\[\color{#ff4081}\small\texttt{欢迎来访我的主页}\]
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
\(\tiny\text{以上来自百度百科}\)
通俗来说,就是给你N个点,分为两组,每组中的任意两点没有边相连,但两组之间,有边。举个栗子:
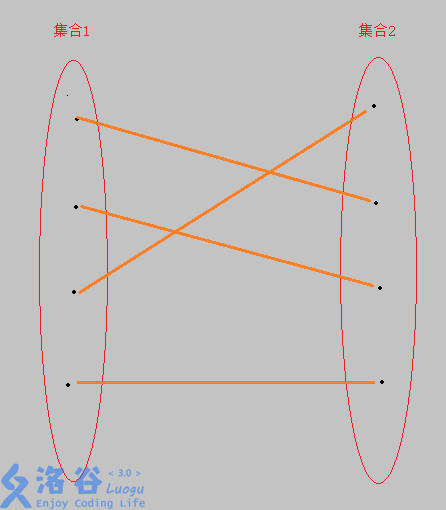
由于有如此优美的图,这图上也便有了很多优美的算法。
常见的有:
1. 二分图染色算法。
2. 二分图匹配。
3. 带权二分图匹配。染色算法
染色算法又称\(dfs\)求解奇环,可以用并查集求解。这里讲不用并查集的一种方法。
二分图染色算法用得并不是很多,但要让大家充分了解二分图,染色算法是必不可少的。
将下面的图染色:
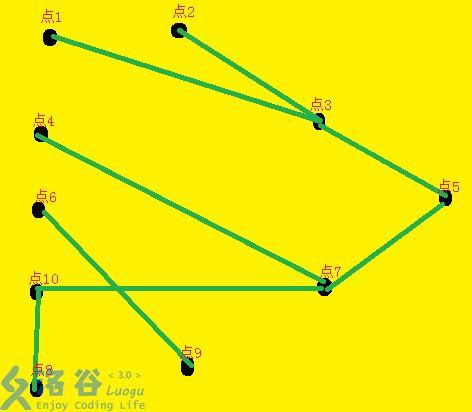
我们得到的结果为:
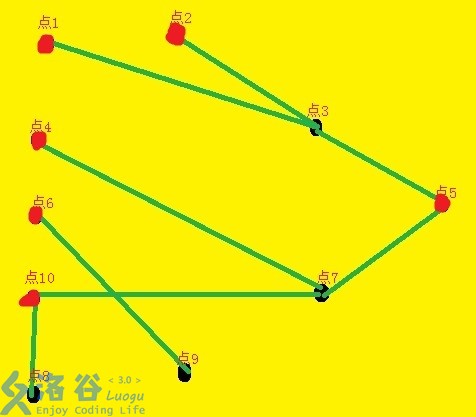
整理得:
\(\tiny\texttt{(实际上,上一个图还可以把点6、点9交换位置。)}\)
看我讲了这么久,你可能要问:染色算法有什么用?
举个栗子:\(\small\color{#ff4081}\texttt{双栈排序}\)
\(My~code:\)
#include <cstdio>
#include <cstring>
using namespace std;
int n,id;
struct edge
{
int v,nx;
}set[500005];
int head[1005],a[1005],b[1005],color[1005],s[3][1005];
int Min(int a,int b)
{
if(a<b)return a;
return b;
}
void Addedge(int u,int v)
{
id++;set[id].v=v;set[id].nx=head[u];
head[u]=id;
}
bool dfs(int x)
{
for(int i=head[x];i>0;i=set[i].nx)
{
if(color[set[i].v]==0)
{
color[set[i].v]=3-color[x];dfs(set[i].v);
}
if(color[set[i].v]==color[x])return false;
}
return true;
}
void outp()
{
int Now=1;
for(int i=1;i<=n;i++)
{
if(color[i]==1)printf("a ");else printf("c ");
s[color[i]][0]++;s[color[i]][s[color[i]][0]]=a[i];
while((s[1][s[1][0]]==Now)||(s[2][s[2][0]]==Now))
{
if(s[1][s[1][0]]==Now)
{
printf("b%c",Now<n?' ':'\n');
s[1][0]--;
}
if(s[2][s[2][0]]==Now)
{
printf("d%c",Now<n?' ':'\n');
s[2][0]--;
}
Now++;
}
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
b[n+1]=1000000;
for(int i=n;i>=1;i--)b[i]=Min(b[i+1],a[i]);
for(int i=1;i<=n;i++)
{
for(int j=i+1;j<=n;j++)
{
if((b[j+1]<a[i])&&(a[i]<a[j]))
{
Addedge(i,j);
Addedge(j,i);
}
}
}
bool ans=true;
for(int i=1;i<=n;i++)
{
if(color[i]==0)
{
color[i]=1;
if(dfs(i)==false){ans=false;break;}
}
}
if(!ans)puts("0");else outp();
return 0;
}\[\color{red}\text{我的dfs就是一个染色过程。}\]
那么现在你应该懂得了,染色算法就是用来判断图是否为二分图。
染色算法-模板题:\(\small\color{#ff4081}\texttt{P1525 关押罪犯}\)
\(My~code:\)
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
int n,m,id;
bool flag=true;
struct read
{
int a,b;long long c;
void in()
{
cin>>a>>b>>c;
}
}read[100005];
struct edge
{
int v,nx;
}set[100005];
int head[20005],color[20005];
bool cmp(struct read a,struct read b)
{
return a.c>b.c;
}
void Addedge(int u,int v)
{
id++;set[id].v=v;set[id].nx=head[u];
head[u]=id;
}
void dfs(int u)
{
for(int k=head[u];k>0;k=set[k].nx)
{
if(color[set[k].v]==0)
{
color[set[k].v]=3-color[u];
dfs(set[k].v);
}
if(color[set[k].v]==color[u]){flag=false;return;}
}
}
int main()
{
memset(head,-1,sizeof(head));
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)read[i].in();
sort(read+1,read+m+1,cmp);
for(int i=1;i<=m;i++)
{
Addedge(read[i].a,read[i].b),Addedge(read[i].b,read[i].a);
memset(color,0,sizeof(color));
color[read[i].a]=1;dfs(read[i].a);
if(!flag){cout<<read[i].c<<endl;break;}
}
if(flag)puts("0");
return 0;
}二分图匹配
二分图匹配一般用\(\color{purple}\small\texttt{匈牙利算法}\)。
***
匈牙利算法求解最大匹配一般是这样的:
- 第一步:建图

- 第二步:匹配
- 将1与5匹配

- 将2与6匹配

- 将3与5匹配,然而我们发现:5已经和1匹配,那么我们是 遵循先入 为主,还是 强行入住 呢?
当然要匹配,我们将1与5取消匹配,让1再去和其他的点匹配,若成,3和5匹配;不成,3和其他顶点匹配。1与7匹配成功!3与5匹配成功!如图:

第三步:输出
至此,我们可爱的匈牙利算法就结束了,上图最大匹配为3。
详情请见代码:
#include <cstdio>
#include <cstring>
using namespace std;
int read()
{
int x=0,f=1;char c=getchar();
while (c<'0' || c>'9'){if (c=='-')f=-1;c=getchar();}
while (c>='0'&&c<='9'){x=(x<<1)+(x<<3)+c-48;c=getchar();}
return x*f;
}
const int MAXN=105;
const int MAXM=1005;
int n,m,e,id;
struct edge
{
int v,nx;
}set[MAXM];
int head[MAXN],match[MAXN];
bool chk[MAXN];
void Addedge(int u,int v)
{
id++;set[id].v=v;set[id].nx=head[u];
head[u]=id;
}
void make_map()
{
memset(head,-1,sizeof(head));
int u,v;
n=read();m=read();e=read();
for (int i=1;i<=e;i++)
{
u=read();v=read();
Addedge(u,v);
}
}
bool dfs(int u)
{
int v;
for (int k=head[u];k>0;k=set[k].nx)
{
v=set[k].v;
if (!chk[v])
{
chk[v]=true;
if ((match[v]==-1)||dfs(match[v]))
{
match[v]=u;return true;
}
}
}
return false;
}
void work()
{
memset(match,-1,sizeof(match));
int ans=0;
for (int i=1;i<=n;i++)
{
memset(chk,0,sizeof(chk));
if (dfs(i))ans++;
}
printf("%d\n",ans);
}
int main()
{
make_map();
work();
return 0;
}模板题:\(\small\color{#ff4081}\texttt{P3386 【模板】二分图匹配}\)
更改定义规模,加入坑点过滤后,我成功满分:

匈牙利算法的时间复杂度为\(O(N * M)\),其中\(N\)为顶点数,\(M\)为边数,在题目要求不高的情况下还是很好用的。另外,我劝告大家,尽量使用前向星或领接表存图,至于邻接矩阵,它已经死了:

当然,如果你一定要用邻接矩阵,可以试一下int数组记录优化:
#include <cstdio>
#include <cstring>
using namespace std;
int n,m,v,now;
int ans;
int match[1005];
int g[1005][1005],chk[1005];
int dfs(int x)
{
for(int y=1;y<=m;y++)
if(g[x][y]&&chk[y]!=now)
{
chk[y]=now;
if((match[y]==0)||dfs(match[y]))
{
match[y]=x;return 1;
}
}
return 0;
}
int main()
{
int a,b;
scanf("%d%d%d",&n,&m,&v);
for(int i=1;i<=v;i++)
{
scanf("%d%d",&a,&b);
if(a>=1&&a<=n&&b>=1&&b<=m)g[a][b]=1;
}
for(int i=1;i<=n;i++)
{
now++;
if(dfs(i))ans++;
}
printf("%d\n",ans);
return 0;
}但效率仍然很低下:

*扩展:网络流求解最大匹配:
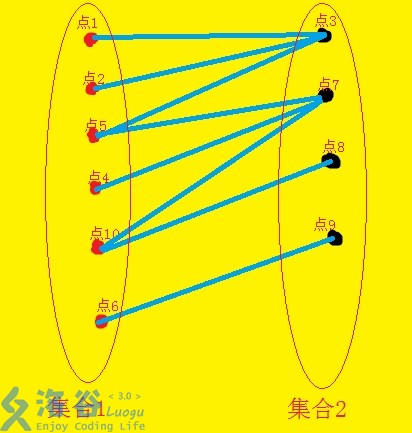
对于下面的二分图:

我们用超级源连接集合1、超级汇连接集合2:
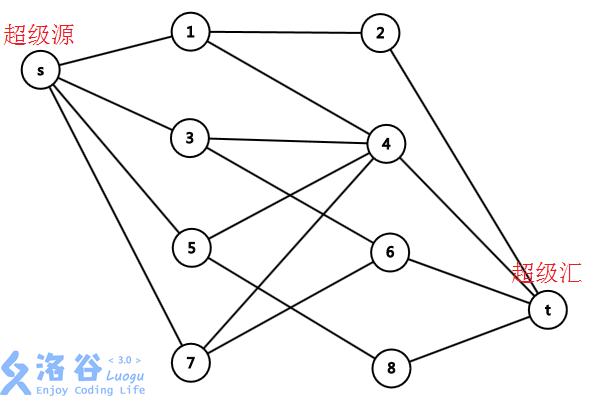
定义每条边的权值为1,再跑一遍最大流就可以了。