Un-supervised Learning
- 分为两类:
(1)聚类 & 降维(化繁为简):将多个输入抽象成一种类型
(2)Generation(无中生有):输入一个code,得到一个样本 - 聚类中最常用的方法有:
(1)k-means:a.随机初始化k个类的中心点;b.每个样本以最靠近的中心点的所属类为类标签;c.根据新得到的分类更新中心点;d.重复步骤b、c,直到模型收敛。
(2)Hierarchical Agglomeratiive clustering (HAC)层次聚类方法:a.根据样本之间的两两相似程度来建立一颗树; - 单单用聚类来表示样本的话,难以很形象的表示样本的特征,大部分样本不是确定属于哪一类的,可以用一个vector分布来表示这个样品的特征。通过这种方式能够将样品从属性表示,到特征表示这个比较低维的空间中。方法有特征选择和PCA。
PCA的解法下所示
(1)首先要让样本在所投影到的维度上的方差尽量大
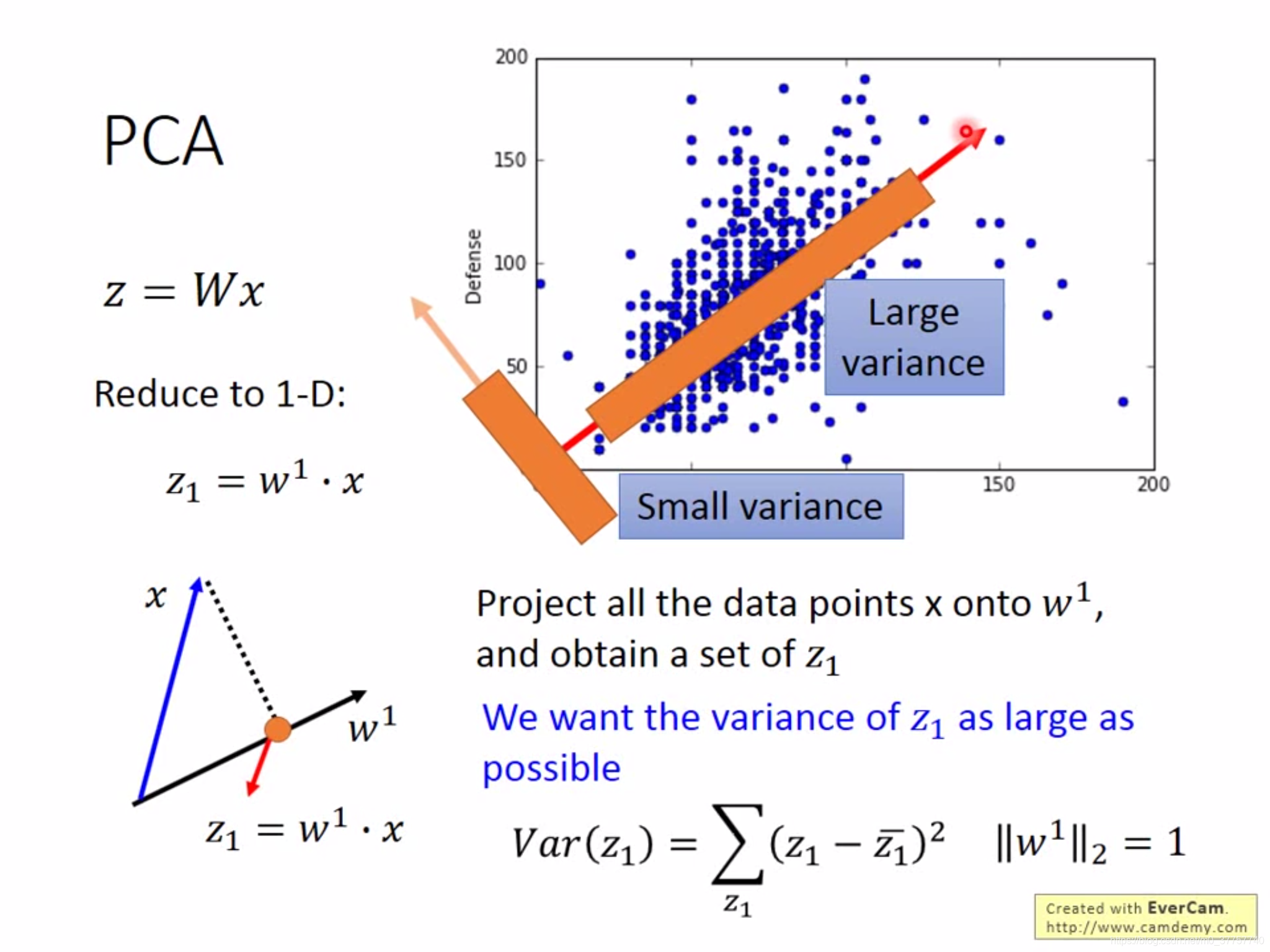
(2)PCA多维合并的优化函数,w的转置乘以协方差矩阵再乘以w,如图所示,找到一个w使得整个目标函数最大化。

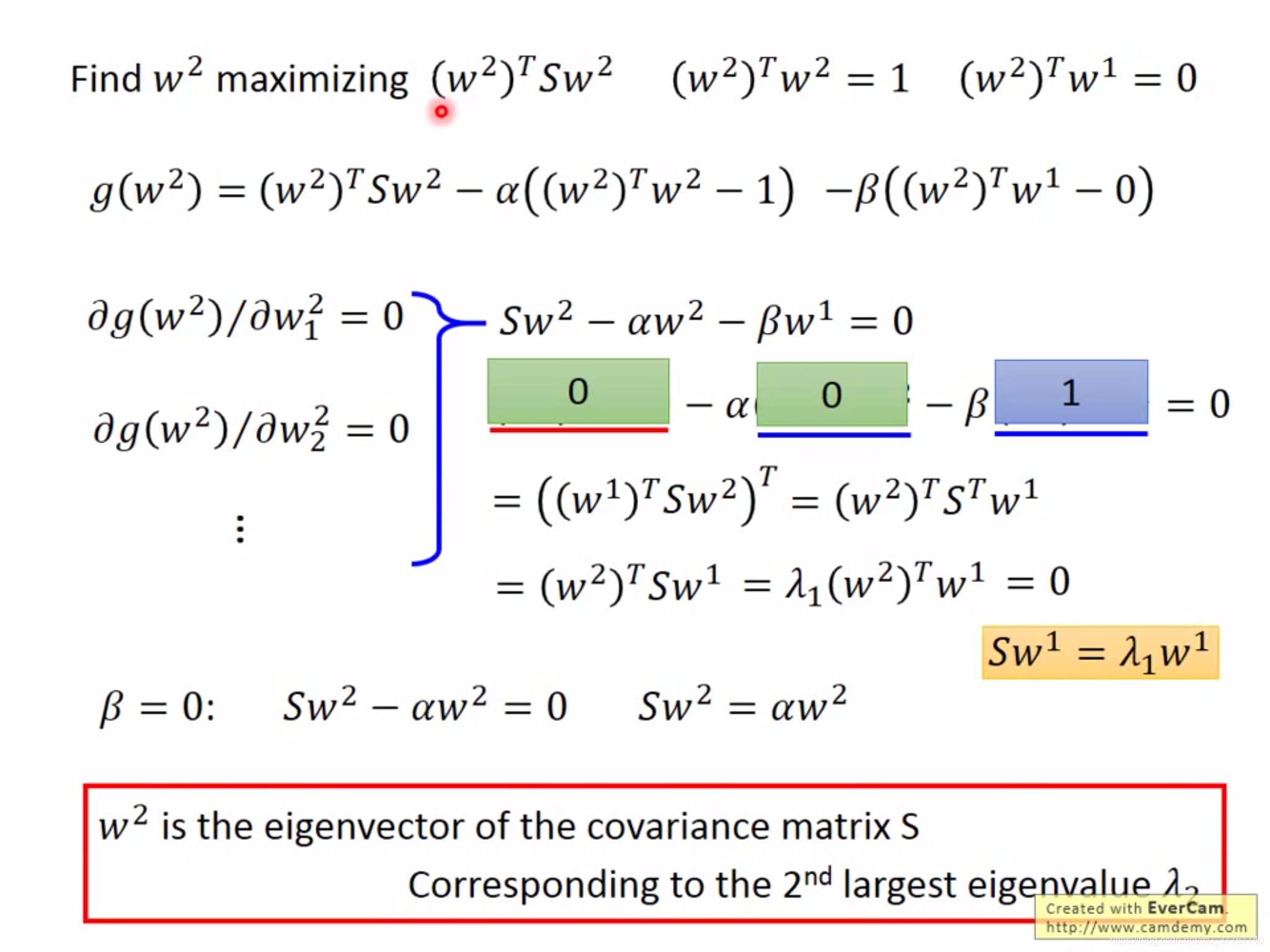
(3)求解该优化函数,可以用neural network的方式,梯度递减;也可以用传统经典方法对这个函数进行求解,其中函数的解为协方差的最大特征值所对应的特征向量。

(4)求解下一个维度,其中下一个维度的解为协方差矩阵所对应的第二大的特征值所对应的特征向量,因为协方差矩阵的特征向量依次正交。
(5)PCA decorrelation:投影后数据在新的坐标的Cov各个维度之间是不相关的,也就是矩阵对角线外都为0,这样在做实现模型的时候可以减少参数,比如高斯假设的时候,各轴之间相关为0,那么减少了很多参数。
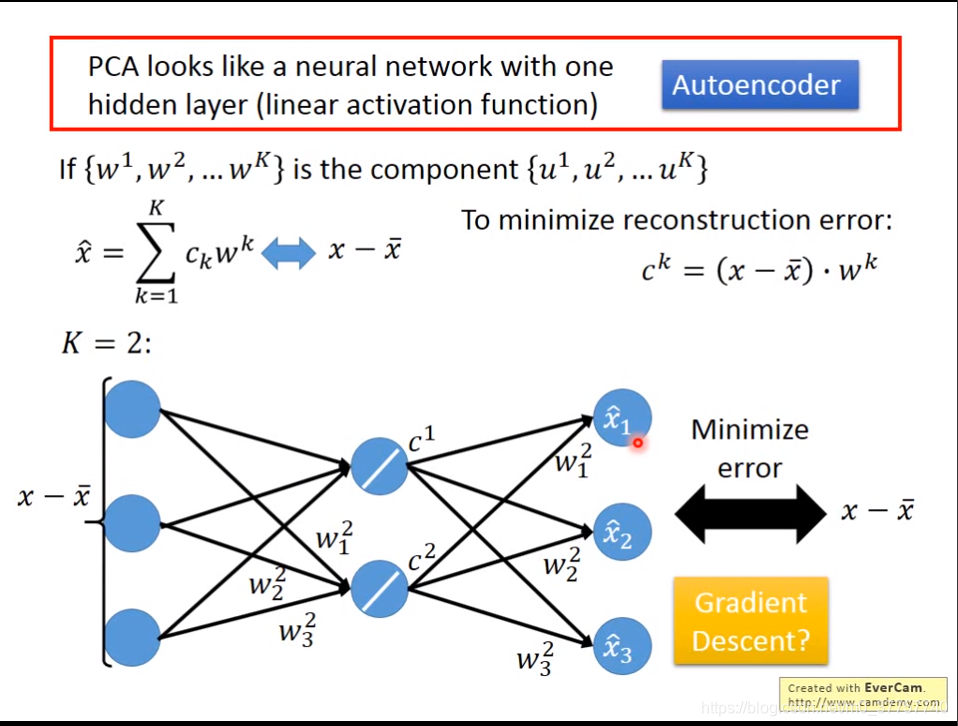
(6)另外一种解释方法就是,用多个component来线性表示原来的样本,最小化reconstruction error,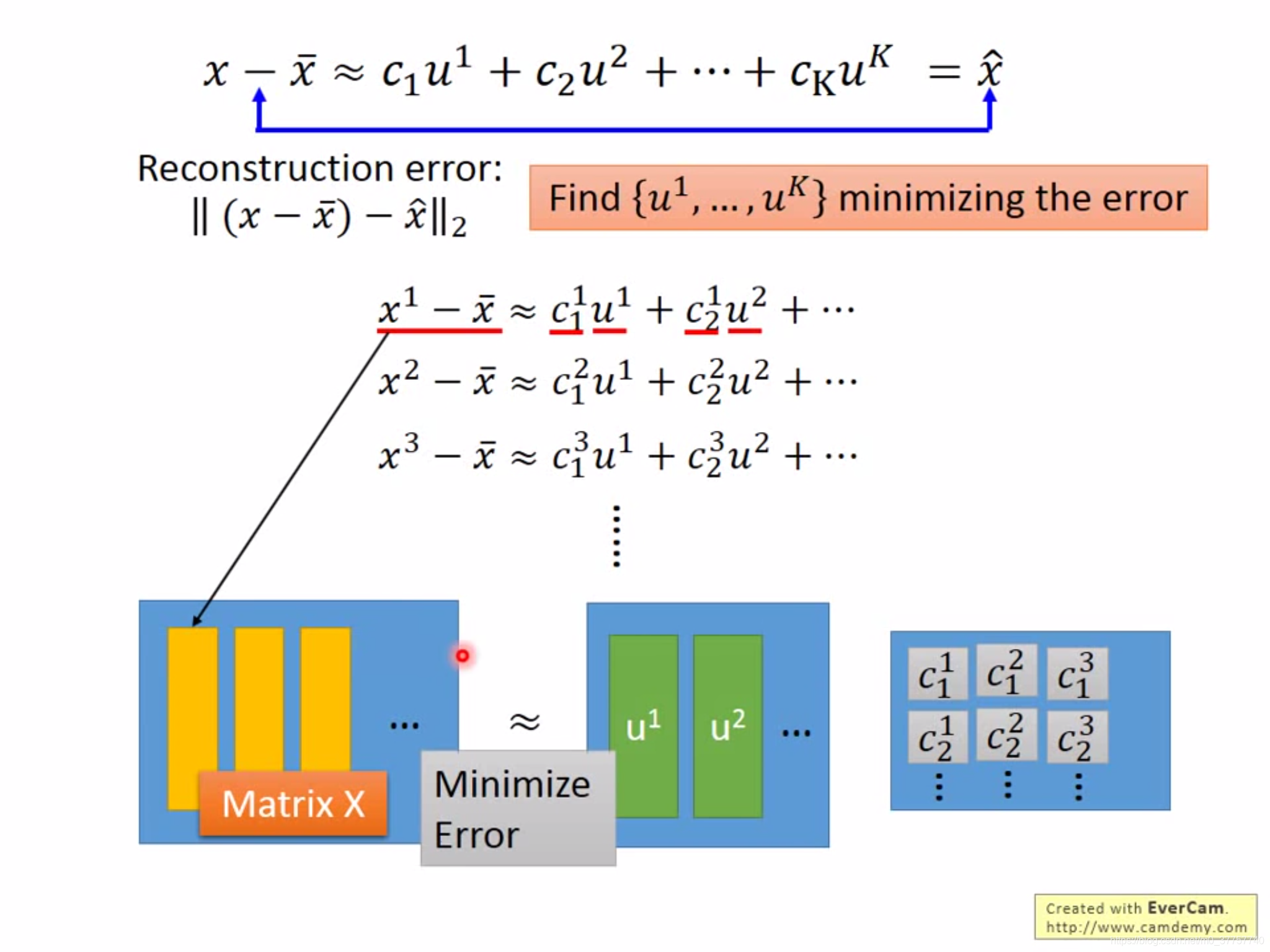
最后利用svd求解方程,得到的U矩阵就是协方差矩阵的k个特征向量
(6)由于w之间时互相正交的,所以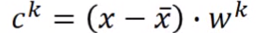 ,也就是说c可以表示成这两者的乘积,PCA由此呢,也可以看成是Autoencoder,即具有一层隐含层的神经网络(线性激活函数),即输入和输出之间的误差越小越好。如果不是传统的PCA的方法,只用neural network的解法不能够保证w之间是垂直的。但是如果用网络的话,可以用deep autoencode。
,也就是说c可以表示成这两者的乘积,PCA由此呢,也可以看成是Autoencoder,即具有一层隐含层的神经网络(线性激活函数),即输入和输出之间的误差越小越好。如果不是传统的PCA的方法,只用neural network的解法不能够保证w之间是垂直的。但是如果用网络的话,可以用deep autoencode。
(7)PCA的缺点:
a.如果是PCA的话,只能将所有样本映射到方差最大的维度上,但是这种方式可能使得不同label的样本重合在一起,难以区分。可以用LDA(Linear Discriminate Analysis)考虑,不过这种方式是supervised Learning。
b.PCA的另外一个缺点就是线性的,PCA难以将S型曲面拉直,只是会将曲面压扁,但是仍然会存在不同label样本的重合。
 (8)计算每个维度上的variance,然后看每个维度上variance所占的比重,取前几个占有较大比重特征就好了。PCA的component不一定是样本的一部分,有可能包含了整个样本或者与样本完全不一样的东西,但是它们的线性组合可以构成一个样本。这种现象可以用NMF来解决。
(8)计算每个维度上的variance,然后看每个维度上variance所占的比重,取前几个占有较大比重特征就好了。PCA的component不一定是样本的一部分,有可能包含了整个样本或者与样本完全不一样的东西,但是它们的线性组合可以构成一个样本。这种现象可以用NMF来解决。

推荐算法中的MF方法,可以解释成用户和物品的隐含因子的匹配程度r = p*q+e,e表示reconstruction error,可以用svd来求解。如果存在缺失值的话,可以迭代求解。
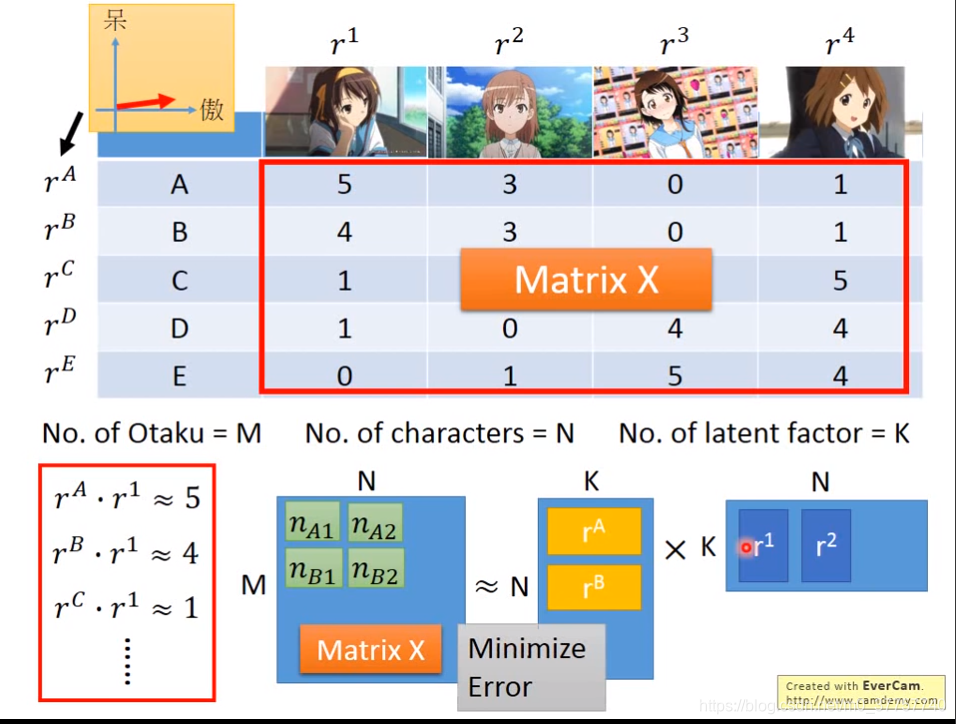

矩阵分解可以加入偏移向量,可能结果会更加准确。

PCA的其他变形版本MDS(只需要样本之间的距离进行降维,保留了高维空间中的版本)、PPCA、KPCA、CCA(两种不同的source),ICA(用Independant vector),LDA(supervised Learning)。
