Hadoop有三种操作模式,分别为单机模式,伪分布模式和全分布模式。
本文简单介绍和区分三种操作模式,并参考网上的文章,记录自己搭建伪分布模式集群的过程。
最后使用hadoop提供的example程序尝试运行。
1. Hadoop的三种模式
单机模式
- Hadoop的默认操作模式,该模式主要用于开发调试MapReduce程序的应用逻辑,而不会和守护进程交互
- 使用本地文件而不是HDFS
- 不会启动
NameNode、DataNode等守护进程,MapTask和ReduceTask作为同一进程的不同部分来执行
伪分布模式
-
操作是指在“单节点集群”上运行Hadoop,即一台主机模拟多台主机,
NameNode、DataNode等守护进程都运行在同一台机器上,是相互独立的Java进程 -
该模式在单机模式操作之上多了代码调试功能,可以查阅内存的使用情况、HDFS的输入输出以及守护进程之间的交互
全分布模式
- 实际意义上的Hadoop集群,守护进程运行在多台主机搭建的集群上
- 需要在所有主机安装JDK和Hadoop,组成相互连通的网络
- 在主机间设置SSH免密码登陆,把各个从节点(slave node) 生成的公钥添加到主节点的信任列表
2. 环境
-
系统:ubuntu16.04
-
JDK版本:jdk1.8.0_201
-
hadoop版本:hadoop-2.6.5
3. JDK安装
- 下载JDK1.8,打开链接JDK 1.8,选择Linux x64,下载得到
jdk-8u201-linux-x64.tar.gz - 使用tar命令解压,并放在
/opt/jdk1.8.0_201
tar -xf jdk-8u201-linux-x64.tar.gz #解压
mv jdk1.8.0_201 /opt/ #移动到opt目录下
- 配置JDK的环境变量,即在/etc/profile文件中加入对应语句
vim /etc/profile #打开配置文件
#添加两行代码
export JAVA_HOME=/opt/jdk1.8.0_201
export PATH=$PATH:$JAVA_HOME/bin
- 激活环境变量
source /etc/profile
java -version #检查是否安装成功
4. 安装hadoop
- 在hadoop各个版本下载hadoop-2.6.5,下载得到
hadoop-2.6.5.tar.gz - 使用tar命令解压,并放在
/opt/hadoop-2.6.5
tar -xf hadoop-2.6.5.tar.gz
mv hadoop-2.6.5 /opt/
- 到/opt/目录中,创建软链接再配置环境变量,之后若使用不同版本就只需重新创建软链接,不用重新配置
ln -snf hadoop-2.6.5 hadoop #创建软链接
vim /etc/profile
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 激活环境变量
source /etc/profile
hadoop version #检查是否安装成功
5. 配置hadoop
修改过程需要把#后的内容去掉,此处仅为个人理解而添加
- 配置文件存放在
/opt/hadoop/etc/hadoop中
cd /opt/hadoop/etc/hadoop
- 修改hadoop-env.sh第25行
JAVA_HOME,设置为与上述JDK配置时一致
#export JAVA_HOME=${JAVA_HOME} #注释掉原来的
export JAVA_HOME=/opt/jdk1.8.0_201
- 修改core-site.xml最后的configuration,补充如下,192.168.1.165:9000为主机ip和端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.165:9000</value>
</property>
</configuration>
-
修改hdfs-site.xml,同样修改最后的configuration如下:
关于这里的checkpoint,可以参考解读Secondary NameNode的功能
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value> #namenode目录
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
#edit文件目录,用于secondary namenode更新fsimage
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value> #datanode目录
</property>
</configuration>
- 修改mapred-site.xml,在hadoop的相关目录中没有此文件,但是有一个mapred-site.xml.template文件,将该文件复制一份为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> #资源调度框架设置为YARN
</property>
<!-- 设置jobhistoryserver 没有配置的话 history入口不可用 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<!-- 配置web端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
</configuration>
- 修改yarn-site.xml
<configuration>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name> #RM主机
<value>192.168.1.165</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> #MapReduce程序所需的Shuffle service
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data/hadoop/yarn/nm</value> #NM本地目录
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
- 创建上述配置中的相关目录
sudo mkdir -p /data/hadoop/hdfs/nn
sudo mkdir -p /data/hadoop/hdfs/dn
sudo mkdir -p /data/hadoop/hdfs/snn
sudo mkdir -p /data/hadoop/yarn/nm
- 若用当前用户启动各个守护进程,则需要用户对/opt和/data目录有读写权限
chown zyc[我的用户名] /opt
chmod -R 777 /data
- 格式化HDFS集群
hdfs namenode -format
6. 启动Hadoop
启动所需的sh文件都在/opt/hadoop/sbin中,前面已经将该路径加入环境变量,可直接访问。
- 启动HDFS集群
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
- 启动YARN集群
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
- 启动作业历史服务器
mr-jobhistory-daemon.sh start historyserver
- jps查看是否成功启动
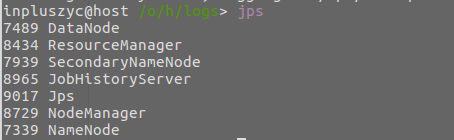
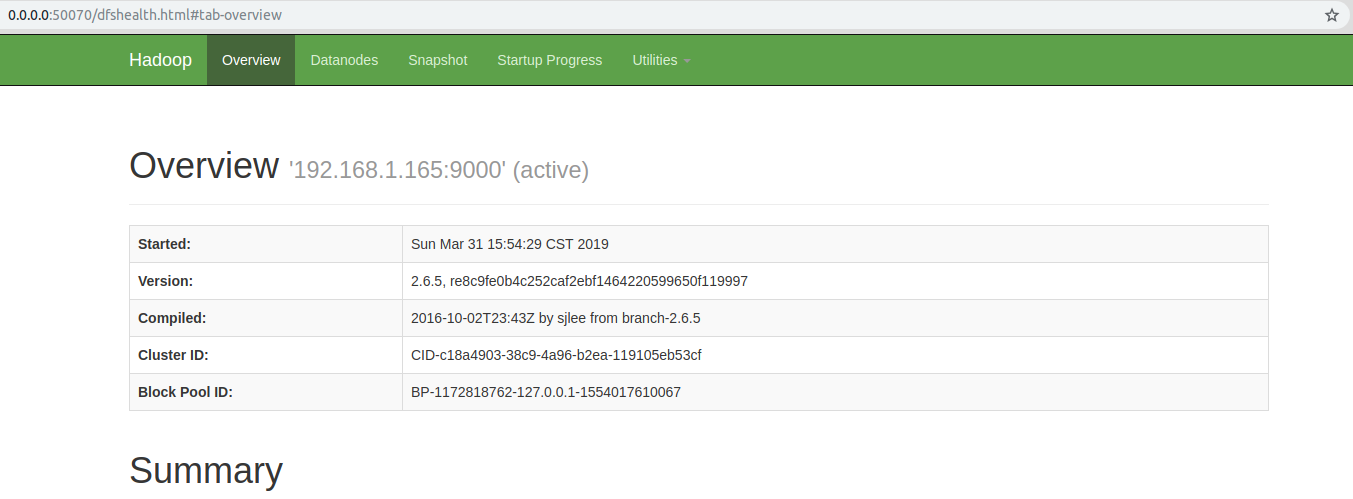
-
登陆ip:50070查看
HDFS的web监控页面
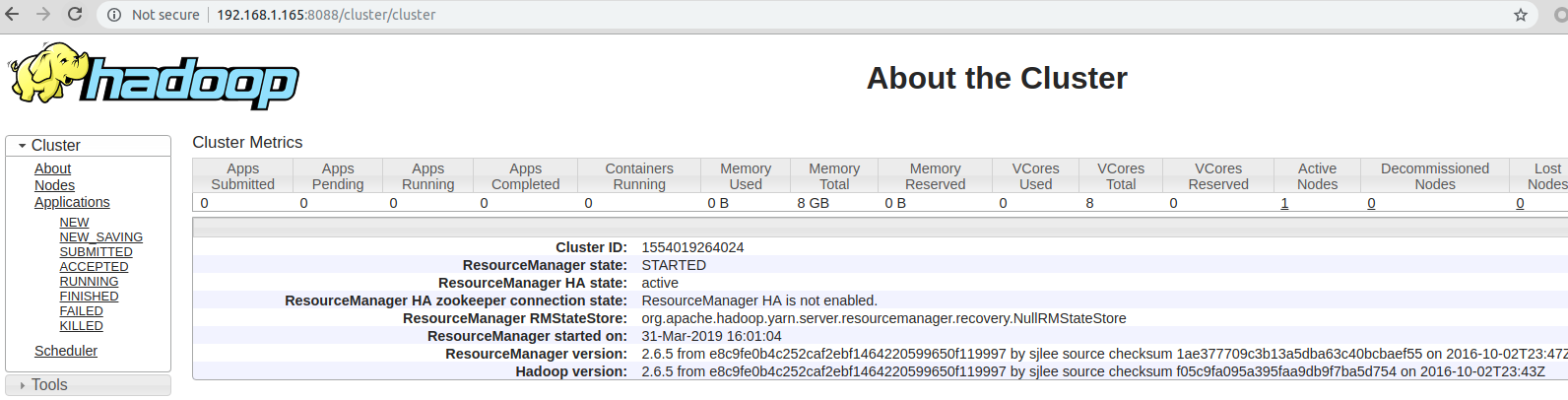
-
登陆ip:8088查看
YARN的web监控页面
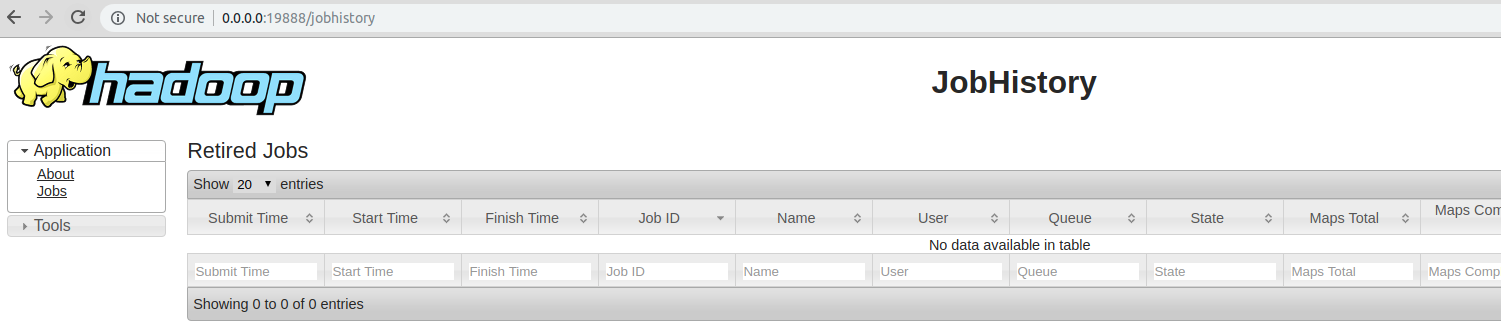
-
登陆localhost:19888查看
jobhistory监控页面
-
关闭命令只需将上述命令的start改为stop即可
-
开启时可以使用
start-all.sh,关闭时可以使用stop-dfs.sh,stop-yarn.sh
7.HDFS集群作业提交
- 使用hadoop中提供的计算pi的example,提交如下:
yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 4 10000
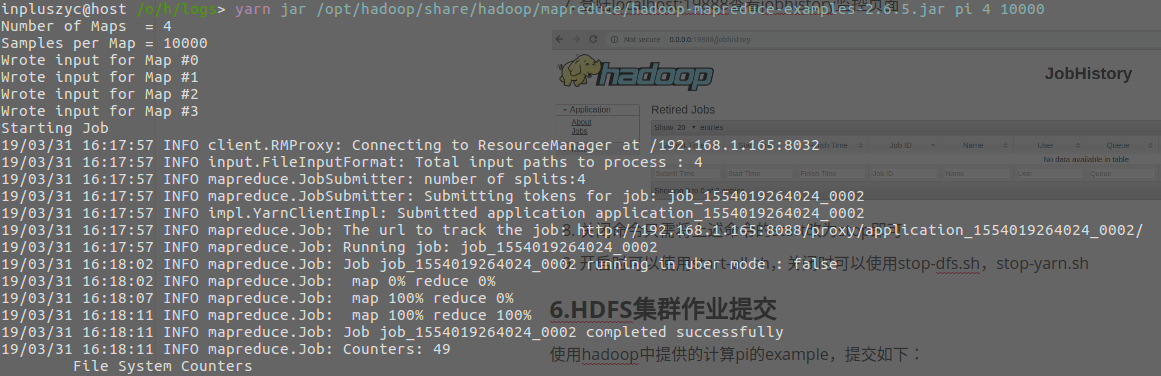
-
查看yarn监控页面的记录,如下(此处运行了两遍,所以有两个):
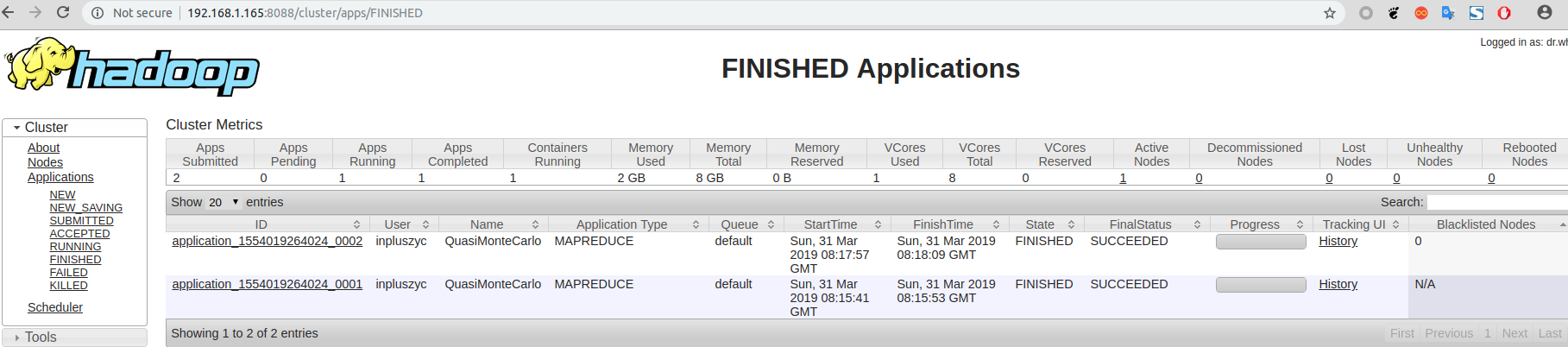
-
查看jobhistory的记录,如下:
