SNIP算法详解(极端尺寸检测)
论文背景
论文全称:An Analysis of Scale Invariance in Object Detection – SNIP
论文链接:https://arxiv.org/abs/1711.08189
论文日期:2018.5.25
算法背景
本文主要是对比了已有的目标检测算法,结合算法的优势,提出了本文中的SNIP算法,用于解决检测数据集上尺寸极端变化问题。
- 数据集背景:
COCO数据集中待检测物体相对图片而言,尺寸过小,而且不同对象之间的尺寸差距较大。针对此类极端尺寸变量问题,即待检测物体尺寸过小或者过大。一些分类与检测算法被提出。 - 理论基础
检测器的特定尺寸与尺寸不变性设计通过训练不同配置的输入数据来进行比较。
通过评估在ImageNet数据集上不同神经网络结构分类小尺寸对象的表现,也可以得到,CNN对于尺寸变化不鲁棒。
本文提出了一个基于相同尺寸的图片金字塔的训练与测试检测器。
由于小尺寸与大尺寸对象很难分别在较小和较大的尺寸下识别出来,本文提出了一个新的训练方案,图像金字塔的尺寸归一化(SNIP),有选择地反向传播不同尺寸的目标实例的梯度作为图像尺寸的公式。
- 优化结果
在COCO数据集上,单一模型的准确性为45.7% mAP,三个神经网络一起的准确性为48.3% mAP。使用现成的ImageNet-1000预训练模型,仅仅利用边界框监督训练。
算法详情
主要问题
在过去的几年中,分类取得了很大的进展,但是检测仍然表现不佳。因为检测数据集获取标签的代价太大。除此之外,分类数据集的目标尺寸适中,而检测数据集的对象尺寸偏小,且对象尺寸差异江大,对检测造成了很大影响,尤其是针对小目标的检测是一个很大的挑战。
检测数据集的缺点可以被归纳为两个方面:
- 对象尺寸小:ImageNet数据集与 COCO数据集目标实例尺寸的中位数分别是0.554与0.106,=意味着 COCO数据集大多数的对象面积都小于整张图片的1%。
- 对象尺寸差异大:前10%的最小对象尺寸与前10%的最大对象尺寸差异巨大, 分别是0.024与0.472。几乎是20倍。

这种尺寸异样对于神经网络的尺寸不变性性能是个极端挑战。
由于预训练是在分类数据集上进行的,分类与检测数据集的对象实例尺寸不同也导致了利用分类数据集预训练的神经网络进行微调时会有很大的域平移(domain-shift)。
已有解决方案
为了缓解待检测目标尺寸变化以及尺寸偏小的问题,有许多方法被提出:
- 将浅层的特征与深层的特征相结合,用于检测小目标实例。
- 拓展 / 变形的卷积被用来增加检测对象的感受野,用于检测大尺寸实例。
- 在不同分辨率网络层上进行的独立预测,用于检测不同尺寸的对象实例。
- 利用上下文信息来进行消歧。
- 在一个大范围的尺寸内进行训练。
- 在一个多尺寸的图片金字塔上进行推断,并且结合非极大值抑值进行预测。
研究现状
问题:
CNNs的更深层有很大的步长(32 pixels)会导致对于输入图片有个非常粗糙的表示,从而小目标的检测非常困难。
传统解决方案:
- 增加特征映射的分辨率:
- 许多目标检测器使用扩张/萎缩的卷积神经网络来增加特征映射的分辨率。拓展/变形的卷积神经网络也保留了预训练神经网络的权重与感受野,并且对于大目标的检测性能也没有下降。
- 在训练时对图片进行1.5到2倍的上采样,在推断时对图片进行4倍的上采样,这也是增加最后特征映射分辨率的一个常用方法。
- 训练方法:
- 浅层的特征映射拥有更高的分辨率,包含更完整的信息。
- 深层特征通常包含补充的信息,包含高级语义特征(conv5)。
- 独立预测:
例如SDP, SSH 或 MS-CNN,是在不同的分辨率的层上进行独立预测,也确保更小的对象在更高分辨率的层上训练(如conv3),更大的对象在更低分辨率的层上训练(如conv5)。这种方法以牺牲高级语义特性为代价提供更好的分辨率,这可能会使性能降低。 - 结合预测:
例如FPN, Mask-RCNN, RetinaNet,使用金字塔形式的表示,结合浅层与深层的特征,至少获得了更高级的语义信息。然而如果目标的尺寸为25 x 25 像素,并且训练时进行2倍的上采样,也只会得到50 x 50像素的尺寸,而经典神经网络都是在224 x 224分辨率的图片上预训练的,因此特征金字塔网络生成的高级语义特征对于分类小目标不会有用(可以对高分辨率图片中的大目标进行相似的增强)。因此,将高层特征与浅层特征相结合对于检测小目标无效。尽管特征金字塔有效地利用了网络中所有层的特征,但它们不是检测非常小/大对象的图像金字塔的有吸引力的替代方案。
- 独立预测:
- 面部检测算法:
在每一个尺寸的对象最大化池化之后,将所有的对象的梯度都反向传播,但是面部检测的变量要比目标检测少得多,因此,这个算法在应用到目标检测中有许多限制,对于每一个类别,在R-FCN算法中都要训练一个特定尺寸的卷积核。这会导致性能下降。 - 使用图片金字塔,并且使用Maxout算法在推断时从更接近于预训练数据集分辨率的尺度中选择特征。例如 SPPNet与Fast-RCNN。本文探索了训练尺度不变目标检测器的设计空间,并提出了对接近预训练网络分辨率的样本进行选择性反向传播。
思考问题
- 上采样对于目标检测获取好的表现是重要的吗?即使检测数据集的典型图片尺寸是480 x 640,为什么通常上采样至800 x 1200?能不能在ImageNet数据集中的低分辨率图片使用一个小的步长预训练神经网络,然后接着在检测数据集上进行微调来检测小目标实例?
- 当使用一个预训练的图片分类模型微调一个目标检测器时,需不需要通过对输入图片进行合适的rescale将训练目标实例的分辨率限制到一个小的范围内(从 64 x 64 到 256 x 256),或者将所有的分辨率的输入图片进行上采样之后再进行训练?
针对上述的两个问题,文章通过在ImageNet 与COCO数据集上进行了scale variation实验,测试了尺寸变化对于检测的影响。
实验显示了上采样对于检测小目标实例的重要性。
分别设计了特定尺寸的检测器与尺寸不变的检测器进行了实验:
- 特定尺寸检测器:尺寸变化问题通过对每一个尺寸范围的实例训练一个单独的检测器得到解决。
原因:在分类与检测数据集上使用相同尺寸的实例训练神经网络能减小域偏移。
缺点:特定尺寸检测器的设计也减小每个尺寸的训练样本的数量,这会导致表现下降。 - 尺寸不变的检测器:使用所有的训练样本训练单一的目标检测器会导致学习任务变难。
原因:因为神经网络需要在一个尺寸差异很大的检测实例上学习卷积核。
SNIP算法
SNIP算法在训练期间减小尺寸差异,尺寸差异问题是通过图片金字塔得到解决的,而不是尺寸不变检测器。且不需要减少训练样本。在金字塔的每一个尺寸上进行训练,能有效使用所有的训练数据
图片金字塔原理:
- 归一化图片金字塔中每一个尺寸的目标实例的输入化表示。
- 为了最小化分类神经网络在训练期间的域平移,我们只需要反向传播和预训练CNN有相近的分辨率的RoIs/anchors的梯度。
实验结果:
- SNIP算法与传统目标检测训练模式相比,准确性提高了3.5%。
- 联合Deformable-RFCN主干神经网络,在50% overlap上取得了69.7%mAP的准确率,在COCO数据集上,取得了7.4%的进步。
多尺寸图片分类器对比实验
-
训练与测试使用不同分辨率:
在训练与测试阶段使用不同分辨率的图片作为输入会导致域偏移。因为目前的前沿算法都是使用的不同分辨率的图片作为输入,通常使用800x1200像素的图片进行训练,使用金字塔中包含的1400x2000像素的输出进行推断。
获得不同像素的图片,下采样原始数据集,然后上采样至224x224,作为CNN的输入,本文进行了实验测试,使用和训练不同的分辨率进行测试显然不是最优的,至少对于分类而言。


-
使用不同结构分类网络:
在ImageNet上使用不同的步长预训练分类神经网络。如CNN-S,使用conv 3x3 stride 1,而对于CNN-B与CNN-B-FT,使用conv 7x7 stride 2。根据实验,CNN-S表现明显优于CNN-B,因此对于低分辨率图像,采用不同结构的分类网络进行预训练是很有诱惑力的,并将它们用于低分辨率目标的目标检测。 -
微调高分辨率分类器:
CNN-B-FT在高分辨率图片上进行预训练,然后使用上采样的低分辨率图片进行微调,结果要优于CNN-S,在高分辨率图片上学习的卷积核对于检测低分辨率图片也有效。
同样地,在大尺寸实例上学习的卷积核对于小尺寸目标也有效。
总结:
- 使用上采样。
- 在高分辨率图片上预训练的分类网络。
Deformable-RFCN
Deformable-RFCN:
- 在conv5层添加了变形卷积,来改变神经网络的感受野,从而生成不同尺寸对象的尺寸不变性表示。
- 另一个改变是position sensitive RoI pooling,神经网络对于每一个位置敏感的卷积核都预测偏移。
本文使用Deformable-RFCN检测器提取单一分辨率的候选。 Deformable-RFCN的主干网络选用ResNet-101,训练分辨率为800x1200。在RPN中选用5个锚尺寸。分类时,选用没有Deformable Position Sensitive RoIPooling的主干网路为ResNet-50的Deformable-RFCN。使用带有双线性插值的Position Sensitive RoIPooling, 因为它将最后一层中的卷积核数量减少了3倍。NMS的阈值为0.3,不是端到端的训练。使用ResNet-50以及消除deformable PSRoI filters可以减少3倍的时间并且节省GPU内存。
实例尺寸与数据对检测器的影响实验
训练与测试分辨率的不同会导致性能下降。但是GPU内存限制会导致分辨率不同。训练的分辨率会比测试的分辨率更低。
通过实验评估两方面的影响:
- 实例的尺寸
- 数据
在1400x2000的图片上进行评估检测小尺寸目标(小于32x32)。

-
使用不同的分辨率进行训练:
在800x1400 与1400x2000像素的图片上进行训练,为实验800all 与 1400all。训练的图片分辨率为1400x2000时,效果更好,即1400all。因为此时训练与测试是在相同的分辨率上。
但是提升是微乎其微的,因为在高分辨率上检测中大型目标,对象太大了以至于无法正确分类,因此在高分辨率上训练,提升了小尺寸目标的检测,却降低了中大目标的检测。 -
使用特定尺寸目标进行训练:
只使用小于80像素的目标进行训练,消除极大尺寸目标的影响,实验1400<80px,但是丢失了外表与姿态信息,从而导致检测性能下降。 -
多尺寸训练:
评价了在训练过程中使用多分辨率随机采样图像获取尺度不变检测器的常见做法。实验为MST。它确保训练实例在许多不同的分辨率下被观察到,但性能也因为非常小和大尺寸的对象的影响而降低。
使用拥有合适尺寸实例训练的检测器,从而获取物体尽量多的变量。
SNIP算法细节
结合多种算法的优势,在限制尺寸的基础上,使用外形变化大的目标进行训练。
SNIP是优化MST后的版本,其中只有接近预训练数据集的分辨率的对象实例,224x224像素。在MST中,每幅图像以不同的分辨率被观察到。因此,在高分辨率时,大物体很难分类,在低分辨率时,小物体很难分类。
由于每个对象实例只出现在几个不同的尺度上,其中一些外形在所需的尺度范围内。因此,本文只对属于所需规模范围的对象执行训练,其余的则在反向传播过程中被忽略。
SNIP训练所有的实例,获取所有的外形变量,减小了预训练的尺寸空间中的域偏移。

池化后的RoI的分辨率与预训练神经网络的符合,因此微调会变得更简单。类似于R-FCN算法,将RoIs分割成部分,并且使用position sensitive filters,使用相同的分辨率就会变得非常重要。否则特征与卷积核之间的位置关系将会丢失。
由于内存限制,会将图片进行裁剪,裁剪的目标是生成大小为1000x1000的子图片的数量最少,并且覆盖了图片中所有的小目标。对于每幅图像,生成大小为1000x1000的50个随机定位子图片。选择覆盖最大对象数量的子图片,并将其添加到我们的训练图像集中。直到所有对象都被覆盖。
为了加速采样进程,将子图片压缩到图片边界,平均需要1.7个子图片。
当图片大小为800x1200 或 480x640 或图片中不包含小尺寸对象时,不需要进行采样步骤。
随机裁剪并不是准确率提升的原因。
实验
本算法是在COCO数据集上面评估的,小尺寸对象的尺寸是小于 32x32,大尺寸对象的尺寸是大于96x96。
使用3个分辨率训练Deformable-RFCN,(480, 800), (800, 1200) 与 (1400,2000),
分别训练RPN与RCN,分类器训练7个epoch,RPN训练6个epoch。
SNIP:在训练1个epoch的RPN后使用SNIP,在训练3个epoch的RCN后使用SNIP。
学习率lr:0.0005训练1000次,然后增加到0.005。 或者是在RPN训练4.33个epoch后改变。
截止:训练7个epoch之后,表现最佳。
有效范围:
- RCN:
高分辨率:(1400,2000) -------> 有效区域:[0, 80]
中分辨率:(800,1200) -------> 有效区域:[40, 160]
低分辨率:(480,800) -------> 有效区域:[120, ∞]
在连接部分,有40像素的重叠。有效范围是在训练阶段确定的。 - RPN:
(800,1200) -------> 有效区域: [0,160]
RPN的有效范围是通过 minival set获取的。
正样本的选择:
在conv4上使用 15个anchors(5 scales - 32,64, 128, 256, 512, stride = 16, 3 aspect ratios),但是符合标准的候选框太少了。
正样本:overlap > 0.7,只有30%的真实框有符合要求的提案。
正样本:overlap > 0.5,只有58%的真实框有符合要求的提案。
因此当阈值为0.5时,仍有超过40%的真实框拥有的提案的overlap小于0.5。
本文对图像进行多分辨率采样,并在相关分辨率上反向传播梯度。
进行了多个对比实验,性能得到了很大提升。
- 多尺寸的输入对比实验:
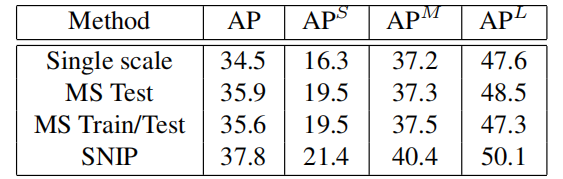
- 优化RPN后的对比实验:
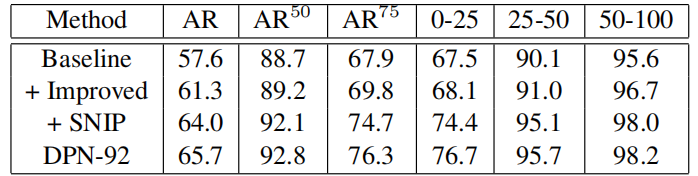
- 与其他算法的对比实验:

结论
在数据集上的实验结果证明了尺度和图像金字塔在目标检测中的重要性.因为我们不需要在高分辨率图像中对大型的对象进行反向传播,可以减少在图像中很大一部分的计算。