-
为什么要使用spark
-spark到目前为止没有竞争对手 -
为什么要用到大数据?
-文件超级大,一块硬盘放不下,—>hdfs上场;(存储问题)
-僵尸数据:(数据存储到一个位置得用起来);(CPU+内存来完成计算);多机一块运算(MapReduce)
-mr的开发流程特别繁琐;hive --> sql语句 --> 会转换成 mr 代码 --> hadoop中的 mr 和 hdfs 运行;
-hive动不动起 mr ,会超级的慢 ; —> presto – lmpala
-presto的缺点:支持的SQL语句不全,
-Hbase:crud特别快,rowkey:最多只能存储64KB,hbase启动的时候会一次把rowkey加载到内存中(如果rowkey存储的过多,内存放不下);column faimly:列族无上限存储到hdfs中
-所有所有的缺点都交给spark解决;spark吸收到我们之前所学框架的所有优点,并且弥补了不足
-spark:就是一个软件站(一堆软件的功能合并到了一起);就hdfs木有实现,
- 介绍
-官网:http://spark.apache.org/
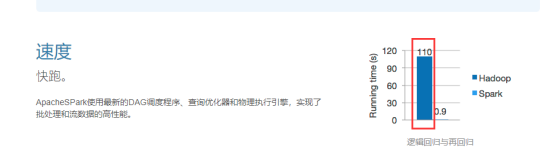
-Spark:闪电式的统一的分析引擎;是一个统一的大型数据处理引擎.

-下载:
下载网址:http://mirrors.ustc.edu.cn/apache/spark/spark-2.4.0/


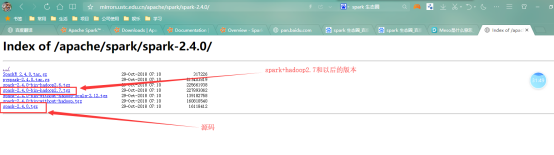


-老版本如何下载


Spark2.4需要的版本是:运行在Java 8+、Python2.7+/3.4+和R3.1+上
- 架构图
- 高可用
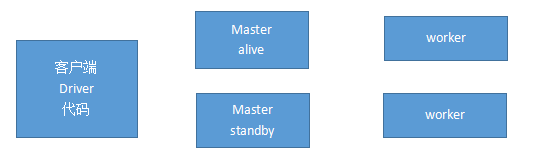
-客户端向master申请资源(哪个work可用)
-客户端会把自己的代码通过网络传到可以运行程序的worker上
-work机器上的程序运行完以后,需要把结果返回给客户端;
-application:客户端(driver+代码实现的功能)
-Job:一个application会有好多个job
-每一个job会有多个stage:(舞台)
-每一个stage都会有多个task
Spark-submit提交三种方式:
-Local:客户端,master,work都是自己
-高可用;客户端提交–deploy-mode(client发布的模式);如果程序木有执行完成,客户端不能关机;(适合少量数据,适合开发阶段,抽一些样板数据)
-高可用;集群提交–deploy-mode(cluster发布的模式)–deploy-mode(发布的模式);程序只要提交给某一个work,客户端就可以关机;(适合海量数据,适合线上生产阶段)
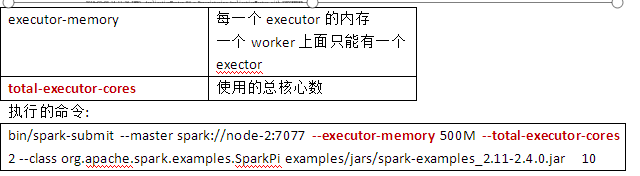
- Spark-submit





.Spark-hadoop对比 - 相同点:都是拿着一堆服务器共同去做一件事情
- 不同点:

历史服务器
-
启动spark集群以后,提交好多个应用程序(圆周率),停止spark;再重启的时候就看不到上一次提交的应用程序了
-
重启前已经有一个计划的结果

-
重启spark服务
-
看不到上一次重启前运行的应用程序了

-解决方案是历史服务器
- 修改配置文件:(conf/spark-defaults.conf);
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
#bin/spark-submit --master local[2] --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.0.jar 100
spark.master local[2]
# 历史服务器
spark.eventLog.enabled true
# 写日志的目录
spark.eventLog.dir hdfs://node-1:8020/spark/logs
# 读取日志的目录
spark.history.fs.logDirectory hdfs://node-1:8020/spark/logs
启动历史服务器
- sbin/start-history-server.sh

-查看日志
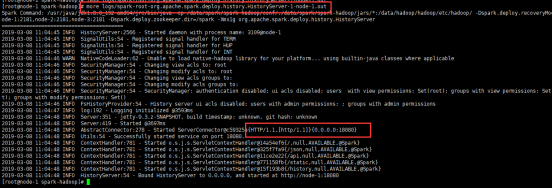
查看历史服务器(在提交应用程序的服务器上查看)
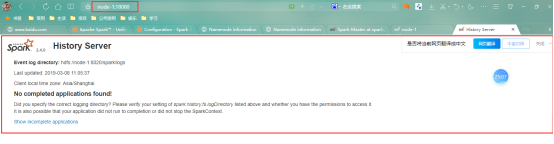
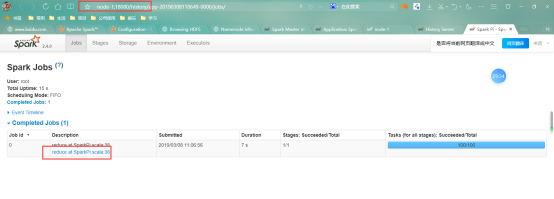



- 应用程序开发–hw
参照网址:http://spark.apache.org/docs/latest/quick-start.html
spark的应用程序支持:Spark建议的顺序scala>java>python;公司的实际情况:java>python>scala;
在2.0之前,我们使用的是RDD,在2.0以后,Spark建议使用DataSet;
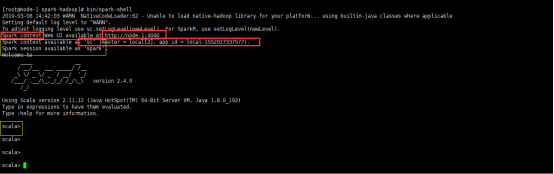
启动一个spark-shell;提供了一个简单的scala+spark的编程环境(可要可不要);而spark-submit很重要,在线上正式环境,将代码提交到集群的唯一方式;


准备一个数据源;可以是一个文件;(spark_data.txt)
this is a book
that is a table
tom log is log
hadoop hive bigtable
gfs haoop
Security is off.
Safemode is off.
Heap Memory used 38.09 MB of 43.99 MB Heap Memory. Max Heap Memory is 241.69 MB.
Non Heap Memory used 66.21 MB of 67.56 MB Commited Non Heap Memory. Max Non Heap Memory is

每一个action算子都转换成了一个job;

- 码的代码:spark-shell
/*
spark==sparkSession
read:读,
textFile();将参数名对应的文件内容读取一个对象中(dataSet);dataSet===List;List是单机的,DataSet是多机的
参数:文件的路径;如果木有配置yarn;路径默认的是就是本地路径;如果配置了yarn默认就是hdfs路径,在路径名的前面加上file://
打印以下结果:
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
*/
val textFile = spark.read.textFile("file:///root/spark_data.txt");
/*
统计一下总共有多少行;
dataSet:容器角度来说,dataSet容器的大小,默认是9个元素;在读取文件的时候,一行当成了一个元素;
打印:res1: Long = 9
count:在数据流里面是action算子;
*/
textFile.count() ;
/*
first===数据流里面的findFirst;
first:从dataSet中取第一个元素;
打印:res2: String = this is a book
count:在数据流里面是action算子;
*/
textFile.first();
/*
java的数据流;相当于把数据流里面的内容将给了filter这transformation算子;
filter:如果参数的方法返回true,数据保留,否则删除
contains:指的是当前对象(字符串)是否包含参数(字符串)
打印:filterRDD: org.apache.spark.sql.Dataset[String] = [value: string]
*/
val filterRDD = textFile.filter( t => t.contains("is") );
/*
又一个action算子;
打印一下filter之后的action算子的结果;
*/
filterRDD.foreach(println(_))
/*
map:算子,是将原来数据流里面的字符串转换成另外一个类型(int);每一行有多少个单词
打印:mapRDD: org.apache.spark.sql.Dataset[Int] = [value: int]
*/
val mapRDD = textFile.map(t => t.split(" ").size);
/*
collect:action算子,将数据流里面的内容收集一下;将数据流里面的内容打印出来;
每一行有多少个单词
打印:res6: Array[Int] = Array(4, 4, 4, 3, 2, 3, 3, 16, 18)
*/
mapRDD.collect();
/*
总共有多少个单词;
需求:请计算一下数组(4, 4, 4, 3, 2, 3, 3, 16, 18),每个数加起来的和是多少;
使用java实现此功能;
打印:res8: Int = 57
*/
mapRDD.reduce((a,b) => a + b );