一、使用MapReduce的方式进行词频统计
(1)在HDFS用户目录下创建input文件夹
hdfs dfs -mkdir input
注意:林子雨老师的博客(http://dblab.xmu.edu.cn/blog/1080-2/)中是在hadoop目录下创建input文件,而MapReduce读取的是HDFS目录中的文件,因此笔者认为该博客存在错误。
(2)在hadopp根目录中创建两个测试文件file1.txt和file2.txt,并将他们拷贝到HDFS中的input目录下
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt
hdfs dfs -put file1.txt file2.txt input/
知识点延伸:
echo " hello world" > file1.txt # 表示创建file1.txt
echo "nihao" >> file1.txt # 表示往file1.txt里追加内容
echo "" > file1.txt # 表示清空file1.txt里的内容,但是文件中还存在空字符串
echo -n > file1.txt # 清除文件的所有内容,包括空字符串
参考:https://linux.cn/article-8024-1.html
(3)调用MapReduce程序对input文件夹中的文件进行词频统计
cd /usr/local/hadoop #切换到hadoop目录下
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount input output
注意:虽然输入目录是在hadoop目录下,但是自动生成的输出目录是在HDFS目录下的,如果HDFS目录下已存在output文件夹,就需要先删除,否则会出现下图所示的错误:

(4)执行结果

二、使用Hive完成词频统计(7行代码搞定)
1.编写Hql代码
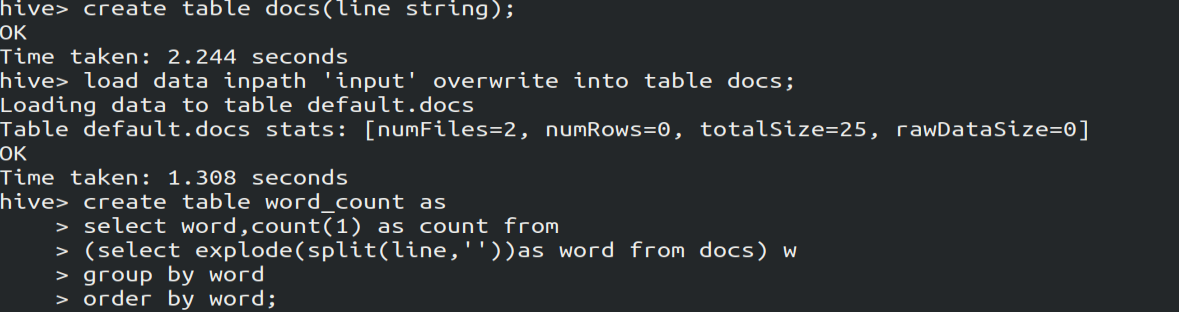
create table docs(line string); # 创建docs表并注明表里的数据类型是String
load data inpath 'input' overwrite into table docs; # 向表中装载数据
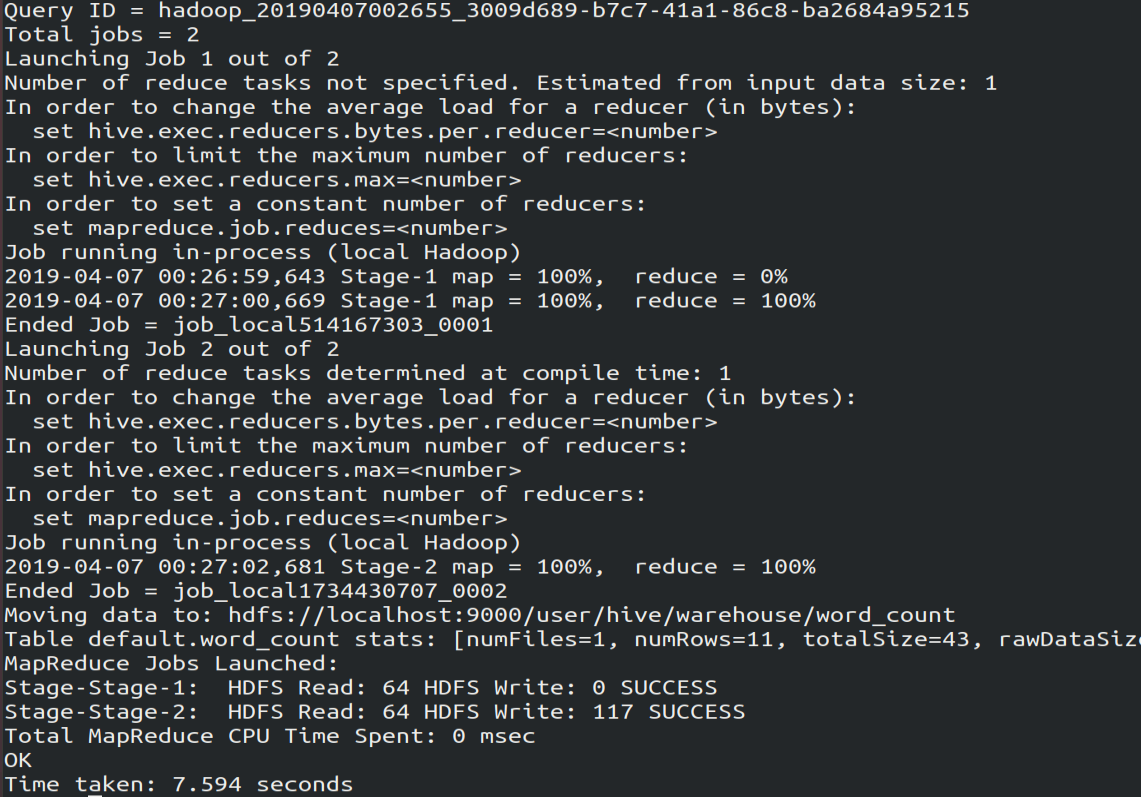
create table word_count as # 创建word_count表,将数据保存到该表
select word, count(1) as count from
(select explode(split(line,' '))as word from docs) w
group by word
order by word;
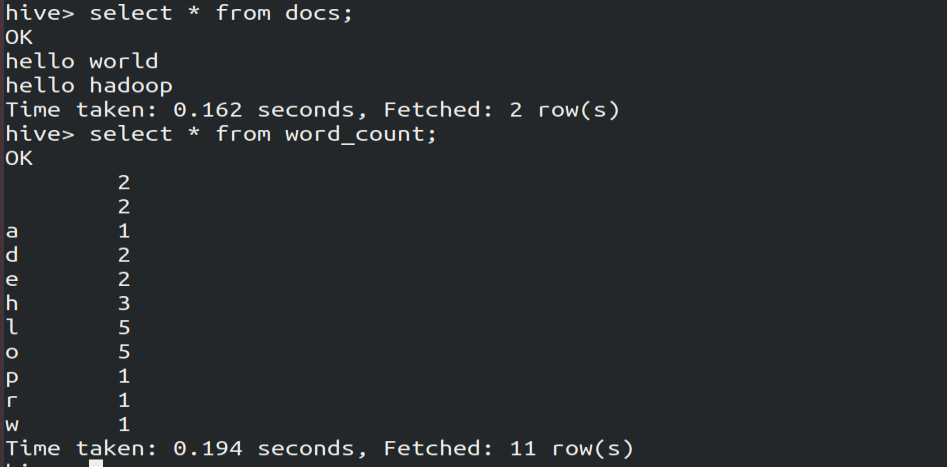
2.查询执行结果
select * from word_count