11年的花开物语的音乐资源真难找,绝大部分bt资源都死掉了,我还是悲剧的内网用户,BT下载真悲剧。基本只能靠长效种子的服务器来下载,那些活着的服务器经常都不给我一点资源,就算是1kb也行啊。
下载多个剧场版种子,已经接近一个星期0速度了,观察到不同bt任务情况

比较两个文件大小,两个文件大小完全一致,这两个很大概率是同一个文件。
用HxD打开,观察,坑爹。。。那个下载到95.6%的tak文件居然没有文件头,用播放器打开,提示不识别文件,超悲剧。而那个只下载了43.5%的tak文件,有文件头,用播放器打开也听得到音乐。


拖到文件尾,发现两个文件的尾部都下载好了,而且两个文件尾一模一样,没错了,这两个是同一个文件。


确认这两个是相同文件之后,修复的办法就是用那个只下载43.5%的文件来给那个95.6%的文件来补缺。bitcomet对文件未完成部分看起来只是单纯填充0。tak是无损压缩格式,既然是压缩文件,那正常文件内容不会有一大片0的区域,那存在一大片0的区域就一定是没下载的地方。
熟悉python,写个python脚本 来帮我找哪里有一大堆0,把那个下载到95.6%的tak文件复制出来然后重命名为1.tak,而下载到43.6%的文件复制后重命名为2.tak,以便于区分。一定要复制一份新的来操作,避免损坏原文件。
然后写了个python脚本 来查找这两个文件中哪里里连续存在大于等于16个0字节的区域
import os
f1 = open(r"C:\Downloads\bing\1.tak", 'rb')
f2 = open(r"C:\Downloads\bing\2.tak", 'rb')
log1 = open('1.log', 'w')
log2 = open('2.log', 'w')
def print_empty_seg(f, logf, block_size=16):
empty_has_start = False
empty_start = 0
empty_end = 0
while True:
data = f.read(block_size)
data = list(data)
r = sum(data)
if r == 0 and not empty_has_start:
empty_has_start = True
empty_start = f.tell() - len(data)
s = str(empty_start) + ' '
logf.write(s)
print(s, end='')
elif r > 0 and empty_has_start:
empty_has_start = False
empty_end = f.tell() - len(data)
s = str(empty_end) + '\n'
logf.write(s)
print(s, end='')
if len(data) < block_size:
break
if empty_has_start:
s = str(f.tell()) + '\n'
logf.write(s)
print(s, end='')
logf.flush()
print_empty_seg(f1, log1)
print_empty_seg(f2, log2)
f1.close()
f2.close()
log1.close()
log2.close()
运行后输出两个log文件
log文件中,每行第一个数字是未下载区段的开始偏移,第二个数字是结束偏移。
1.log 文件内容
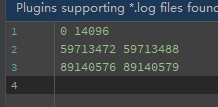
2.log 输出内容
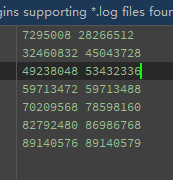
观察到。。。这两个文件都同时缺了 59713472-59713488 和 89140576-89140579 两端,心里一凉。。。用HxD打开看看
用HxD打开这个下载了95.6%的文件,跳转到59713472


发现这一行全为0,但是上面和下面都有数据,又打开那个下载到43.5%的文件,也跳转到59713472这里观察。

发现这个下载到43.5%的文件,跟之前的95.6%的文件数据一样,猜测,这里应该就是16个0字节,原本就有着16个0字节。
接着看89140576偏移处。


观察到也是一样的,也猜测原来文件也是这样的。。。
这样的话, 59713472-59713488 和 89140576-89140579 就应该不是未下载段了。不过就算是,也完全没办法。。。
--------分界点1
这样的话,那个下载95.6%的文件只有 0-14096 区段是未下载区段了,刚好,那个下载了43.5%的文件正好有对应的数据。
正好,再写个python脚本把 2.tak 的 0-14096 的数据写到 1.tak 中
f1 = open(r"C:\Downloads\bing\1.tak", 'rb+')
f2 = open(r"C:\Downloads\bing\2.tak", 'rb')
d = f2.read(14096)
f1.write(d)
f1.close()
f2.close()
执行后,1.tak处理完了
用播放器打开,听了一遍,没啥问题。然后搜索一下tak文件的特性,看到

每一音频帧都可以校验,突然想起以前好像用过tak的相关工具将tak转换为wav格式,好像还附带查错功能。
去到tak的官网 http://thbeck.de/Tak/Tak.html
找到了一个工具

下载后解压后打开,找到这 Tak.exe

打开后使用这功能
添加刚刚修复好的文件 1.tak

然后点击 Test

呃。。。仍然是损坏文件了。。。
目录下多了个文件,打开

发现这里坏了。。。
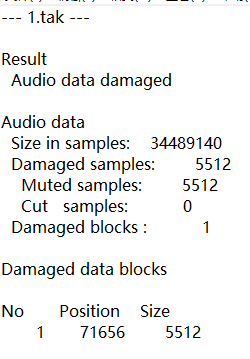
试试把 2.tak 也检查一下看看
不出所料也是坏的

但是看看日志

虽然坏了很多地方,但是,可以发现,跟1.tak坏的地方并不一样,错开了。说明还可以继续修复。
那些数字是说第几个帧开始,连续损坏多少个帧,Tak不开源,不知道确切的文件偏移地址。
就用土方法,这1.tak文件大小是85.0M
用百分比公式来大概猜测文件偏移。并且观察到,1.tak和2.tak的损坏区间之间隔着很大的距离,所以下面的偏移不精确也没关系
结束偏移= (71656+5512)/34489140 * (8510241024)=199422.298882489
随便取个整,200000
修改一下脚本再执行
f1 = open(r"C:\Downloads\bing\1.tak", 'rb+')
f2 = open(r"C:\Downloads\bing\2.tak", 'rb')
d = f2.read(200000)
f1.write(d)
f1.close()
f2.close()
再用Test执行一次看看

文件修好了!!!
分界线2
上面操作犯了个愚蠢的错误,本来可以更快处理好的
就是没有 去 1.tak 和 2.tak 的 14096 偏移观察一下
1.tak 的 14096 偏移处

2.tak 的 14096 偏移

观察之后可以发现,准确点应该是 2.tak 的 0-14096+4 区段的内容到 1.tak
之前过于高兴忘记了观察。加上 偏移 4 之后,再使用 tak.exe 进行检查,校验通过了
f1 = open(r"C:\Downloads\bing\1.tak", 'rb+')
f2 = open(r"C:\Downloads\bing\2.tak", 'rb')
d = f2.read(14096+4)
f1.write(d)
f1.close()
f2.close()
bk 来自搜索到的320Kbps版本cd
tak log cue 来自以下两个磁力
magnet:?xt=urn:btih:FLIOE5OOJPBTUPRHXOTAEXMHCMEKXE6C
magnet:?xt=urn:btih:RKKPXG3UZ5RFOLIEKMTDKIQZJ6HOQ4KC
顺便加上修好的文件的链接。。。这张cd很难找了。。。
顺便打了一个包。
「花咲くいろは HOME SWEET HOME」主題歌「影踏み」/nano.RIPE(tak+cue+jpg+log)