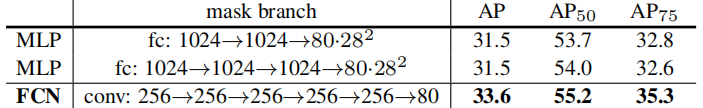论文背景
论文名称:Mask R-CNN
论文链接:https://arxiv.org/abs/1703.06870
论文日期:2018.1.24
算法背景
mask rcnn是用来进行instance segmentation,在检测物体的同时,还进行了高质量的segmentation mask,是在faster rcnn的基础上加了一个预测mask的分支,因此,最终会存在三个平行的分支,分别进行classify,location,mask,mask rcnn只是在faster rcnn的顶部加了一点小改进,运行5fps,但是可以完成更多的任务,例如识别人体的姿态。没有附加条款,mask rcnn在所有任务的存在的单一模型中表现最为出色。在Instance segmentation,bounding box object detection,person keypoint detection中表现最为出色。
mask rcnn是一个instance segmentation算法,instance segmentation不仅能分类不同的类,而且能把同一类物体中的多个不同物体分别标记出来,与semantic segmentation不同,semantic segmentation只能分割不同类型的目标,但是同一类目标没有被分别标记,是作为一个整体被检测出来。

在faster rcnn的基础上加了一个分支,可以在每一个RoI上预测segmentation masks,和classification and bounding box regression分支平行存在, mask分支是一个应用到每一个RoI上的全卷积神经网络(FCN)。
两个改进方面(在后部分将详细拓展):
-
RoIAlign
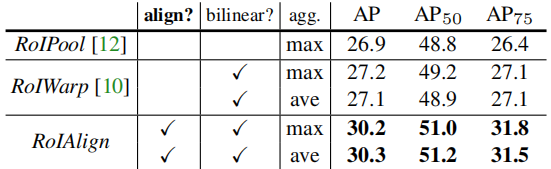
mask的分支是一个以像素到像素(pixel-to-pixel)的方式预测一个segmentation mask,而faster rcnn不是一个像素到像素的对齐,因为使用了RoIPooling,对于特征提取,表现了一个粗糙的空间量化。因此,在Mask rcnn中提出了一个新的池化方式,RoIAlign,会相对精确的保留空间定位。结果:RoIAlign对于实验结果有一个很大的改进,将Mask的准确性提升到了10%到50%,在严格定位矩阵下准确性获得了很大提升。
-
decouple mask and class prediction
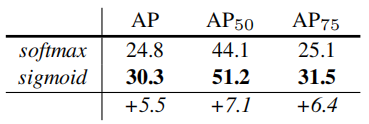
=将mask和分类分离开来,分别独立地对每一个类别预测一个二值化mask并不在类之间进行比较,依赖于神经网络的RoI的分类分支来预测类别,矛盾的是,FCN经常在单像素多类别的分类问题的使用,而这会将分割问题与分类问题连接在一起,而在我们的instance segmentation的实验中表现的很差。运行速度很快:在GPU上运行600 mspf,在COCO keypoint dataset上运行5fps。
扫描二维码关注公众号,回复: 5787041 查看本文章
早期的Instance segmentation求助于自下而上的分割方法来提取分割区域,然后再利用faster rcnn进行分类,但是运行速度慢且准确率低。而后来的 Instance-aware semantic segmentation via multi-task network cascades算法提出来了一个多阶段的方法来从候选边界框提取中预测分割候选,接着进行分类。而本文的方法是采取一个平行的预测,对mask和分类标签进行平行的预测,有两个平行的分支组成。
不同与其他许多的算法,都是用segmentation-first strategy,mask rcnn使用instance-first strategy。
mask rcnn是在faster rcnn上加了一个mask分支,因此最后损失函数由三个部分组成:
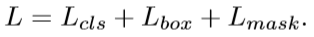
Mask分支对于每一个RoI都有一个Km*m-d的输出,K指K个类别,对于每一个类别都做一个sigmoid,判断是该物体,或者不是。而不是对所有类别一起做一个softmax。Lmask使用平均二值化交叉熵损失函数,对于每一个RoI与真实标签的类别k结合起来。Lmask仅仅只定义在第k类的mask上,(其他类别的mask对损失没有贡献),只计算单一类别的损失。
mask分支去除全连接层,只使用全卷积结构,在卷积之间有一个像素到像素的联系。不需要拉伸成为一个向量,这个会失去一些空间的特征。同时,FCN会需要更少的参数。
算法详解
RoIAlign
RoIAlign是在RoIPool的基础上进行了优化。
在原始的RoIPool算法中,当候选区域映射到feature map上时,与特征图上的像素点不匹配时,会直接使用stride进行间隔取整,进行一个平移操作,最后得到的各个grid里面的值均为整数,但是这样会导致feature map上的RoI映射回原图上时,与原图的RoI有stride有误差,这样经过max pooling后误差更大。
但是在RoIAlign算法中,我们对于每一个grid都取一个float值,对每一个grid中的值都进行一个双线性插值,对于feature map上的每一个RoI都会被分成m*m个grid,然后对每一个grid,在其中选取4个点,这4个点分别是这个格子中四个部分的中点,然后对于每一个点进行一次双线性插值计算。
双线性插值的原理:
对于RoIAlign的工作原理:
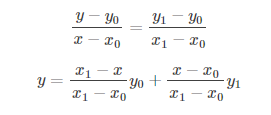
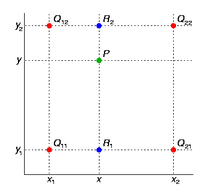
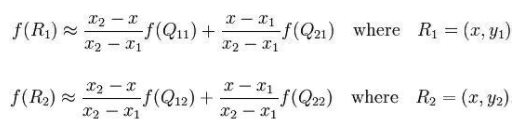

对于每个点,都取点所在的格子的四个顶点的坐标值做双线性插值,双线性插值的原理如上所示。然后进行max pooling。
神经网络结构
候选区域的提取仍然使用RPN,但是对于各个层都是用了featrue map的提取。例如ResNet,可以根据卷积的深度进行分层,总共可以分为4层,然后分别对每一层使用不同的scale,但是相同的aspect radio进行候选区域的提取,不同于faster rcnn,mask rcnn不仅有一个自下而上的卷积的过程,还有一个自上而下的上采样过程,这就是FPN的结构。


FPN

对每一层feature map分别进行候选区域的提取。
每一个自上而下的上采样实现细节,由卷积之后的特征图进行1*1的卷积然后与上一层的特征映射的使用因子为2的最近邻上采样结果进行求和。

实验
准确率有了很大提升:
将分类与分割解耦:
使用RoIAlign:
使用全卷积神经网络:
与Faster RCNN对比: