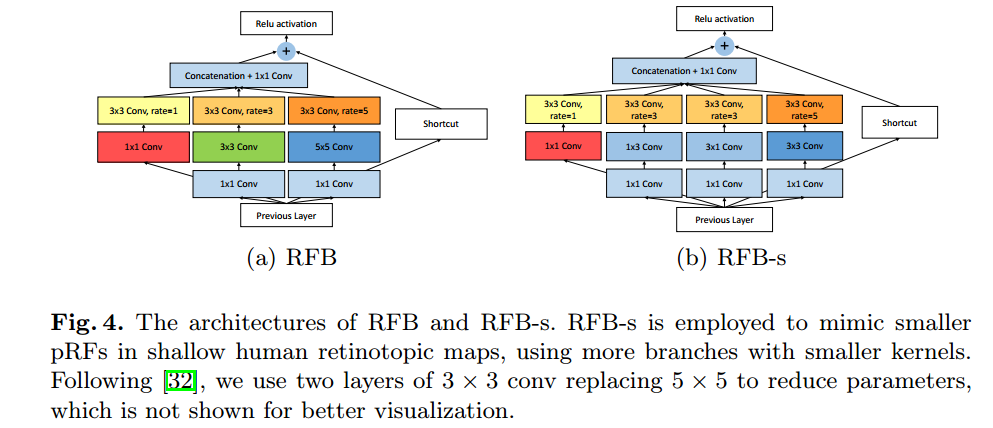
上图是两种 RFB 的结构示意图。
(a) 是 RFB,整体结构上借鉴了 Inception 的思想,主要不同点在于引入了3个膨胀卷积层(如 ),这也是这篇文章增大感受野的方式之一。
(b) 是 RFB-s。RFB-s 和 RFB 相比有2个改进。一方面用 卷积层代替 卷积层,另一方面用 和 代替 卷积层,主要目的是减少计算量,类似 Inception 后期版本对 Inception 结构的改进。
Dilated pooling or convolution layer
这个概念原来由 Deeplab 提出,也被叫做带洞卷积层(atrous convolution layer)。这个结构基本的目的是产生一个高分辨率的特征图,在一个更大的区域获取信息,但也能保持同样的参数个数。这个设计在语义分割任务上被证明是有效的,在一些优秀的目标识别检测器上也有使用来提升速度和精度,如 SSD 和 R-FCN。
在这篇论文中,我们利用膨胀卷积来模拟视觉皮层上 pRFs 离心率的影响。图4 是两个多分支卷积层和膨胀池化/卷积层的结合形式。在每个分支,有特定大小卷积核的卷积层的后面,跟着一个有着膨胀操作的池化或卷积层。卷积核大小和膨胀操作是正相关的,正如视觉皮层中的 pRFs 大小和离心率。最终,所有分支的特征图被连接起来,变为一个空间池化或卷积数组,如图1所示。
RFB 中的特定参数,如核的大小,每个分支的膨胀,以及分支的个数,在每个检测器内,在每个位置上都些微地不同。
3.3 RFB Net Detection Architecture
RFB Net 检测器使用了SSD中的多比例和单阶段框架,RFB 模块嵌在里面用于改善从轻量主干网络中提取的特征,这样检测器既有速度也有精度。由于 RFB 很容易被整合入CNNs,我们可以继续使用 SSD 架构。最主要的改变就是,将最顶层的卷积层替换为 RFB。另一些较小的变动在图5中显示。
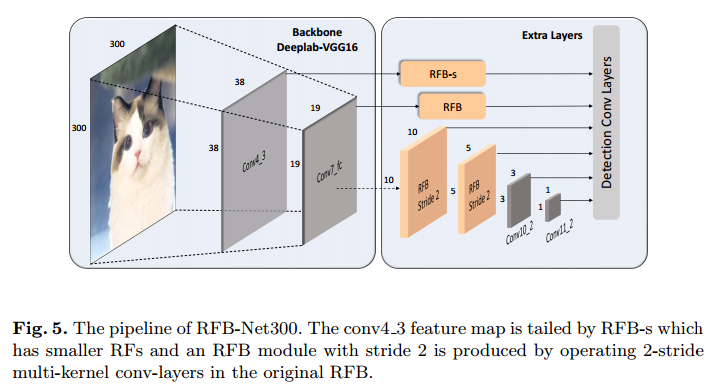
上图是 RFB-Net300 的整体结构示意图,基本和 SSD 类似,不同的是:
- 主干网上用两个 RFB 结构替换原来的新增的两层。
- 和 在接预测层之前分别接 RFB-s 和 RFB 结构,这两个结构的示意图如前面的图4所示。
Lightweight backbone
我们使用和 SSD 中完全一样的主干网络。该主干网络就是一个 VGG16,在 ILSVRC CLS-LOC 数据集上进行的预训练,它的 fc6 和 fc7 层被转换为有下采样参数的卷积层,它的 pool5 层由 变为 。膨胀卷积层被用于填充空洞,移除所有的 dropout 层和 fc8 层。尽管有许多轻量网络最近被提出来,如 DarkNet, MobileNet, ShuffleNet,我们仍然使用这个主干网络,来和原来的 SSD 进行直观的比较。
RFB on multi-scale feature maps
在原来的 SSD 中,基网络后面跟着一组级联卷积层,来产生一系列的特征图,这些特征图的空间分辨率是逐渐降低的,而视野是逐渐增大的。在我们的实现中,我们保留了 SSD 的级联结构,但是前面的卷积层(它的特征图有着相对较大的分辨率)被替换为 RFB 模块。在 RFB 中,我们使用一个单一的结构来模拟离心率的作用。因为 pRFs 的大小和离心率的比率在视觉图之间互不相同,我们因此调整 RFB 的参数来产生一个 RFB-s 模块,它模拟浅层视网膜上较小的 pRFs,将它放在 特征后面,如图4和图5所示。最后一些的卷积层被保留下来,因为它们特征图的分辨率太小了,没法使用大卷积核( )滤波器。
3.4 Training Settings
我们基于 Pytorch 框架实现 RFB Net 检测器,利用了 ssd.pytorch 库提供的开源架构中的多个部分。我们的训练策略延续了 SSD,包括数据增广,困难样本挖掘(hard example mining),默认边框的比例和纵横比,以及损失函数(定位的 smooth L1 损失和分类的 softmax 损失),我们小幅度地改了学习率来更好地适应 RFB。更多的细节将在下面的实验部分给出。所有新的卷积层都用 MSRA 方法初始化。
4. Experiments
Pls read paper for more details.