thrift环境准备
hbase是接口API是java的,如果需要通过python来操作的话,可以使用thrift服务。使用thrift需要部署thrift接口服务和thrift客户端环境,thrift负责将操作请求翻译后调用Java API操作,客户端thrift负责序列化请求后传输。示意如下:
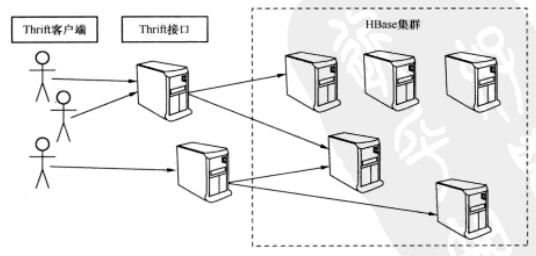
客户端和接口可以装在同一台机器上,也可以接口单独部署成接口服务集群,需要访问时客户机上安装个thrift客户端即可,常用的两种架构如下(参考文章):
集群模式——性能和可靠性好,线上服务最好这样部署
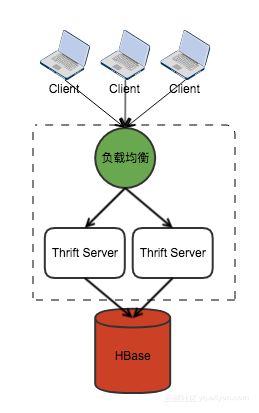
本地模式——比较灵活,数据分析自行开启thrift服务可采用这种方式
默认hbase thrift接口服务端口号9090,可在配置文件conf/hbase-site.xml中查看和修改thrift 接口服务的 IP 地址和端口号,如下
<property>
<name>hbase.master.hostname</name>
<value>$thriftIP</value>
</property>
<property>
<name>hbase.regionserver.thrift.port</name>
<value>$port</value>
</property>
开启接口服务很简单,直接运行如下指令
hbase/bin/hbase-daemon.sh start thrift1
客户端环境准备如下:
- 安装thrift,mac和windows可直接安装,linux下需要编译,[参考]
- 安装python操作thrift库,如下
pip install thrift
- 安装python操作hbase库
注意这个很重要,网上教程很多要求如下安装
pip install hbase-thrift
这个虽然能操作,但是这个库还是2010更新的,很多新特性都不支持,最好方法是找到当前安装hbase2.0的环境,找到如下文件hbase/lib/hbase-thrift-2.*.jar,解压后,如下目录,取出thrift/Hbase.thrift文件,这是thrift的IDL定义文件,如下生成python hbase操作库
thrift -gen py ./Hbase.thrift
当前目录下gen-py中hbase目录拷贝出来即为python连接hbase库。这个方法能保证python hbase库始终是和当前版本最匹配的。
如果不想这么麻烦,直接使用附件代码中已经编译好的hbase库也可,只是如果要使用最新的hbase python接口还是需要自己生成的。

连接
遵循python thrift标准连接方法如下:
from thrift.transport import TSocket,TTransport
from thrift.protocol import TBinaryProtocol
from hbase import Hbase
from hbase.ttypes import TScan
# thrift默认端口是9090
socket = TSocket.TSocket('10.202.209.72',9090)
socket.setTimeout(5000)
transport = TTransport.TBufferedTransport(socket)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
transport.open()
# do something
transport.close()
查询
最新python 支持多行和当行查询,满足大多数需求,如下:
# 获取表名列表
print client.getTableNames()
# 获取指定rowkey指定列族信息
ts = client.get('table1', 'row_key1', 'c1', None)
for t in ts:
print t.value
# 获取指定rowkey全部信息
rows = client.getRow('table1', 'row_key1', None)
for row in rows:
for k,v in row.columns.items():
print "%s=>%s" %(k.split(':')[1], v.value)
rows = client.getRows('table1', ['row_key1', 'row_key2'], None)
for row in rows:
for k,v in row.columns.items():
print "%s=>%s" %(k.split(':')[1], v.value)
扫描
对于复杂查询或分页等需求需要通过扫描实现,如下
# 指定开始和结束row_key扫描
sid = client.scannerOpenWithStop('table1', b'000', b'002', ['c1'], None)
res = client.scannerGetList(sid, 10)
print res
client.scannerClose(sid)
# 指定filter扫描
s = TScan()
s.filterString = "(PrefixFilter ('000') AND (QualifierFilter (=, 'binary:m')))"
sid = client.scannerOpenWithScan('table1', s, None)
res = client.scannerGetList(sid, 10)
print res
client.scannerClose(sid)
第一个指定开始和结束row_key扫描,第二个指定filter来扫描,python hbase库没有对应函数实现传入filter参数的功能,必须通过这种迂回的方式。sid对应的scanner标记通过scannerGet获取全部结构,scannerGetList获取指定条记录。
源码下载
演示源码下载链接
本文只演示了查询,其他操作可参考腾讯文档
原创,转载请注明来自