pymongo的基本使用
pymongo库的调用
import pymongo
创建连接(因为用的本机的mongodb数据库,所以直接写localhost即可,也可以写成127.0.0.1,27017为端口)
client = pymongo.MongoClient(‘localhost’, 27017)
连接数据库(如不存在会自动创建)
db = client[‘mydb’]
连接表(如不存在会自动创建)
collection = db[‘my_collection’]
插入记录
collection.insert_one({“key1”:“value1”,“key2”,“value2”})
删除记录
collection.remove()
按条件删除
collection.remove({“key1”:“value1”})
更新记录
collection.update({“key1”: “value1”}, {"$set": {“key2”: “value2”, “key3”: “value3”}})
查询一条记录
find_one()
不带任何参数返回第一条记录.带参数则按条件查找返回
collection.find_one()
collection.find_one({“key1”:“value1”})
查询结果排序单列排序
collection.find().sort(“key1”) # 默认为升序
collection.find().sort(“key1”, pymongo.ASCENDING) # 升序
collection.find().sort(“key1”, pymongo.DESCENDING) # 降序
多列排序
collection.find().sort([(“key1”, pymongo.ASCENDING), (“key2”, pymongo.DESCENDING)])
下面写一个中国大学爬虫定向爬虫实例加以简单运用:
import pymongo
import requests
from bs4 import BeautifulSoup
import bs4
#通过url获取页面信息
def getHTMLText():
try:
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print('网络连接失败')
return ""
#提取所需要的大学排名信息
def fillList(demo):
soup = BeautifulSoup(demo,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
fllist.append([tds[0].string,tds[1].string,tds[3].string])
#对大学排名进行显示输出
def PrintFllist(fllist,num):
# 建立连接
client = pymongo.MongoClient('localhost', 27017)
# 连接数据库
db = client['mydb']
# 连接表
collection = db['rank']
for i in range(num):
u = fllist[i]
# 插入数据
collection.insert_one({'排名': u[0], '学校名称': u[1],'总分':u[2]})
if __name__=='__main__':
fllist= []
demo=getHTMLText()
fillList(demo)
PrintFllist(fllist,20) #20 所
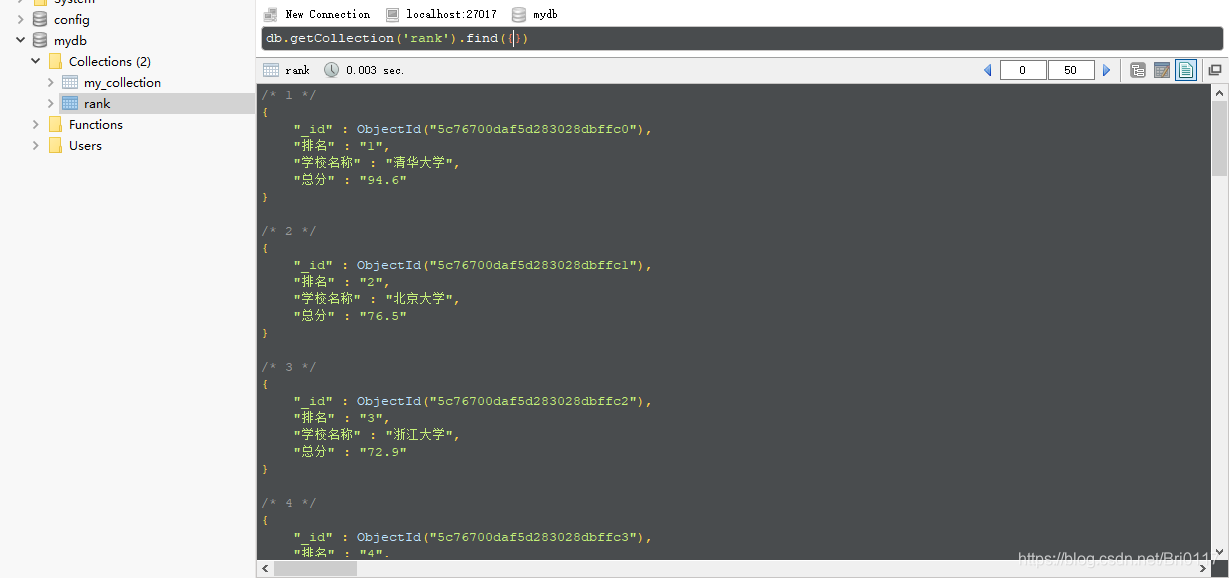
结果图: