爬虫requests库
requests是python的一个很实用的HTTP客户端库,完全满足如今网络爬虫的需求,具备Urilib的全部功能。完全兼容python2和python3,具有较强的适用性。
1.windows下的安装
pip install requests
2.requests库的7个主要方法(其实是一个基础方法,另外6个是调用基础方法形成的方法)
requests.request(method,url,**kwargs) 基础方法,构造一个请求,另外六种方法是在此方法上的变种形式。
requests.get() 获取html的网页的主要方法
requests.head() 获取html的网页**头信息**的主要方法
requests.post() 向网页提交post请求
requests.put() 向网页提交put请求
requests.patch() 向网页提交局部修改请求
requests.delete() 向网页提交删除请求
注意:由于安全原因,后四个方法是对网页的修改方法,所以这四个方法很难使用。
requests.request(method,url,**kwargs)
method:请求方式,对应get/put/post等7种
url:拟获取页面的url链接
**kwargs:控制访问参数,共13个均为可选项:。

十三个参数为:
params:字典或字节序列,作为参数增加到url中
data:字典,字节序列或文件对象,作为Request的内容
json:JSON格式的数据,作为Request的内容
headers:字典,HTTP定制头(模拟浏览器进行访问)
cokies:字典或CpplieJar,Request中的cookie
auth:元祖,支持HTTP认证功能
files:字典类型,传输文件
timeout:设定超时时间,秒为单位
proxies:字典类型,设定访问代理服务器,可以增加登陆认证
allow_redirects:True//False,默认为True,重定向开关
stream:True/False,默认为True,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径"""
requests.get(url,params=None,**kwarga) 获取html的网页的主要方法
**注意:由于基础方法request中可变参数只有13个,所以这里params已经占了一个参数,故而get方法中的kwarga只有12个可选的控制访问参数,把params单独拿出来,是因为这个参数可能经常使用的原因。

响应对象的属性
**
r.status_code 获取返回的状态码 200 404 ...
r.text HTTP响应内容文本形式返回
r.encoding 从header中猜测出的编码方法,一般都要修改为apparent_encoding 不然的话就会乱 码,不一定正确
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
**
import requests
response = requests.get("http://www.baidu.com")
print(response.status_code)
print(response.encoding)
print(response.apparent_encoding)
response.encoding = response.apparent_encoding
print(response.text)
结果;
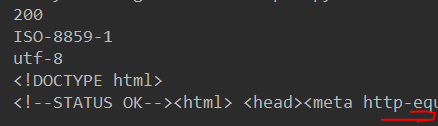
有图知:状态码200,表示请求成功,猜测的编码为ISO-8859-1,但根据内容分析的编码为utf-8,所以必须修改编码response.encoding = response.apparent_encoding才能正确显示。
print(response.headers) #返回的头部信息
print(type(response)) #response的类型
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'Keep-Alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 31 Mar 2019 01:53:16 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:32 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
<class 'requests.models.Response'>
如果headers没有说明编码(charset字段)方法,则默认编码为ISO-8859-1,即response.encoding为ISO-8859-1
requests库支持6种常见的链接异常:
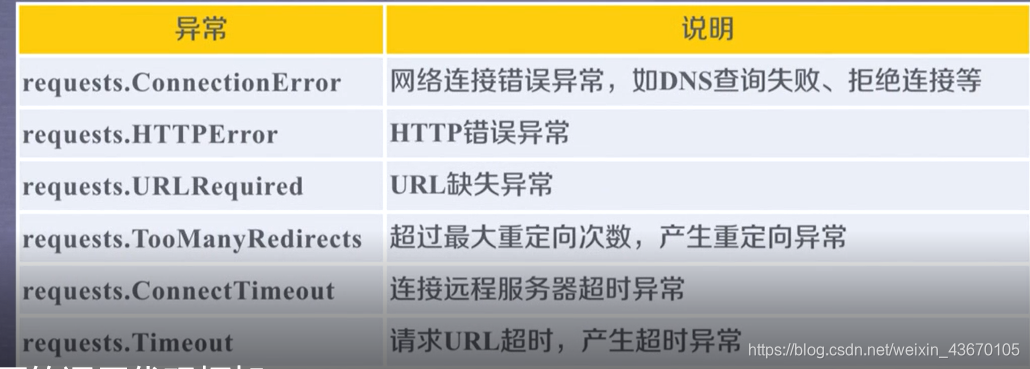
一个重要的方法:
response.raise_for_status() 如果状态不是200,就会产生HTTPError异常
这个方法可以让我们正确的处理异常,
通用代码框架 增加了异常处理
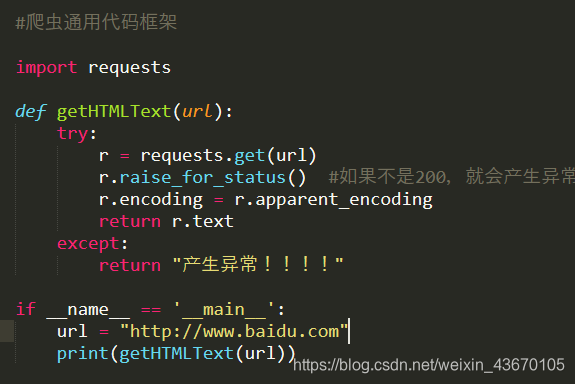



post()方法
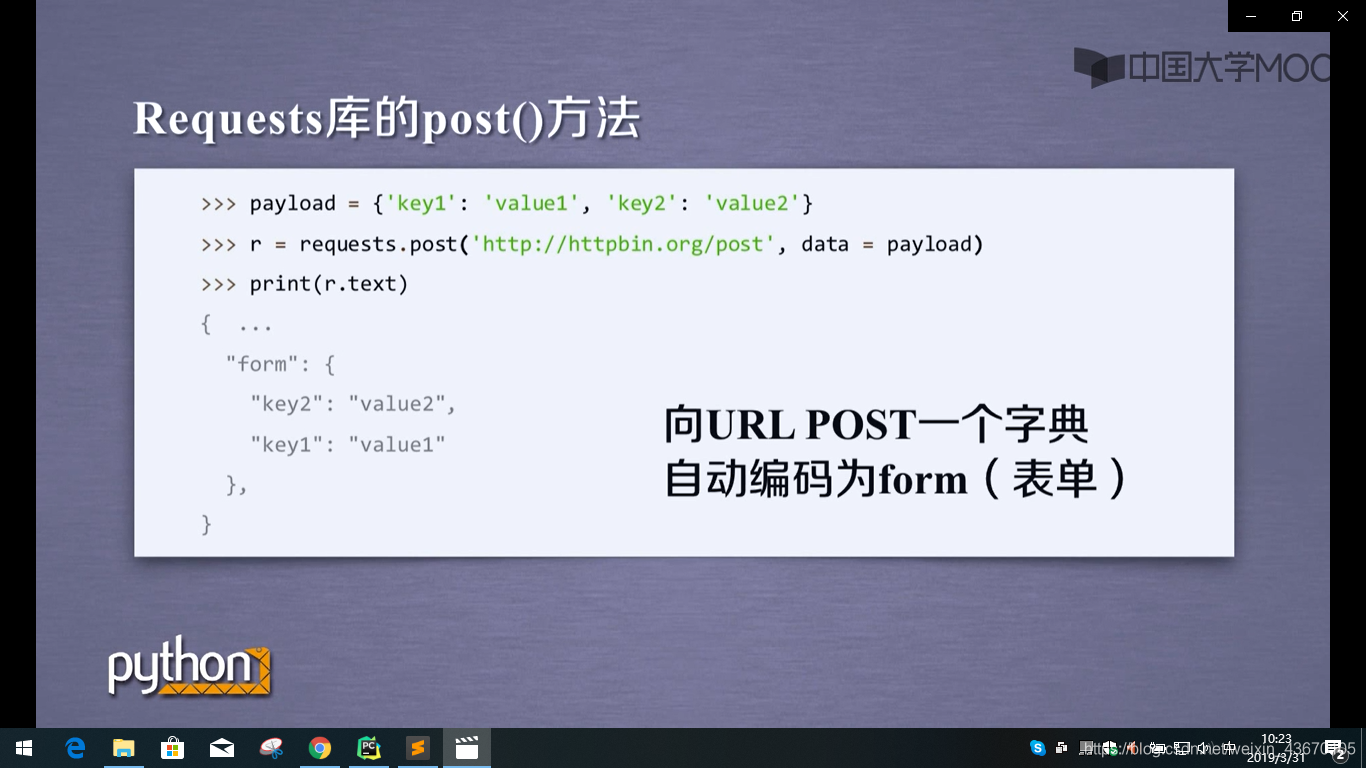
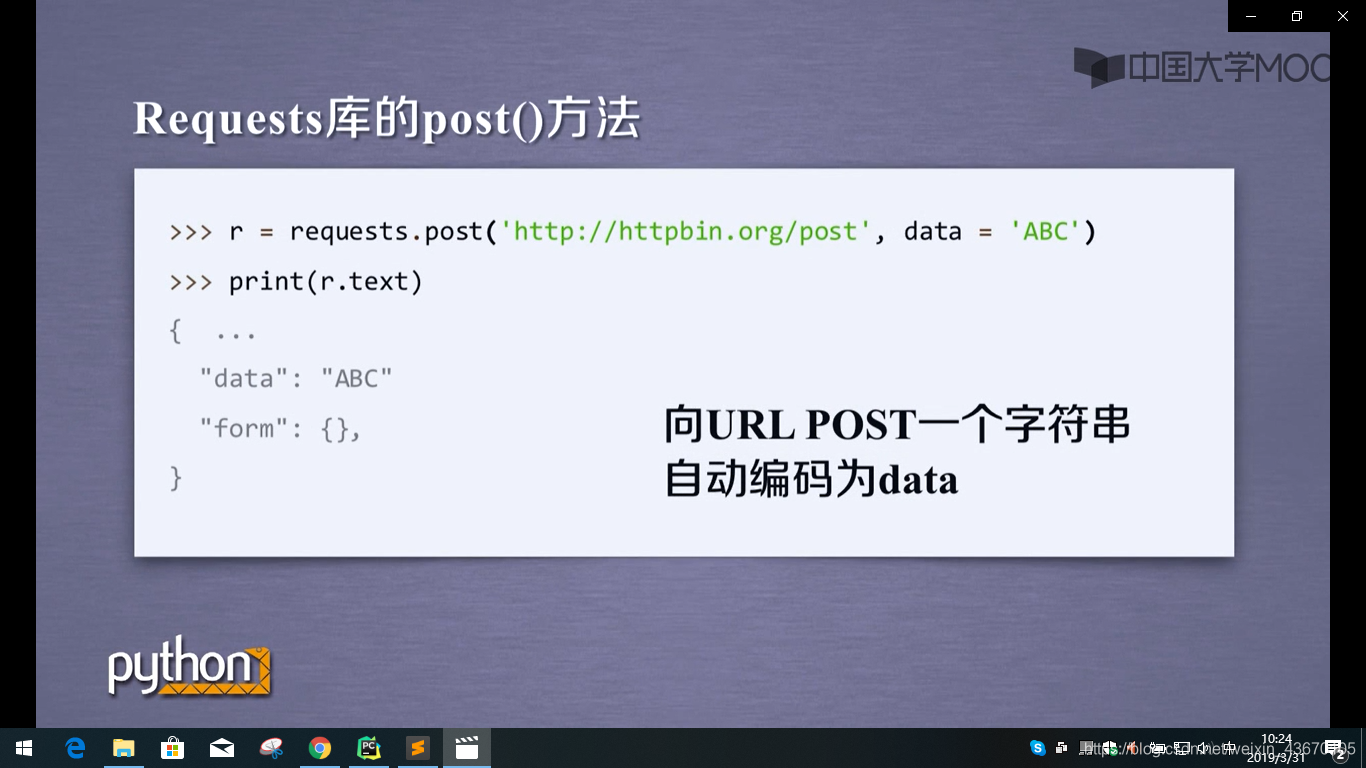
put()方法跟post方法类似,只不过put方法能覆盖原有的数据
带参数的URL的请求
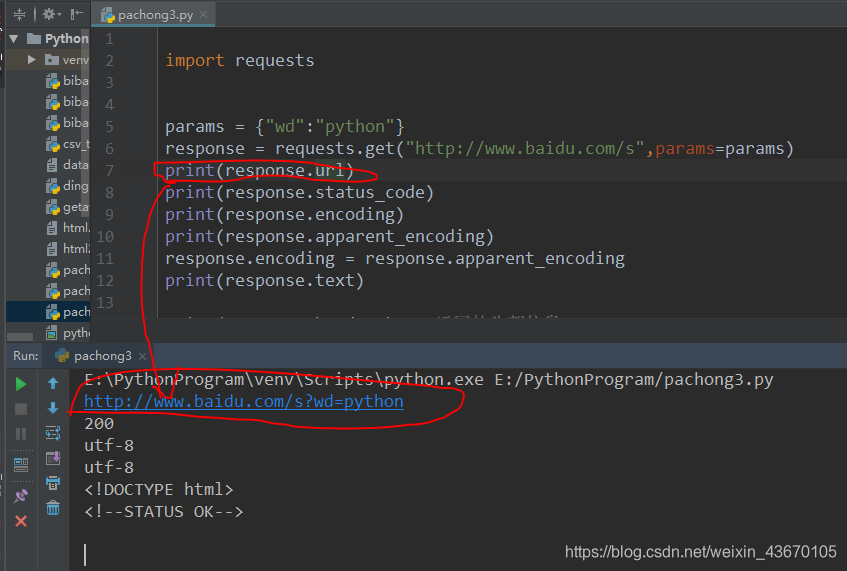
第一种方法:
response = requests.get("http://www.baidu.com/s?wd=python")
第二种方法:
params = {"wd":"python"}
response = requests.get("http://www.baidu.com/s",params=params)