spark 核心是RDD:弹性分布式数据集

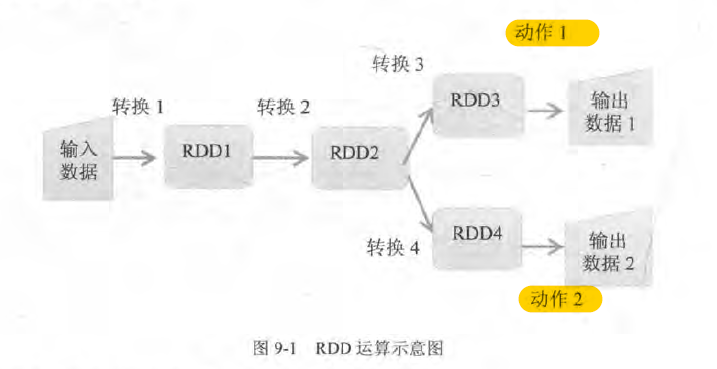
基本RDD 转换运算
- 创建intRDD
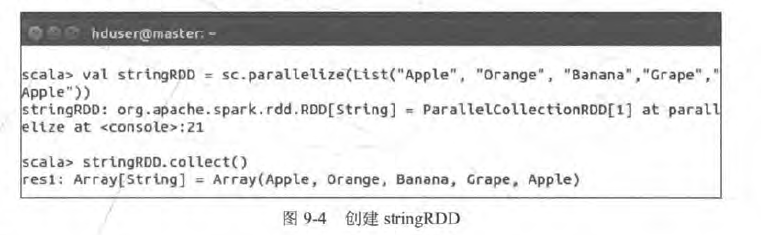
- 创建stringRDD
- map 运算
- filter 数字运算
- filter 字符串运算
- distinct 运算
- 去除重复元素
- 去除重复元素
- randomSplit 运算
- 随机按照比例分为多个RDD
- 如下比例:0.4:0.6

- groupBy 运算
- 根据匿名函数规则,分为多个Array






多个RDD 转换运算
- 创建3个范例RDD
- union 并集运算
- innersection 交集运算
- substract 差集运算
- cartesian 笛卡尔乘积运算





基本动作运算
- 读取数据
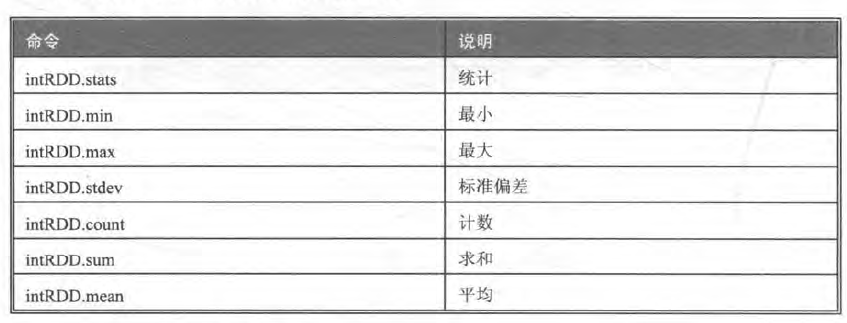
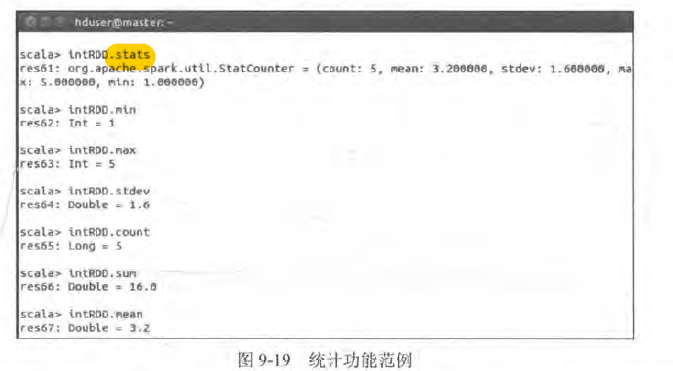
- 统计功能

RDD key-value 基本转换运算
- 创建范例 k-v RDD







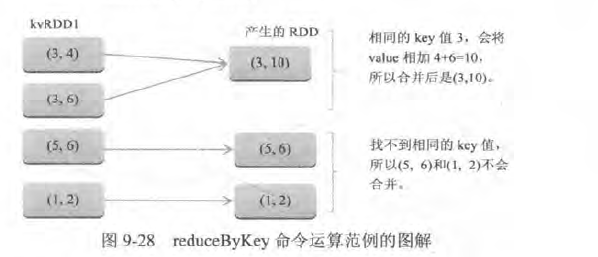
- 将具有相同key的值合并


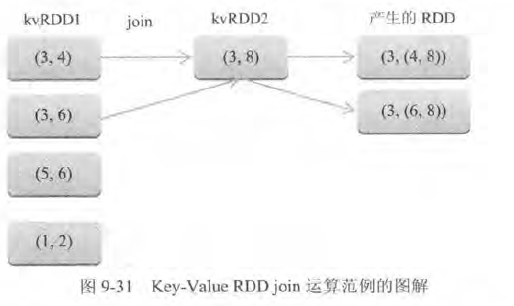
多个RDD k-v 转换运算

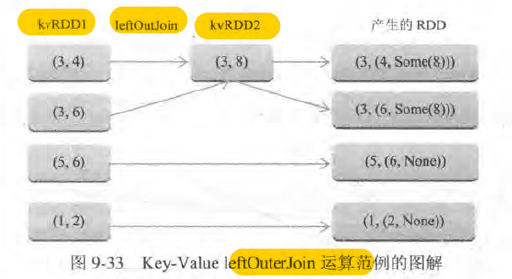
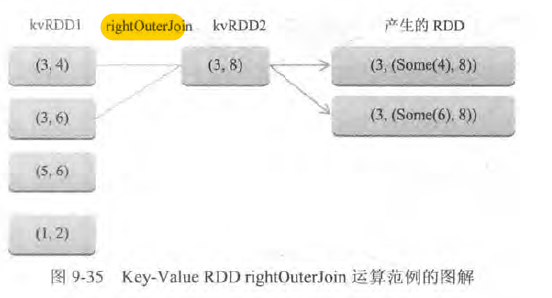
- 按照key 做差





key-value 动作运算




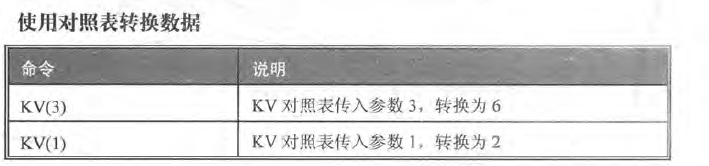
- 根据key 查找value






共享变量:用于节省内存和运行时间,提升并行执行时的运行效率
- 分为两种:
- Broadcast 广播变量
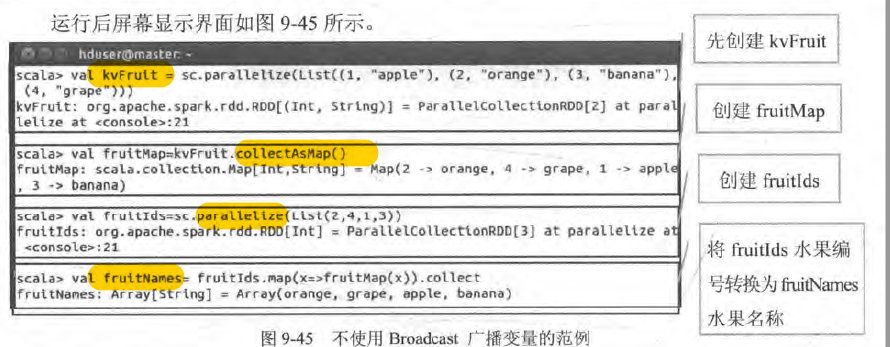
- 不使用广播
- 使用广播变量
- 不使用广播
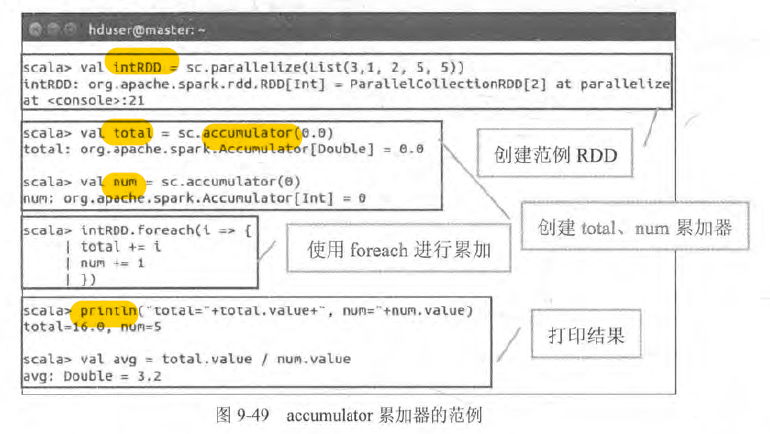
- accumulator 累加器
- Broadcast 广播变量



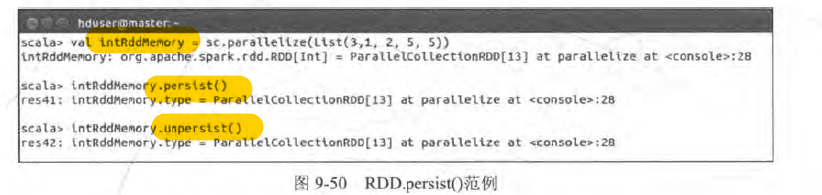
RDD persistence 持久化
- 需要重复运算的RDD 存储到内存中
- 默认memory_only

- 默认memory_only
