转自:http://www.importnew.com/21517.html
哎,虽然自己最熟的是Java,但很多Java基础知识都不知道,比如transient关键字以前都没用到过,所以不知道它的作用是什么,今天做笔试题时发现有一题是关于这个的,于是花个时间整理下transient关键字的使用,涨下姿势~~~好了,废话不多说,下面开始:
1. transient的作用及使用方法
我们都知道一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。
然而在实际开发过程中,我们常常会遇到这样的问题,这个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
总之,java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
示例code如下:
| 1 2 3 4 5
扫描二维码关注公众号,回复:
5763310 查看本文章

6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
|
输出为:
| 1 2 3 4 5 6 7 |
|
密码字段为null,说明反序列化时根本没有从文件中获取到信息。
2. transient使用小结
1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3)被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化。
第三点可能有些人很迷惑,因为发现在User类中的username字段前加上static关键字后,程序运行结果依然不变,即static类型的username也读出来为“Alexia”了,这不与第三点说的矛盾吗?实际上是这样的:第三点确实没错(一个静态变量不管是否被transient修饰,均不能被序列化),反序列化后类中static型变量username的值为当前JVM中对应static变量的值,这个值是JVM中的不是反序列化得出的,不相信?好吧,下面我来证明:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
|
运行结果为:
| 1 2 3 4 5 6 7 |
|
这说明反序列化后类中static型变量username的值为当前JVM中对应static变量的值,为修改后jmwang,而不是序列化时的值Alexia。
3. transient使用细节——被transient关键字修饰的变量真的不能被序列化吗?
思考下面的例子:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
|
content变量会被序列化吗?好吧,我把答案都输出来了,是的,运行结果就是:
| 1 |
|
这是为什么呢,不是说类的变量被transient关键字修饰以后将不能序列化了吗?
我们知道在Java中,对象的序列化可以通过实现两种接口来实现,若实现的是Serializable接口,则所有的序列化将会自动进行,若实现的是Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal方法中进行手工指定所要序列化的变量,这与是否被transient修饰无关。因此第二个例子输出的是变量content初始化的内容,而不是null。
转自:https://bluepopopo.iteye.com/blog/486548
在Java中使用Serialization相当简单。如果你有一些对象想要进行序列化,你只需实现Serializable接口。然后,你可以使用ObjectOutputStream将该对象保存至文件或发送到其他主机。所有的non-transient和non-static字段都将被序列化,并且由反序列化重构造出一模一样的对象联系图(譬如许多引用都指向该对象)。但有时你可能想实现你自己的对象序列化和反序列化。那么你可以在某些特定情形下得到更多的控制。来看下面的简单例子。
Java代码
![]()
- class SessionDTO implements Serializable {
- private static final long serialVersionUID = 1L;
- private int data; // Stores session data
- // Session activation time (creation, deserialization)
- private long activationTime;
- public SessionDTO(int data) {
- this.data = data;
- this.activationTime = System.currentTimeMillis();
- }
- public int getData() {
- return data;
- }
- public long getActivationTime() {
- return activationTime;
- }
- }
以下是序列化上述class到文件和其反序列化的主函数。
Java代码
![]()
- public class SerializeTester implements Serializable {
- public static void main(String... strings) throws Exception {
- File file = new File("out.ser");
- ObjectOutputStream oos = new ObjectOutputStream(
- new FileOutputStream(file));
- SessionDTO dto = new SessionDTO(1);
- oos.writeObject(dto);
- oos.close();
- ObjectInputStream ois = new ObjectInputStream(
- new FileInputStream(file));
- SessionDTO dto = (SessionDTO) ois.readObject();
- System.out.println("data : " + dto.getData()
- + " activation time : " + dto.getActivationTime());
- ois.close();
- }
- }
类SessionDTO展现的是要在两个服务器之间传输的session。它包含了一些信息在字段data上,该字段需要被序列化。但是它还有另外一个字段activationTime,该字段应该是session对象第一次出现在任意服务器上的时间。它不在我们想要传输的信息之列。这个字段应该在反序列化之后在赋值。进一步来说,没必要把它放在stream中在服务器中传递,因为它占据了不必要的空间。
解决这种情况可以使用writeObject和readObject。有可能你们有一些人没有听说过它们,那是因为它们在许多Java书籍中给忽略了,而且它们们也不是众多流行Java考试的一部分。让我们用这些方法来重写SessionDTO:
Java代码
![]()
- class SessionDTO implements Serializable {
- private static final long serialVersionUID = 1L;
- private transient int data; // Stores session data
- //Session activation time (creation, deserialization)
- private transient long activationTime;
- public SessionDTO(int data) {
- this.data = data;
- this.activationTime = System.currentTimeMillis();
- }
- private void writeObject(ObjectOutputStream oos) throws IOException {
- oos.defaultWriteObject();
- oos.writeInt(data);
- System.out.println("session serialized");
- }
- private void readObject(ObjectInputStream ois) throws IOException,
- ClassNotFoundException {
- ois.defaultReadObject();
- data = ois.readInt();
- activationTime = System.currentTimeMillis();
- System.out.println("session deserialized");
- }
- public int getData() {
- return data;
- }
- public long getActivationTime() {
- return activationTime;
- }
- }
方法writeObject处理对象的序列化。如果声明该方法,它将会被ObjectOutputStream调用而不是默认的序列化进程。如果你是第一次看见它,你会很惊奇尽管它们被外部类调用但事实上这是两个private的方法。并且它们既不存在于java.lang.Object,也没有在Serializable中声明。那么ObjectOutputStream如何使用它们的呢?这个吗,ObjectOutputStream使用了反射来寻找是否声明了这两个方法。因为ObjectOutputStream使用getPrivateMethod,所以这些方法不得不被声明为priate以至于供ObjectOutputStream来使用。
在两个方法的开始处,你会发现调用了defaultWriteObject()和defaultReadObject()。它们做的是默认的序列化进程,就像写/读所有的non-transient和 non-static字段(但他们不会去做serialVersionUID的检查).通常说来,所有我们想要自己处理的字段都应该声明为transient。这样的话,defaultWriteObject/defaultReadObject便可以专注于其余字段,而我们则可为这些特定的字段(译者:指transient)定制序列化。使用那两个默认的方法并不是强制的,而是给予了处理复杂应用时更多的灵活性。
你可以从这里或这里读到更多有关于序列化的知识。
自己再补充一些:
1.Write的顺序和read的顺序需要对应,譬如有多个字段都用wirteInt一一写入流中,那么readInt需要按照顺序将其赋值;
2.Externalizable,该接口是继承于Serializable ,所以实现序列化有两种方式。区别在于Externalizable多声明了两个方法readExternal和writeExternal,子类必须实现二者。Serializable是内建支持的也就是直接implement即可,但Externalizable的实现类必须提供readExternal和writeExternal实现。对于Serializable来说,Java自己建立对象图和字段进行对象序列化,可能会占用更多空间。而Externalizable则完全需要程序员自己控制如何写/读,麻烦但可以有效控制序列化的存储的内容。
3.正如Effectvie Java中提到的,序列化就如同另外一个构造函数,只不过是有由stream进行创建的。如果字段有一些条件限制的,特别是非可变的类定义了可变的字段会反序列化可能会有问题。可以在readObject方法中添加条件限制,也可以在readResolve中做。参考56条“保护性的编写readObject”和“提供一个readResolve方法”。
4.当有非常复杂的对象需要提供deep clone时,可以考虑将其声明为可序列化,不过缺点也显而易见,性能开销。
转自:https://www.cnblogs.com/leodaxin/p/9088741.html
被transient修饰真的会被序列化吗?
反例:java.util.ArrayList中底层存储数组就是transient,但是实际上还是可以被成功序列化。具体原因如下:
| 1 |
|
我的测试代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
输出:
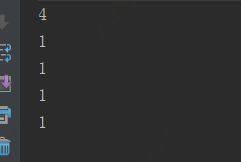
数据还是成功序列化了,为什么会被序列化呢?分析原因还是需要看源码,就以java.io.ObjectOutputStream#writeObject写对象为入手点,跟踪源码会跟中到如下方法java.io.ObjectStreamClass#invokeWriteObject:
方法源码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
通过debug可以看到最终调用的是java.util.ArrayList#writeObject ,java.util.ArrayList#writeObject源码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
可以看出最终将elementData写出去了。反序列化同理不在分析。
重点来了,name为什么JDK需要这么做呢?原因如下:
JDK为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
小提示:
java.io.ObjectOutputStream#writeObject中的enableOverride字段可以自行实现writeObjectOverride方法,对于enableOverride=true需要通过实现ObjectOutputStream的子类实现自定义写对象。