一.jieba库初识
jieba是Python中的一个重要的第三方中文分词函数库
#以下是jieba库的简单运用:

二.jieba库的安装
1、下载jieba库:https://pypi.org/project/jieba/
2、将其解压到某一文件夹下:
3、运行cmd,进入jieba-0.39文件夹:

4、执行命令:python3 setup.py install 回车
5、测试jieba是否安装成功(运行出现分词,则安装成功,结果如下:)
输入import jieba没有问题,安装成功。
三.jieba库常用的分词函数
1.jieba.cut(s) 精准模式,返回一个可迭代的数据类型
2.jieba.cut(s,cut_all=True) 全模式,输出文本s中所有可能的单词
3.jieba.cut_for_search(s) 搜索引擎模式,适合搜索引擎建立索引的分词结果
4.jieba.lcut(s) 精准模式,返回一个列表类型,建议使用
5.jieba.lcut(s,cut_all=True) 全模式,返回一个列表类型,建议使用
6.jieba.cut_for_search(s) 搜索引擎模式,返回一个列表类型,建议使用
7.jieba.add_word(w) 向分词词典中增加新词w
四.文本词频条统计
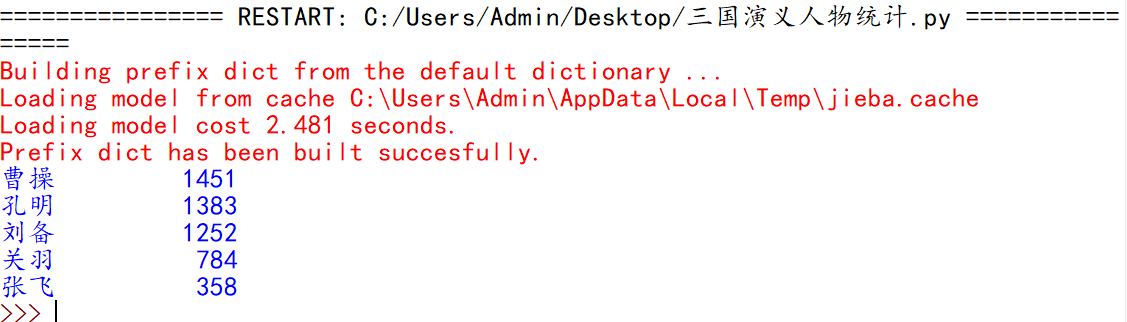
《三国演义》人物出场统计
首先从网上下载《三国演义》文本
1 #三国演义人物出场次数统计 2 import jieba 3 excludes = {"将军","却说","荆州","二人","不可","不能","如此","商议","军士","如何", 4 "主公","军马","左右",} 5 txt = open("./三国演义.txt", "r", encoding='utf-8').read() 6 words = jieba.lcut(txt) 7 counts = {} 8 for word in words: 9 if len(word) == 1: 10 continue 11 elif word == "诸葛亮" or word == "孔明曰": 12 rword = "孔明" 13 elif word == "关公" or word == "云长": 14 rword = "关羽" 15 elif word == "玄德" or word == "玄德曰": 16 rword = "刘备" 17 elif word == "孟德" or word == "丞相": 18 rword = "曹操" 19 else: 20 rword = word 21 counts[rword] = counts.get(rword,0) + 1 22 for word in excludes: 23 del counts[word] 24 items = list(counts.items()) 25 items.sort(key=lambda x:x[1], reverse=True) 26 for i in range(5): 27 word, count = items[i] 28 print ("{0:<10}{1:>5}".format(word, count))
运行结果如下:
《三国演义》文本下载:
链接:https://pan.baidu.com/s/1FfDO9H8nczSLBkTHxPIINg
提取码:nfw6
复制这段内容后打开百度网盘手机App,操作更方便哦