文章目录
- 一、TFRecords输入数据格式
- 二、图像数据处理
- 1、TF图像处理函数
- (1)图像编码处理
- (2)图像大小处理
- a、通过算法使得新的图像尽量保存原始图像上所有的信息。
- b、对图像裁剪或填充——`tf.image.resize_image_with_crop_or_pad`函数
- c、比例调整图像大小——`tf.image.entral_crop`函数
- d、剪裁或填充给定区域的图像——`tf.image.crop_to_bounding_box`函数和`tf.image.pad_to_bounding_box`函数
- (3)图像翻转
- (4)图像色彩调整
- 2、图像预处理实例
- 三、多线程输入数据处理框架
- 四、数据集(DataSet)
目标:如何对图像数据进行预处理使得训练得到的神经网络模型尽可能小地被无关因素所影响。同时,为减小预处理对训练速度的影响,使用多线程处理。
一、TFRecords输入数据格式
TF统一存储数据的格式:TFRecords,二进制文件,可更好利用内存、便于复制和移动,且不需要单独的标签文件。
1、TFRecord格式介绍
TFRecord 文件中的数据都是通过 tf.train.Example协议内存块(Protocol Buffer)(协议内存块包含了字段Features)的格式存储的。
tf.train.Example定义:
message Example {
Features features = 1;
};
message Features {
map<string, Feature> feature = 1;
};
message Feature {
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
tf.train.Example 中包含了一个从属性名称到取值的字典。
其中属性名称为一个字符串,属性的取值可以为字符串(BytesList)、实数列表 (FloatList)或者整数列表( Int64List)。
比如将一张解码前的图像存为一个字符串,图像所对应的类别编号存为整数列表。在2中将给出 一个使用 TFRecord 的具体样例 。
数据存储:将数据填入到 Example 协议内存块(protocol buffer),将协议内存块序列化为一个字符串, 并且通过tf.python_io.TFRecordWriter 写入到 TFRecords 文件。
从TFRecords文件中读取数据, 可以使用tf.TFRecordReader的tf.parse_single_example解析器。这个操作可以将Example协议内存块(protocol buffer)解析为张量。
2、TFRecord样例程序
(1)生成TFRecords文件
将MNIST输入数据转换为TFRecord的格式
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 生成整数型的属性。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 生成字符串型的属性。
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
DATASET_PATH = '/home/jie/Jie/codes/tf/datasets/MNIST_DATA'
mnist = input_data.read_data_sets(DATASET_PATH, dtype=tf.uint8, one_hot=True)
images = mnist.train.images
# 训练数据所对应的正确答案,可以作为一个属性保存在 TFRecord 中
labels = mnist.train.labels
# 训练数据的图像分辨率,这可以作为 Example 中的一个属性。
pixels = images.shape[1]
num_example = mnist.train.num_example
# 输出 TFRecord 文件的地址。
filename = '/home/jie/Jie/codes/tf/datasets/MNIST_DATA/output.tfrecords'
# 创建一个 writer 来写 TFRecord 文件。
writer = tf.python_io.TFRecordWriter(filename)
for index in range(num_example):
# 将图像矩阵转化成一个字符串。
image_raw = images[index].tostring()
# 将一个样例转化为 Example Protocol Buffer ,并将所有的信息写入这个数据结构。
example = tf.train.Example(features=tf.train.Features(features={
'pixels':_int64_feature(pixels),
'label':_int64_feature(np.argmax(labels[index])),
'image_raw':_bytes_features(images_raw)}))
# 将一个 Example 写入 TFRecord 文件。
writer.write(example.SerializeToString())
writer.close()
当数据量较大时,也可以将数据写入多个 TFRecord 文件。
(2)读取TFRecord文件
import tensorflow as tf
# 输出 TFRecord 文件的地址。
filename = '/home/jie/Jie/codes/tf/datasets/MNIST_DATA/output.tfrecords'
# 创建一个 reader 来读取 TFRecord 文件中的样例。
reader = tf.TFRecordReader()
# tf.train.string_input_producer 创建一个队列来维护输入文件列表
filename_queue = tf.train.string_input_producer([filename])
# 从文件中读取一个样例。也可以使用 read_up_to 函数-次性读取多个样例。
_, serialized_example = reader.read(filename_queue)
# 解析读入的一个样例。若需要解析多个样例,可用parse_example函数
features = tf.parse_single_example(
serialized_example,
features={
# TensorFlow 提供两种不同的属性解析方法。
# 1. tf.FixedLenFeature,所解析的结果为一个 Tensor。
# 2. tf.VarLenFeature,所得到的解析结果为SparseTensor,用于处理稀疏数据。
# 这里解析数据的格式需要和上面程序可入数据的格式一致。
'image_raw':tf.FixedLenFeature([], tf.string),
'pixels':tf.FixedLenFeature([], tf.int64),
'label':tf.FixedLenFeature([], tf.int64),
})
# tf.decode_raw 可以将字符串解析成图像对应的像索数组。
image = tf.decode_raw(features['image_raw'], tf.uint8)
label = tf.cast(features['label'], tf.int32)
pixels = tf.cast(features['pixels'], tf.int32)
sess = tf.Session()
# 启动多线程处理输入数据
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 每次运行可以读取 TFRecord 文件中的一个样例。
# 当所有样例都读取完之后,在此样例中程序会再重头读取
for i in range(10):
print(sess.run([image, label, pixels]))
二、图像数据处理
目标:可以尽量避免模型受到无关因素的影响。在大部分图像识别中,通过预处理过程可以提高模型的准确率。
1、TF图像处理函数
(1)图像编码处理
RGB三维矩阵( jpeg 和 png 格式) 《==》 编码/解码
# -*-coding:utf-8-*-
import tensorflow as tf
import matplotlib.pyplot as plt
IMAGES_PATH = '/home/jie/Desktop/6987985.jpeg'
SAVE_PATH = '/home/jie/Desktop/output.jpeg'
# 读取图像的原始数据。
image_raw_data = tf.gfile.FastGFile(IMAGES_PATH, 'rb').read()
with tf.Session() as sess:
# 对图像进行 jpeg 的格式解码从而得到图像对应的三维矩阵。
# tf.image.decode_png 函数对 png 格式的图像进行解码。
# 解码之后的结果为一个张量,在使用它的取值之前需要明确调用运行的过程。
img_data = tf.image.decode_jpeg(image_raw_data)
print(img_data.eval())
# 输出解码之后的三维矩阵,上面这一行代码将输出以下内容。
# 使用 pyplot 工具可视化得到的图像。
plt.imshow(img_data.eval())
plt.show()
# 将表示一张图像的三维矩阵重新按照jpeg格式编码并存入文件中。
# 打开该图像,与原始图像一样
encoded_image = tf.image.encode_jpeg(img_data)
with tf.gfile.GFile(SAVE_PATH, "wb") as f:
f.write(encoded_image.eval())
输出结果
[[[ 11 7 0]
[ 29 25 22]
[ 32 33 38]
...
[ 29 31 28]
[ 19 21 20]
[ 5 7 2]]
[[ 38 31 15]
[191 184 174]
[213 213 213]
...
[209 214 217]
[183 187 188]
[ 32 37 33]]
[[ 19 44 51]
[200 228 242]
[153 189 215]
...
[188 201 209]
[210 218 221]
[ 24 33 32]]
...
[[ 56 34 23]
[245 217 196]
[125 87 42]
...
[ 77 74 65]
[214 215 209]
[ 36 37 32]]
[[ 20 30 40]
[177 184 190]
[211 216 212]
...
[217 216 214]
[185 185 183]
[ 27 27 25]]
[[ 6 6 4]
[ 29 29 27]
[ 29 33 32]
...
[ 29 30 32]
[ 32 32 32]
[ 1 1 1]]]

(2)图像大小处理
由于很多网络输入节点的个数是固定的,所以需要先将图像的大小统一。
图像大小调整有两种方法:
a、通过算法使得新的图像尽量保存原始图像上所有的信息。
TF的 tf.image.resize_images 函数提供四种不同的方法
# 略去加载原始图像,定义会话等过程,假设:img_data是已经解码的图像。
# 1. 首先将图片数据转换为实数类型,即将0-255转化为0.0-1.0范围内的实数。
# 大多数图像处理 API 支持整数和实数类型的输入。
# 如果输入是整数类型,这些 API 会在内部将输入转化为实数后处理,再将输出转化为整数。
# 如果有多个处理步骤,在格数和实数之间的反复转化将导致精度损失,
# 因此推荐在图像处理前将其转化为实数类型。
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
# 通过 tf.image.resize_images 函数调整图像的大小。
# 第一个参数: 原始图像
# 第二个和第三个参数为调整后图像的大小
# method 参数给出了调整图像大小的算法
resized = tf.image.resize_images(img_data, [300, 300], method=0)
plt.imshow(resized.eval())
plt.show()
| method取值 | 图像大小调整算法 |
|---|---|
| 0 | 双线性插值法(Bilinear interpolation) |
| 1 | 最近邻插值(Nearest neighbor interpolation) |
| 2 | 双三次插值法(Bicubic interpolation) |
| 3 | 面积插值法(Area interpolation) |
==》不同算法效果差别不大
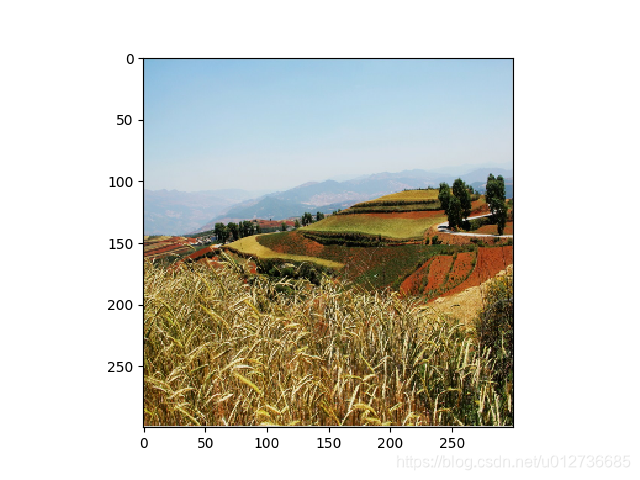
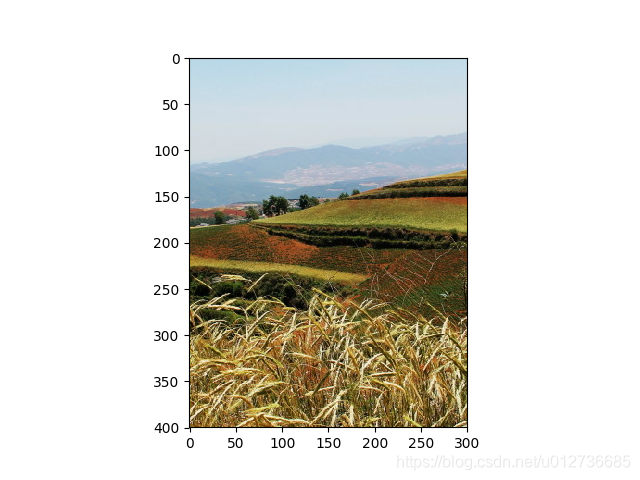
b、对图像裁剪或填充——tf.image.resize_image_with_crop_or_pad函数
# 通过 tf.image.resize_image_with_crop_or_pad 函数调整图像的大小。
# 第一个参数: 原始图像
# 第二个和第三个参数为调整后的目标图像大小。
# 如果原始图像的尺寸大于大于目标图像,则该函数会自动截取y你是图像中居中的部分。
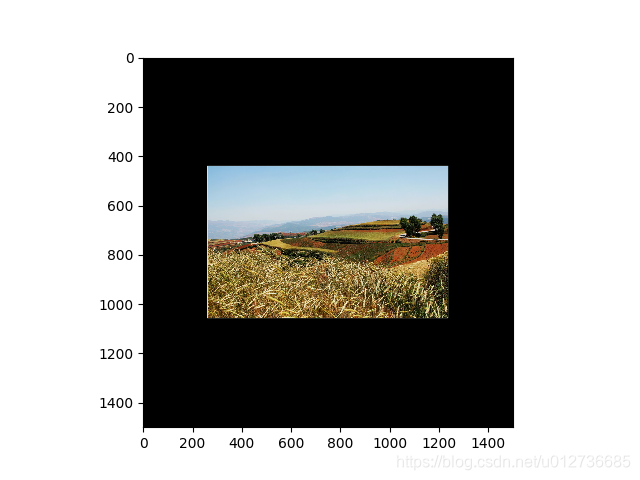
# 若目标图像大于原始图像,则会自动在原始图像的四周填充全0背景。
croped = tf.image.resize_image_with_crop_or_pad(img_data, 400, 300)
padded = tf.image.resize_image_with_crop_or_pad(img_data, 1500, 1500)
plt.imshow(croped.eval())
plt.show()
plt.imshow(padded.eval())
plt.show()
c、比例调整图像大小——tf.image.entral_crop函数
# 第一个参数为原始图像, 第二个参数为调整比例,这个比例需要是-个(0, 1]的实数
central_cropped = tf.image.central_crop(img_data, 0.25)
plt.imshow(central_cropped.eval())
plt.show()

d、剪裁或填充给定区域的图像——tf.image.crop_to_bounding_box函数和tf.image.pad_to_bounding_box函数
这两个函数都要求给出的尺寸满足一定的要求,否则程序会报错。比如在使用 tf.image.crop_to_bounding_box 函数时, TensorFlow 要求提供的图像尺寸要大于目标尺寸,也就是要求原始图像能够裁剪出目标图像的大小。
(3)图像翻转
功能:上下翻转、左右翻转以及沿对角线翻转
# 将图像上下翻转
flipped1 = tf.image.flip_up_down(img_data)
# 将图像左右翻转
flipped2 = tf.image.flip_left_right(img_data)
# 将图像沿对角线翻转
flipped3 = tf.image.transpose_image(img_data)
plt.subplot(221)
plt.imshow(img_data.eval())
plt.subplot(222)
plt.imshow(flipped1.eval())
plt.subplot(223)
plt.imshow(flipped2.eval())
plt.subplot(224)
plt.imshow(flipped3.eval())
plt.show()
输出结果
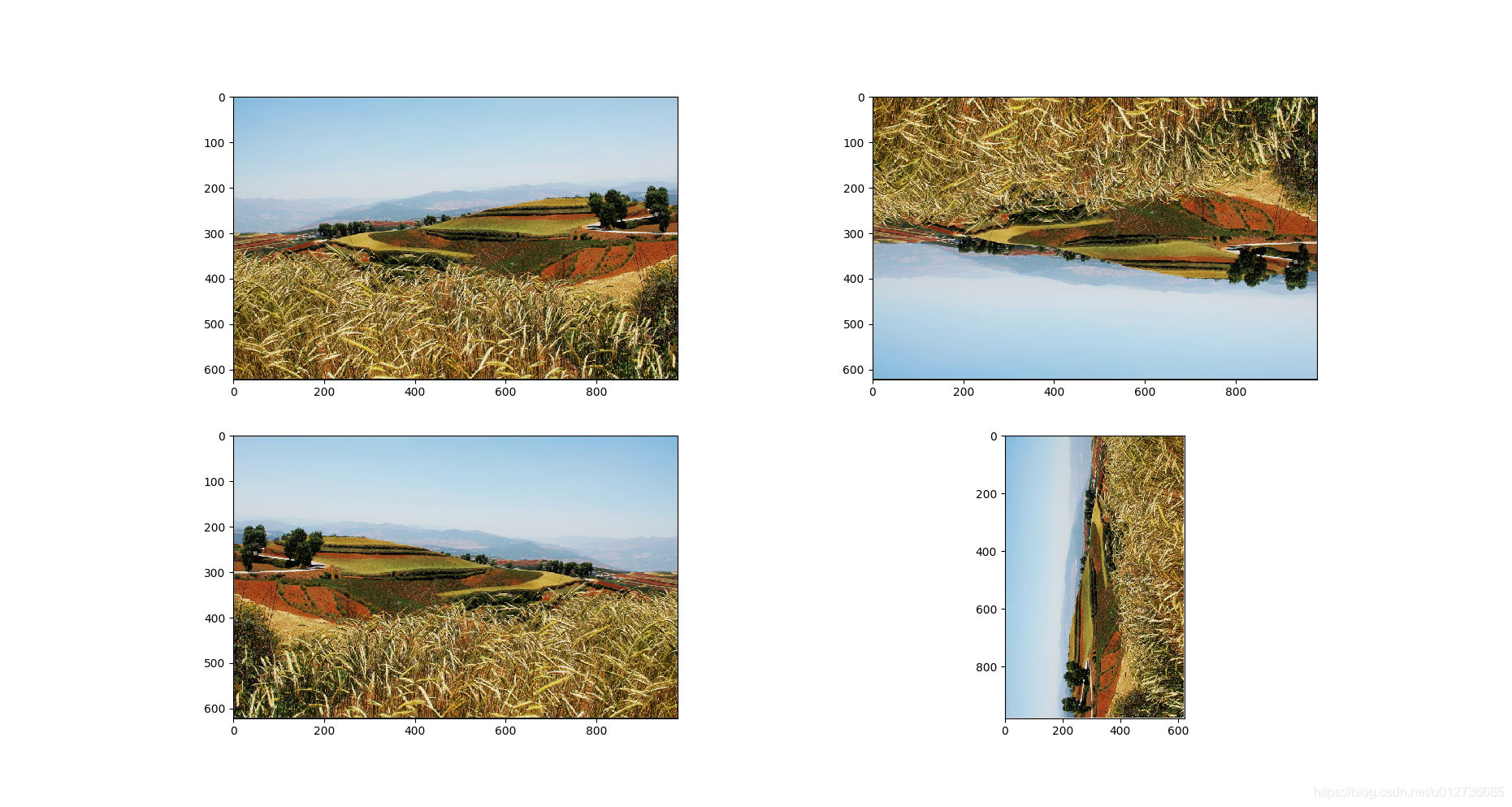
在很多图像识别问题中,图像的翻转不会影响识别的结果。
==》训练得到的模型可以识别不同角度的实体
==》随机翻转训练图像是一种很常用的图像预处理方式。
# 以 50% 概率上下翻转图像
flipped1 = tf.image.random_flip_up_down(img_data)
# 以 50% 概率左右翻转图像
flipped2 = tf.image.random_flip_left_right(img_data)
(4)图像色彩调整
调整图像的亮度、对比度、饱和度和色相,在很多图像识别应用中不会影响识别结果。
==》随机调整这些属性,使得训练的模型尽可能小地受无关因素的影响。
a、调整亮度
tf.image.adjust_brightness()函数和tf.image.random_brightness()函数
注意:
- 色彩调整的 API 可能导致像素的实数值超出
0.0-1.0的范围。在输出最终图像前需要将其值截断在0.0-1.0范围区间,否则不仅图像无法正常可视化,以此为输入的神经网络的训练质量可能受到影响。 - 若对图像进行多项处理操作,则截断应在最后一步
# 将图像的亮度 -0.5
adjusted1 = tf.image.adjust_brightness(img_data, -0.5)
# 截断在 0.0-1.0 范围区间
adjusted1 = tf.clip_by_value(adjusted1, 0.0, 1.0)
# 将图像的亮度 +0.5
adjusted2 = tf.image.adjust_brightness(img_data, 0.5)
# 在[-max_delta, max_delta)的范围随机调整图像的亮度。
max_delta = 0.9
adjusted3 = tf.image.random_brightness(img_data, max_delta)

b、调整对比度
tf.image.adjust_contrast()函数和tf.image.random_contrast()函数
# 将图像的对比度减少到 0.5 倍
adjusted1 = tf.image.adjust_contrast(img_data, 0.5)
# 将图像的对比度增加 5 倍
adjusted2 = tf.image.adjust_contrast(img_data, 5)
# 在[lower, upper] 的范围随机调整图像的对比度。
lower = 10
upper = 100
adjusted3 = tf.image.random_contrast(img_data, lower, upper)

c、调整色相
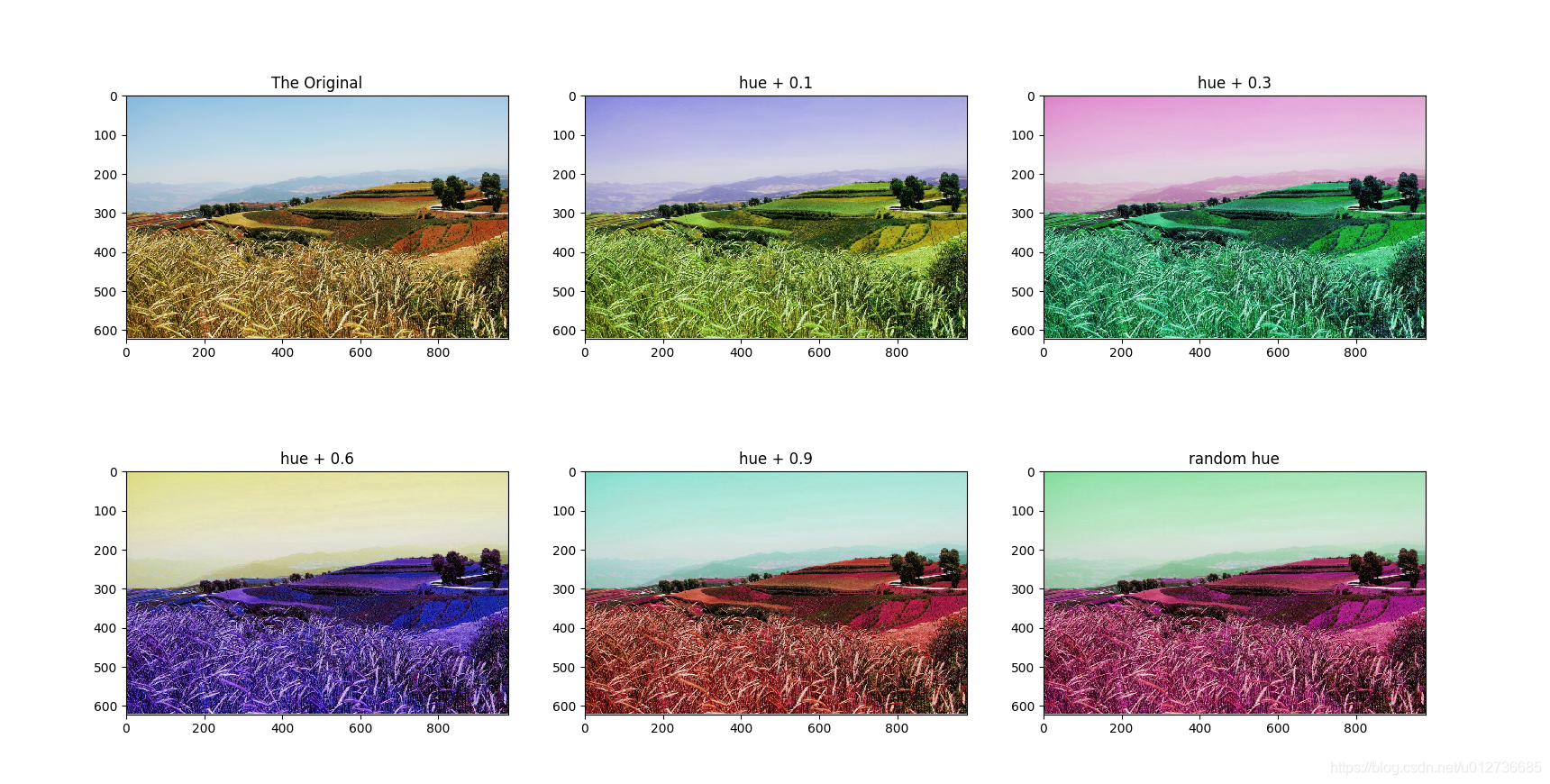
tf.image.adjust_hue函数和tf.image.random_hue函数
# 分别将色相加 0.1、0.3、0.6 和 0.9
adjusted1 = tf.image.adjust_hue(img_data, 0.1)
adjusted2 = tf.image.adjust_hue(img_data, 0.3)
adjusted3 = tf.image.adjust_hue(img_data, 0.6)
adjusted4 = tf.image.adjust_hue(img_data, 0.9)
# 在 [-max_delta, max_delta] 的范围随机调整图像的色相。
max_delta = 0.5
adjusted5 = tf.image.random_hue(img_data, max_delta)
注意:max_delta最大为 0.5
d、调整饱和度
tf.image.adjust_saturation函数和tf.image.random_saturation函数
# 将图像的饱和度-5
adjusted1 = tf.image.adjust_saturation(img_data, -5)
# 将图像的饱和度+5
adjusted2 = tf.image.adjust_saturation(img_data, 5)
# 在[lower, upper] 的范围随机调整图像的饱和度
lower = 10
upper = 100
adjusted3 = tf.image.random_saturation(img_data, lower, upper)

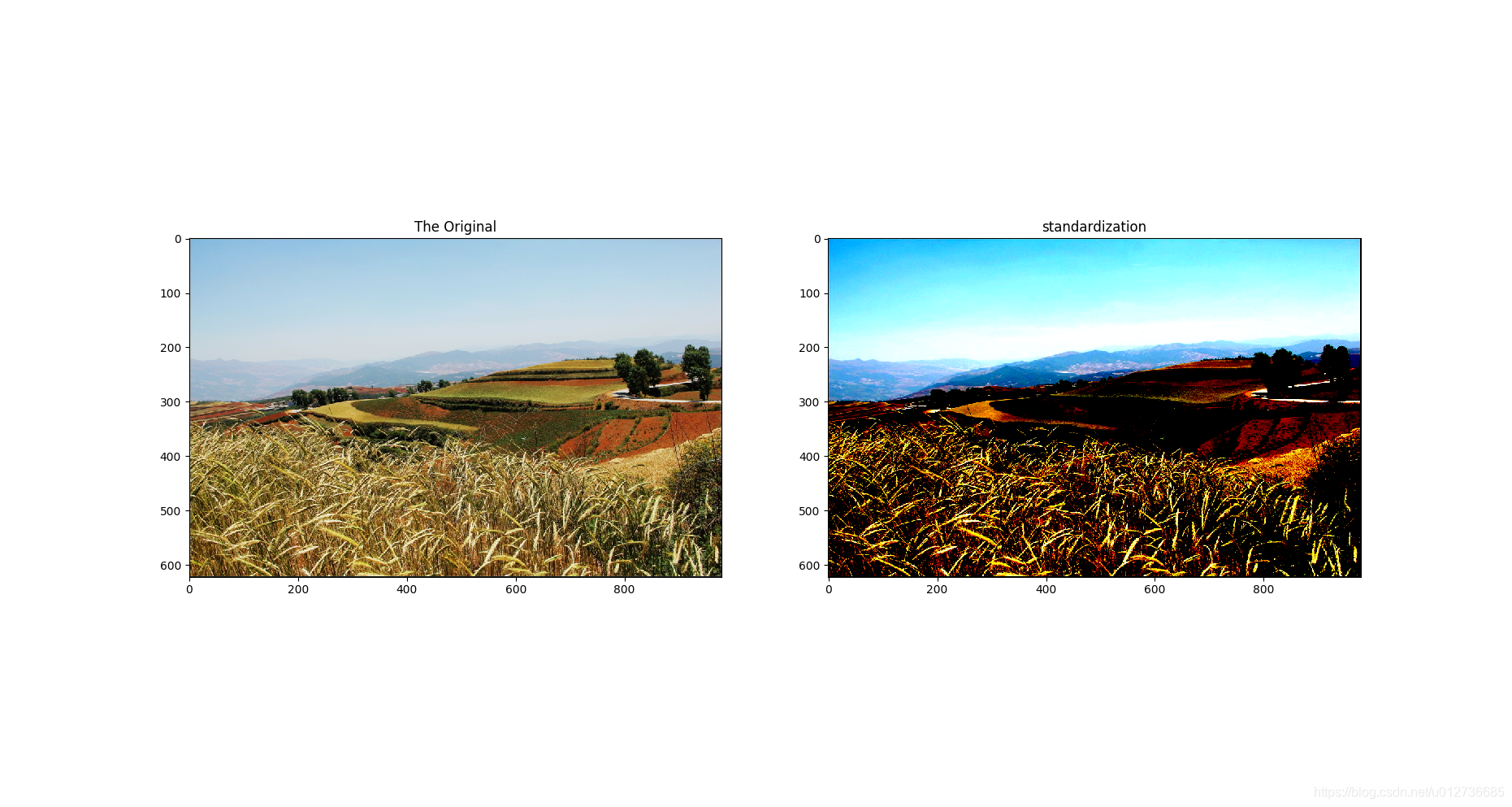
e、图像标准化
tf.image.per_image_standardization() :函数将图像上的亮度均值变为0,方差变为1。
adjusted = tf.image.per_image_standardization(img_data)
f、处理标注框(bounding box)
tf.image.draw_bounding_boxes()函数在图像中添加标注框。输入图像矩阵的数字为实数,且是一个 batch 的数据(四维张量)。所以,绘制图时,需要tf.reduce_sum()函数进行降维。
# 将图像缩小一些,这样可视化能让标注框更加清楚。
img_data = tf.image.resize_images(img_data, [180, 267], method=1)
# tf.image.draw_bounding_boxes 函数要求图像矩阵中的数字为实数.
# -> 先将图像矩阵转化为实数类型。
# 输入是一个 bacth 的数据(多张图像组成的四维矩阵),要将解码之后的图像矩阵添加一维
bacthed = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0)
# 给出每一张图像的所有标注框。一个标注框有 4 个数字,分别代表[Y_min, X_min, Y_max, X_max]
# 注意这里给出的数字都是图像的相对位置。
# 比如在 180 × 267 的图像中,[0.35, 0.47, 0.5, 0.56]代表了从(63,125)到(90, 150)的图像。
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
result = tf.image.draw_bounding_boxes(bacthed, boxes)
result = tf.reduce_sum(result, 0) # 这里显示的时候需要进行降维处理
plt.imshow(result.eval())
plt.show()

注:bounding box位置不准,仅用于学习。
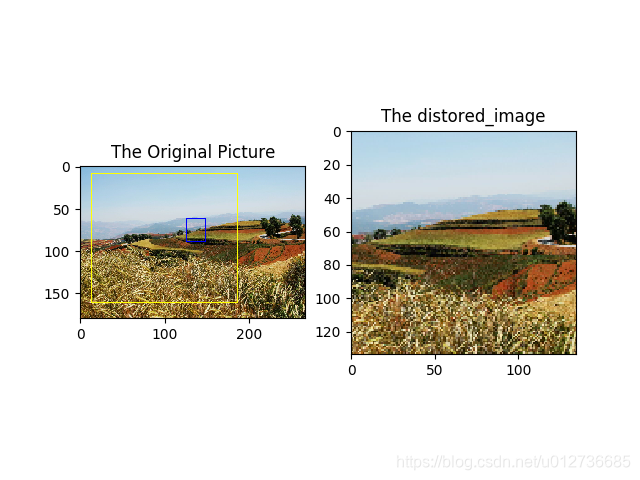
g、随机截取图像
随机截取图像上有信息含量的部分也是一个提
高模型健壮性( robustness )的一种方式。
==》使得训练模型不受被识别物体大小的影响。
==》tf.image.sample_distorted_bounding_box()函数
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
# min_object_covered=0.4 表示截取部分至少包含某个标注框 40% 的内容。
begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
tf.shape(img_data), bounding_boxes = boxes,
min_object_covered=0.4)
# 通过标注框可视化随机截取得到的图像。
bacthed = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0)
image_with_box = tf.image.draw_bounding_boxes(bacthed, bbox_for_draw)
# 截取随机出来的图像。每次结果可能不尽相同.
distored_image = tf.slice(img_data, begin, size)
2、图像预处理实例
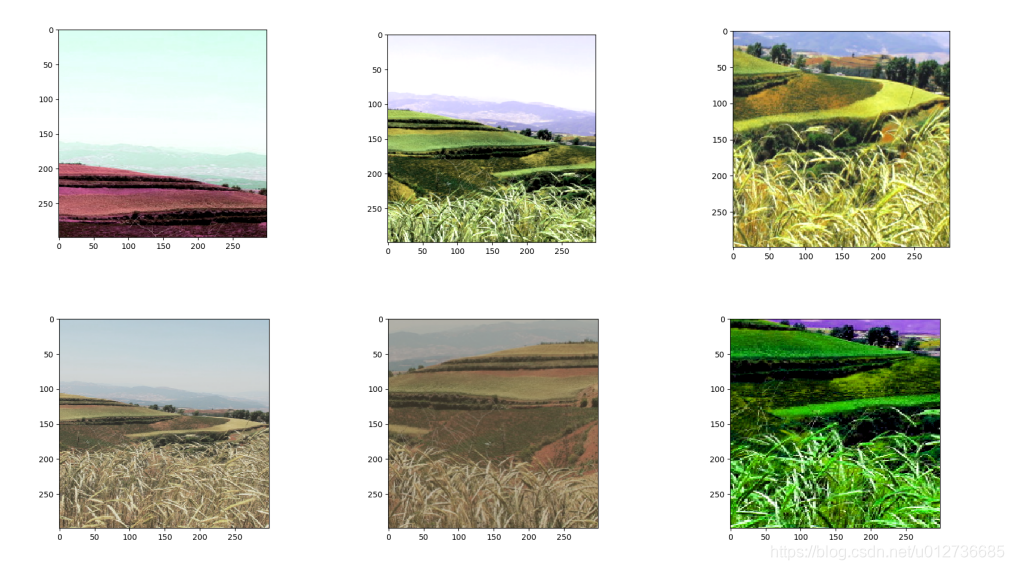
在解决真实的图像识别问题时, 一般会同时使用多种处理方法。
本实例展示:将不同的图像处理函数结合成一个完成的图像预处理流程。从图像片段截取,到图像大小调整再到图像翻转及色彩调整的整个图像预处理过程。
- 调整亮度、对比度、饱和度和色相的顺序会影响最后的结果,所以定义多种不同的顺序。
- 注意:数据预处理只针对训练数据,而非测试数据
输入:原始训练图像
输出:神经网络的输入层
# -*-coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 给定一张图像,随机调整图像的色彩。
# 因为调整亮度、对比度、饱和度和色相的顺序会影响最后的结果,所以定义多种不同的顺序。
# 具体顺序可在预处理时随机选取一种。从而降低无关因素对模型的影响。
# 亮度(brightness) 对比度(contrast)、饱和度(saturation)和色相(hue)
def distort_color(image, color_ordering=0):
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32./255.) #
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
elif color_ordering == 1:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
elif color_ordering == 2:
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
# 截断在 0.0-1.0 范围区间
return tf.clip_by_value(image, 0.0, 1.0)
# 给定一张解码后的图像、目标图像的尺寸以及图像上的标注框,
# 此函数可对给出的图像进行预处理
# 输入:原始训练图像
# 输出:神经网络的输入层
def preprocess_for_train(image, height, width, bbox):
# 如果没有提供标注框,则认为整个图像就是需要关注的部分。
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32,
shape=[1, 1, 4])
# 转换图像张量的类型 。
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 随机截取图像,减小需要关注的物体大小对图像识别算法的影响。
bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box(
tf.shape(image), bounding_boxes=bbox)
distorted_image = tf.slice(image, bbox_begin, bbox_size)
# 将随机截取的图像调整为神经网络输入层的大小。大小调整的算法是随机选摔的 。
distorted_image = tf.image.resize_images(
distorted_image, [height, width], method=np.random.randint(4))
# 随机左右翻转图像。
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 使用一种随机的顺序调整图像色彩。
distorted_image = distort_color(distorted_image, np.random.randint(3))
return distorted_image
IMAGE_PATH = '/home/jie/Desktop/6987985.jpeg'
image_raw_data = tf.gfile.FastGFile(IMAGE_PATH, "rb").read()
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
for i in range(6):
result = preprocess_for_train(img_data, 299, 299, boxes)
plt.imshow(result.eval())
plt.show()
三、多线程输入数据处理框架
复杂的预处理过程会减慢整个训练的过程,所以为了避免预处理成为神经网络模型训练效率的瓶颈,TF提供多线程处理输入数据的框架。
经典输入流程:
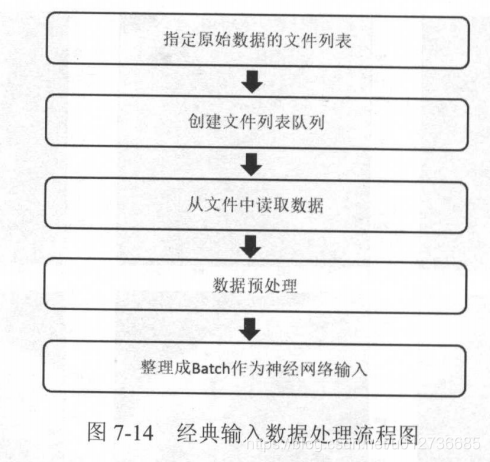
1、队列与多线程
在TF中,队列也是计算图上有状态的节点,修改队列状态的操作主要有 Enqueue、EnqueueMany和Dequeue。
(1)两种队列
FIFOQueue:先进先出队列。RandomShuffleQueue:将队列中的元素打乱,每次出队列操作得到的是从当前队列所有元素中随机选择的一个。(训练网络时希望每次使用的训练数据尽可能随机,推荐使用)
import tensorflow as tf
# 创建一个先进先出队列,指定队列中最多可以保存两个元素,并指定类型为整数。
q = tf.FIFOQueue(2, "int32")
# enqueue_many 函数:初始化队列中的元素,需要明确的调用这个初始化过程。
init = q.enqueue_many(([0, 10],))
# Dequeue 函数:队列中的第一个元素出队列,并存入x中
x = q.dequeue()
y = x + 1
# 将y重新加入队列。
q_inc = q.enqueue([y])
with tf.Session() as sess:
# 运行初始化队列的操作。
init.run()
for _ in range(5):
# 运行q_inc将执行数据出队列、出队的元素+1、重新归入队列的整个过程。
v, _ = sess.run([x, q_inc])
print(v)
输出结果
0
10
1
11
2
TF中,队列还是异步计算张量取值的一个重要机制。例:多个线程可同时向一个队列中写入或读取元素。
(2)多线程协同方法1:tf.Coordinator 类
tf.Coordinator类:用于协同多个线程一起停止, 并提供了 should_stop、request_stop 和 join 三个函数。
工作过程:
- 在启动线程之前,需要先声明一个
tf.Coordinator类,并将这个类传入每一个创建的线程中。 - 启动的线程需要一直查询
tf.Coordinator类中提供的should_stop函数, 为True时,则 当前线程也需要退出 。 - 每一个启动的线程都可以通过调用
request_stop函数来通知其他线程退出。当 某一个线程调用request_stop函数之后 ,should_stop函数的返回值将被设置为True,这样其他的线程就可以同时终止了。
# 线程中运行的程序,这个程序每隔1秒判断是否需要停止并打印向己的ID 。
def MyLoop(coord, worker_id):
# 使用 tf.Coordinator 类提供的协同工具判断当前线程是否要停止。
while not coord.should_stop():
# 随机停止所有的线程。
if np.random.rand() < 0.1:
print("Stoping from id: %d\n" % worker_id)
# 调用 coord.request_stop() 函数来通知其他线程停止。
coord.request_stop()
else:
# 打印当前线程的Id。
print("Working on id: %d\n" % worker_id)
time.sleep(1)
# 声明一个 tf.train.Coordinator 类来协同多个线程。
coord = tf.train.Coordinator()
# 声明创建 5 个线程
threads = [threading.Thread(target=MyLoop, args=(coord, i)) for i in range(5)]
# 启动所有线程
for t in threads:
t.start()
# 等待所有线程退出
coord.join(threads)
输出
Working on id: 0
Working on id: 1
Working on id: 2
Working on id: 3
Working on id: 4
Stoping from id: 0
Working on id: 2
Working on id: 3
分析:主与所有线程启动之后,每个线程会打印各自的 ID,于是前面 4 行打印出了它们的 ID 。然后在暂停 1 秒之后,所有线程又开始第二遍打印 ID。 在这个时候有一个线程退出的条件达到,于是调用了 coord.request_stop 函数来停止所有其他的线程。 然而在打印 Stoping from id: 0 之后,可以看到有线程仍然在输出。这是因为这些线程已经执行完coord.should_stop的判断,于是仍然会继续输出自己的 ID 。 但在下一轮判断是否需要停止时将退出线程。 于是在打印一次 ID 之后就不会再有输出了。
(3)多线程协同方法2:tf.QueueRunner 类
tf.QueueRunner类:用于启动多个线程来操作同一个队列,启动的这些线程可以通过上面介绍的 tf.Coordinator 类来统一管理
# 声明一个先进先出的队列,队列中最多100个元素,类型是实数
queue = tf.FIFOQueue(100, "float")
# 定义队列的入队操作
enqueue_op = queue.enqueue([tf.random_normal([1])])
# 使用 tf.train.QueueRunner 创建多个线程运行队列的入队操作。
# 第1个参数:被操作的队列,
# [enqueue_op]*5 需要启动5个线程,每个线程中运行的是 enqueue_op 操作。
qr = tf.train.QueueRunner(queue, [enqueue_op] * 5)
# 将定义过的QueueRunner加入TensorFlow 计算图上指定的集合。
# tf.train.add_queue_runner 函数没有指定集合,则加入默认集合 tf.GraphKeys.QUEUE_RUNNERS。
# 下面的函数就是将刚刚定义的 qr 加入默认的 tf.GraphKeys.QUEUE_RUNNERS 集合。
tf.train.add_queue_runner(qr)
# 定义出队操作。
out_tensor = queue.dequeue()
with tf.Session() as sess:
# 使用 tf.train.Coordinator 来协同启动的线程。
coord = tf.train.Coordinator()
# 使用tf.train.QueueRunner时,需要明确调用tf.train.start_queue_runners来启动所有线程。
# 否则因为没有线程运行入队操作,当调用出队操作时,程序会一直等待入队操作被运行。
# tf.train.start_queue_runners 函数会默认启动tf.GraphKeys.QUEUE_RUNNERS集合中所有的QueueRunner。
# 这个函数只支持启动指定集合中的 QueueRnner,
# 所以一般来说 tf.train.add_queue_runner 函数和tf.train.start_queue_runners函数会指定同一个集合。
threads = tf.train.start_queue_runners(sess = sess, coord=coord)
# 获取队列中的取值。
for _ in range(3):
print(sess.run(out_tensor)[0])
# 使用 tf.train.Coordinator 来停止所有的线程。
coord.request_stop()
coord.join(threads)
输出结果
-1.475753
-0.27835137
2.2407255
2、输入文件队列
虽然一个TFRecord文件可以存储多个训练样本,但当训练数据量较大时,可以将数据分成多个TFRecord文件来提高处理效率。
- 获取一个正则表达式的所有文件:
tf.train.match_filenames_once - 进行有效的管理:
tf.train.string_input_producer
该函数会使用初始化时提供的文件列表创建一个输入队列,输入队列中的原始元素为文件列表中的所有文件,创建好的输入队列可以作为文件读取函数的参数,每层调用文件读取函数时,该函数会先判断当前是否已经有打开的文件可读,如果没有或者打开的文件已经读完,则该函数会从输入队列中出队一个文件并从该文件中读取数据。
- 当
shuffle=True时,文件在加入队列之前会被打乱顺序,所以出队顺序也是随机的;- 随机打乱文件顺序以及加入输入队列的过程是一个单独的线程,不会影响获取文件的速度。
- 当输入队列中的所有文件都被处理完之后,会将初始化时提供的文件列表中的文件全部重新加入队列。
num_epochs:限制加载初始文件列表的最大轮数- 当设置为1时,计算完一轮之后,程序将自动停止。
- 神经网络模型测试时,所有测试数据仅仅需要使用一次即可,所以将其设置为1。
# 创建 TFRecord 文件的帮助函数。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 模拟海量数据情况下将数据写入不同文件
# num_shards : 总共写入多少个文件,
# instances_per_shard : 每个文件中有多少个数据。
num_shards = 2
instances_per_shard = 2
for i in range(num_shards):
# 将数据分为多个文件时,可以将不同文件以类似 OOOOn-of-OOOOm 的后缀区分。
# m:表示数据总共被存在了多少个文件中
# n:表示当前文件的编号
# 式样的方式既方便了通过正则表达式获取文件列表,又在文件名中加入了更多的信息
filename = ('./datasets/data.tfrecords-%.5d-of-%.5d' % (i, num_shards))
writer = tf.python_io.TFRecordWriter(filename)
# 将数据封装成 Example 结构并写入 TFRecord 文件 。
for j in range(instances_per_shard):
# Example 结构仅包含当前样例属于第几个文件以及是当前文件的第几个样本。
example = tf.train.Example(features=tf.train.Features(feature={
'i':_int64_feature(i),
'j':_int64_feature(j)}))
writer.write(example.SerializeToString())
writer.close()
每一个文件中存储了两个样例 。

生成样例之后,以下代码展示了两个函数的使用方法
# 使用 tf.train.match_filenames_once 函数获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 通过 tf.train.string_input_producer 函数创建输入队列.
# 输入队列巾的中的文件列表为tf.train.string_input_producer函数获取的文件列表。
# 参数设置:shuffle为False,在一般解决真实问题时,shuffle设置为True
filename_queue = tf.train.string_input_producer(files, shuffle=False)
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'i':tf.FixedLenFeature([], tf.int64),
'j':tf.FixedLenFeature([], tf.int64),
})
with tf.Session() as sess:
# 虽然在本段程序中没有声明任何变量,
# 但使用 tf.train.match_filenames_once 函数时前要初始化一些变量 。
tf.local_variables_initializer().run()
print(sess.run(files))
# 声明 tf.train.Coordinator 类来协同不同线程,并启动线程。
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 多次执行技取数据的操作。
for i in range(6):
print(sess.run([features['i'], features['j']]))
coord.request_stop()
coord.join(threads)
输出结果
[b'./datasets/data.tfrecords-00000-of-00002'
b'./datasets/data.tfrecords-00001-of-00002']
[0, 0]
[0, 1]
[1, 0]
[1, 1]
[0, 0]
[0, 1]
3、组合训练数据(batching)
将多个输入样例组织成一个batch可以提高模型训练的效率,所以在得到单个样例的预处理结果之后,还需要将其组织成batch,再提供给神经网络的输入层。
tf.train.batch和tf.train.shuffle_batch函数来将单个的样例组织成 batch 的形式输出。这两个函数都会生成一个队列,队列的入队操作是生成单个样例的方法,而每次出队得到的是一个 batch 的样例 。- 唯一区别:是否会将数据顺序打乱 。
tf.train.shuffle_batch为乱序。
(1)tf.train.batch
import tensorflow as tf
# 使用 tf.train.match_filenames_once 函数获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 通过 tf.train.string_input_producer 函数创建输入队列.
# 输入队列巾的中的文件列表为tf.train.string_input_producer函数获取的文件列表。
# 参数设置:shuffle为False,在一般解决真实问题时,shuffle设置为True
filename_queue = tf.train.string_input_producer(files, shuffle=False)
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'i':tf.FixedLenFeature([], tf.int64),
'j':tf.FixedLenFeature([], tf.int64),
})
# 使用上面样例。这里假设 Example 结构中 i 表示一个样例的特征向量,
# 比如一张图像的像索矩阵。而 j 表示该样例对应的标签 。
example, label = features['i'], features['j']
# 一个 batch 中样例的个数。
batch_size = 3
# 文件队列中最多可以存储的样例个数
capacity = 1000 + 3 * batch_size
# 使用 tf.train.batch 函数来组合样例。[example, label]参数给出需组合的元素.
# 当队列长度等于容量时,TF将暂停入队操作,而只是等待元索出队。
# 当元素个数小于容量时, TF将自动重新启动入队操作。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=batch_size, capacity=capacity)
with tf.Session() as sess:
# tf.initialize_all_variables().run()
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 获取并打印组合之后的样例。在真实问题中,这个输出一般会作为神经网络的输入。
for i in range(2):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
print(cur_example_batch, cur_label_batch)
coord.request_stop()
coord.join(threads)
报错:因为使用match_filenames_once需要用local_variables_initializer初始化局部变量(local variables)没有初始化
- 局部变量初始化:
tf.local_variables_initializer().run()
OutOfRangeError (see above for traceback): FIFOQueue '_1_batch/fifo_queue' is closed and has insufficient elements (requested 3, current size 0)
[[Node: batch = QueueDequeueManyV2[component_types=[DT_INT64, DT_INT64], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/device:CPU:0"](batch/fifo_queue, batch/n)]]
输出结果
[0 0 1] [0 1 0]
[1 0 0] [1 0 1]
# tf.train.batch 函数可以将单个的数据组织成3个一组的batch
# 在example,lable中读到的数据依次为:
example:0, lable:0
example:0, lable:1
example:1, lable:0
example:1, lable:1
# 这是因为函数不会随机打乱顺序,所以组合之后得到的数据组合成了上面给出的输出
(2)tf.train.shuffle_batch
tf.train.shuffle_batch 代码示例如下:
import tensorflow as tf
# 获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 创建文件输入队列
filename_queue = tf.train.string_input_producer(files, shuffle=False)
# 读取并解析Example
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'i':tf.FixedLenFeature([], tf.int64),
'j':tf.FixedLenFeature([], tf.int64),
})
# i代表特征向量,j代表标签
example, label = features['i'], features['j']
# 一个 batch 中样例的个数。
batch_size = 3
# 文件队列中最多可以存储的样例个数
capacity = 1000 + 3 * batch_size
# 组合样例。
# `min_after_dequeue` 是该函数特有的参数,参数限制了出队时队列中元素的最少个数,
# 但当队列元素个数太少时,随机的意义就不大了
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size,
capacity=capacity, min_after_dequeue=30)
with tf.Session() as sess:
# 使用match_filenames_once需要用local_variables_initializer初始化一些变量
tf.local_variables_initializer().run()
# 用Coordinator协同线程,并启动线程
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 获取并打印组合之后的样例。在真实问题中,这个输出一般会作为神经网络的输入。
for i in range(2):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
print(cur_example_batch, cur_label_batch)
coord.request_stop()
coord.join(threads)
输出结果
[0 0 0] [1 1 0]
[0 0 1] [1 1 0]
4、输入数据处理框架
框架主要是三方面的内容:
- TFRecord 输入数据格式
- 图像数据处理
- 多线程输入数据处理
import tensorflow as tf
# 获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 创建文件输入队列
filename_queue = tf.train.string_input_producer(files, shuffle=False)
# 读取并解析Example
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'image':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([], tf.int64),
'height':tf.FixedLenFeature([], tf.int64),
'width':tf.FixedLenFeature([], tf.int64),
'channels':tf.FixedLenFeature([], tf.int64),
})
image, label = features['image'], features['label']
height, width = features['height'], features['width']
channels = features['channels']
# 从原始图像数据解析出像素矩阵,并根据图像尺寸还原图像。
decoded_image = tf.decoded_raw(image, tf.int8)
decoded_image.set_shape([height, width, channels])
# 定义神经网络输入层图片的大小。
image_size = 299
# 图像预处理
distorted_image = preprocess_for_train(decoded_image, image_size, image_size, None)
# 将处理后的图像和标续数据通过 tf.train.shuffle_batch 整理成神经网络训练时需要的 batch,
min_after_dequeue = 10000
batch_size = 100
capacity = min_after_dequeue + 3 * batch_size
# 组合样例。
# `min_after_dequeue` 是该函数特有的参数,参数限制了出队时队列中元素的最少个数,
# 但当队列元素个数太少时,随机的意义就不大了
image_batch, label_batch = tf.train.shuffle_batch(
[distorted_image, label], batch_size=batch_size,
capacity=capacity, min_after_dequeue=min_after_dequeue)
# 定义神经网络的结构以及优化过程
learing_rate = 0.01
logit = inferenece(image_batch)
loss = calc_loss(logit, label_batch)
train_step = tf.train.GradientDescentOptimizer(learing_rate).minimize(loss)
with tf.Session() as sess:
# 使用match_filenames_once需要用local_variables_initializer初始化一些变量
sess.run((tf.global_variables_initializer(), tf.local_variables_initializer()))
# 用Coordinator协同线程,并启动线程
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 神经网络训练过程
TRAINING_ROUNDS = 5000
for i in range(TRAINING_ROUNDS):
sess.run(train_step)
coord.request_stop()
coord.join(threads)
5、总结
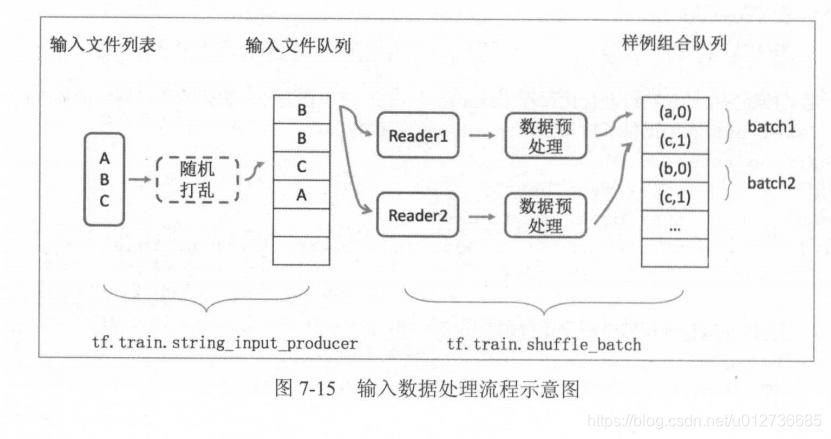
对于输入数据的处理,大体上流程都差不多,可以归结如下:
- 将数据转为 TFRecord 格式的多个文件
- 用 tf.train.match_filenames_once() 创建文件列表(图中为{A,B,C})
- 用 tf.train.string_input_producer() 创建输入文件队列,可以将输入文件顺序随机打乱,并加入输入队列(是否打乱为可选项,该函数也会生成并维护一个输入文件队列,不同进程中的文件读取函数可以共享这个输入文件队列)
- 用 tf.TFRecordReader() 读取文件中的数据
- 用 tf.parse_single_example() 解析数据
- 对数据进行解码及预处理
- 用 tf.train.shuffle_batch() 将数据组合成 batch
- 将 batch 用于训练
四、数据集(DataSet)
TF核心组件:tf.data。数据集框架中,每一个数据来源被抽象为一个数据集,以数据集为基本对象,方便地进行 batching、随机打乱( shuffle)等操作。
1、数据集的基本使用方法
由于训练数据通常无法全部写入内存中,从数据集中读取数据时需要使用一个迭代器( iterator)按顺序进行读取,数据集也是计算图上的一个节点。
(1)tensor -> 数据集
示例:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出 的值。
import tensorflow as tf
# 1.定义数据集构造方法:从-个数组创建数据集
input_data = [1, 2, 3, 5, 8]
dataset = tf.data.Dataset.from_tensor_slices(input_data)
# 2.定义一个迭代器用于遍历数据集
# 因为数据集定义时未用placeholder作为参数,则此处用one_shot_iterator()
iterator = dataset.make_one_shot_iterator()
# 3.返回一个输入数据的张量
x = iterator.get_next()
y = x * x
with tf.Session() as sess:
for i in range(len(input_data)):
print(sess.run(y))
输出结果
1
4
9
25
64
数据集读取数据有三个基本步骤:
- 定义数据集的构造方法:eg:
tf.data.Dataset.from_tensor_slices - 定义遍历器;
- 使用
get_next()方法从遍历器中读取数据张量,作为计算图其他部分的输入。
(2)文本文件 -> 数据集
tf.data.TextLineDataset()函数
TXT_FILE1 = './datasets/Text/1.txt'
TXT_FILE2 = './datasets/Text/2.txt'
input_files = [TXT_FILE1, TXT_FILE2]
dataset = tf.data.TextLineDataset(input_files)
# 定义一个迭代器用于遍历数据集
iterator = dataset.make_one_shot_iterator()
# 返回一个字符串类型的张量,代表文件中的一行。
x = iterator.get_next()
with tf.Session() as sess:
# 循环的次数为文档中总共的行数,否则会报错
for i in range(3):
print(sess.run(x))
结果输出
b'HELLO'
b'MY FRIENDS!'
b'AHHAHA'
(3)TFRecord -> 数据集
TFRecordDataset()函数读取 TFRecord 形式的数据(常为图像数据),因为每个 TFRecord 都有自己不同的 feature 格式,因此在读取时,需提供一个 parse 函数进行解析。
# 解析一个 TFRecord 的方法。record是从文件中读取的一个样例。
def parser(record):
# 解析读入的一个样例。
features = tf.parse_single_example(
record,
features={
'feat1': tf.FixedLenFeature([], tf.int64),
'feat2': tf.FixedLenFeature([], tf.inp64)
})
return features['feat1'], features['feat2']
# 从 TFRecord 文件创建数据集
FILE1_PATH = ''
FILE2_PATH = ''
input_files = [FILE1_PATH, FILE2_PATH]
dataset = tf.dataset.TFRecordDataset(input_files) # 二进制的数据
# map()函数表示对数据集中的每一条数据进行调用相应方法。
# 通过 map() 来调用 parser() 对二进制数据进行解析。
dataset = dataset.map(parser)
# 定义一个迭代器用于遍历数据集
iterator = Dataset.make_one_shot_iterator()
# feat1, feat2 是 parser() 返回的一维int64型张量,可以作为输入用于进一步的计算。
feat1, feat2 = iterator.get_next()
with tf.Session() as sess:
for i in range(10):
f1, f2 = sess.run([feat1, feat2])
注意:
- 使用
one shot_iterator时,数据集的所有参数必须已经确定,因此不需要特别的初始化过程。 - 使用
placeholder初始化数据集,则需用initializable_iterator动态初始化数据集。如下所示
# 解析一个 TFRecord 的方法。record是从文件中读取的一个样例。
def parser(record):
# 解析读入的一个样例。
features = tf.parse_single_example(
record,
features={
'feat1': tf.FixedLenFeature([], tf.int64),
'feat2': tf.FixedLenFeature([], tf.inp64)
})
return features['feat1'], features['feat2']
FILE1_PATH = ''
FILE2_PATH = ''
# 从 TFRecord 文件创建数据集,具体文件路径是一个 placeholder,稍后再提供路径。
input_files = tf.placeholder(tf.string)
dataset = tf.data.TFRecordDataset(input_files)
dataset = dataset.map(parser)
# 定义遍历 dataset 的 initializable_iterator.
iterator = dataset.make_initializable_iterator()
feat1, feat2 = iterator.get_next()
with tf.Session() as sess:
# 首先初始化 interator,并给出 input_files 的值。
sess.run(iterator.initializer,
feed_dict={input_files: [FILE1_PATH, FILE2_PATH]})
# 遍历所有数据一个epoch。当遍历结束时,程序会抛出 OutOfRangeError。
while True:
try:
sess.run([feat1, feat2])
except tf.errors.OutOfRangeError as e:
break
上述示例通过使用placeholder和feed_dict的方式传给数据集。
注意:上面的循环体不是指定循环10次sess.run,而是使用while(True)try-except的形式来将所有数据遍历一遍(即一个epoch),因为在动态指定输入数据时,不同数据来源的数据量大小难以预知,而这个方法我们不必提前知道数据量的精确大小。
2、数据集的高层操作
(1)map操作
dataset = dataset.map(parser)
map(parser) 表示对数据集中每一条数据调用参数中指定的 parser 方法。对每一条数据进行处理后,map将处理后的数据包装成一个新的数据集返回。
map可用于对数据的任何预处理操作。
dataset = dataset.map(lambda x: preprocess_for_train(x, image_size, image_size, None))
lambda表达式的作用:将原来有4个参数的函数转化为只有1个参数的函数。第一个参数decoded_image 变成了 lambda 表达式中的 x ,后3个参数都被换成了具体的数值。注意这里的 image_size 是一个变量,有具体取值,该值需要在程序的上文中给出。
在返回的新的数据集上,可以直接继续调用其他高层操作,比如预处理、shuffle、batch等操作。==》更加干净简洁
(2)shuffle 和 batch 操作
dataset = dataset.shuffle(buffer_size) # 随机打乱顺序
dataset = dataset.batch(batch_size) # 将数据组合成batch
其中buffer_size相当于tf.train.shuffle_batch 的 min_after_dequeue 参数。shuffle 算法在内部使用一个缓冲区中保存 buffer_size 条数据,每读入一条新数据时,从这个缓冲区中随机选择一条数据进行输出。缓冲区的大小越大,随机的性能越好,但占用的内存也越多 。
batch方法中的 batch_size 参数表示要输出的每个 batch 由多少条数据组成
(3)repeat 操作
作用:将数据集中的数据复制多份,其中每一份数据被称为一个 epoch。
dataset = dataset.repeat(N) # 将数据集重复 N 份
注意:如果数据集在 repeat 前己经进行了 shuffle 操作,输出的每个 epoch 中随机 shuffle 的结果并不会相同 。repeat 和 map 、shuffle 、batch 等操作一样,都只是计算图中的一个计算节点 。repeat 只代表重复相同的处理过程,并不会记录前一个epoch的处理结果。
(4)其他操作
concatenate():将两个数据集顺序连接起来;take(N):从数据集中读取前N项数据;skip(N):在数据集中跳过前N项数据;flap_map():从多个数据集中轮流读取数据。
(5)示例
从文件中读取原始数据,进行预处理、shuffle、batching 等操作,并通过 repeat 方法训练多个 epoch。此外,测试集和训练集做了不同的预处理。在训练时,调用上小节中的 preprocess_for_train 方法对图像进行随机反转等预处理操作;而在测试时,测试数据以原本的样子直接输入测试。
对数据依次进行预处理、shuffle、batching操作
import tensorflow as tf
import tempfile
# 1. 列举输入文件
TRAIN_PATH = 'output.tfrecords'
TEST_PATH = 'output_test.tfrecords'
train_files = tf.train.match_filenames_once(TRAIN_PATH)
test_files = tf.train.match_filenames_once(TEST_PATH)
# 2. 定义parser方法TFRecord中解析数据
# 解析一个TFRecord的方法。
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw':tf.FixedLenFeature([],tf.string),
'pixels':tf.FixedLenFeature([],tf.int64),
'label':tf.FixedLenFeature([],tf.int64)
})
decoded_images = tf.decode_raw(features['image_raw'],tf.uint8)
retyped_images = tf.cast(decoded_images, tf.float32)
images = tf.reshape(retyped_images, [784])
labels = tf.cast(features['label'],tf.int32)
#pixels = tf.cast(features['pixels'],tf.int32)
return images, labels
image = 299 # 定义神经网络输入层图片的大小
batch_size = 100 # 定义组合数据 batch 的大小
shuffle_buffer = 10000 # 定义随机打乱数据时buffer大小
# 定义读取训练集和测试集
dataset = tf.data.TFRecordDataset(train_files)
dataset = dataset.map(parser)
# 对数据依次进行预处理、shuffle、batching操作
# dataset = dataset.map(
# lambda image, label: (
# preprocess_for_train(image, image_size, image_size, None), label))
dataset = dataset.shuffle(shuffle_buffer).batch(batch_size)
# 重复NUM_EPOCHS 个epoch
NUM_EPOCHS = 10
dataset = dataset.repeat(NUM_EPOCHS)
# 定义数据集迭代器。
iterator = dataset.make_initializable_iterator()
image_batch, label_batch = iterator.get_next()
# 4. 定义神经网络结构和优化过程
def inference(input_tensor, weights1, biases1, weights2, biases2):
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
REGULARAZTION_RATE = 0.0001
TRAINING_STEP = 5000
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y = inference(image_batch, weights1, biases1, weights2, biases2)
# 计算交叉熵及其平均值
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=label_batch)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 损失函数的计算
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
regularaztion = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularaztion
# 优化损失函数
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 5. 定义测试用数据集
# 定义测试用的Dataset。
test_dataset = tf.data.TFRecordDataset(test_files)
test_dataset = test_dataset.map(parser)
test_dataset = test_dataset.batch(batch_size)
# 定义测试数据上的迭代器
test_iterator = test_dataset.make_initializable_iterator()
test_image_batch, test_label_batch = test_iterator.get_next()
# 定义测试数据上的预测结果
test_logit = inference(test_image_batch, weights1, biases1, weights2, biases2)
predictions = tf.argmax(test_logit, axis=-1, output_type=tf.int32)
# 声明会话并运行神经网络的优化过程。
with tf.Session() as sess:
# 初始化变量。
sess.run((tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 初始化训练数据的迭代器。
sess.run(iterator.initializer)
# 循环进行训练,直到数据集完成输入、抛出OutOfRangeError错误。
while True:
try:
sess.run(train_step)
except tf.errors.OutOfRangeError as e:
break
# 初始化测试数据的迭代器。
test_results = []
test_labels = []
sess.run(test_iterator.initializer)
while True:
try:
pred, label = sess.run([predictions, test_label_batch])
test_results.extend(pred)
test_labels.extend(label)
except tf.errors.OutOfRangeError as e:
break
# 计算准确率
correct = [float(y==y_) for (y, y_) in zip(test_results, test_labels)]
accuarcy = sum(correct)/len(correct)
print("Test accuarcy is: ", accuarcy)
输出结果
Test accuarcy is: 0.9005