一、hashmap的源码问题,hashmap的底层结构?put操作?
1.底层结构(基于Java8)
性能:O(1)、O(n)、O(logn)
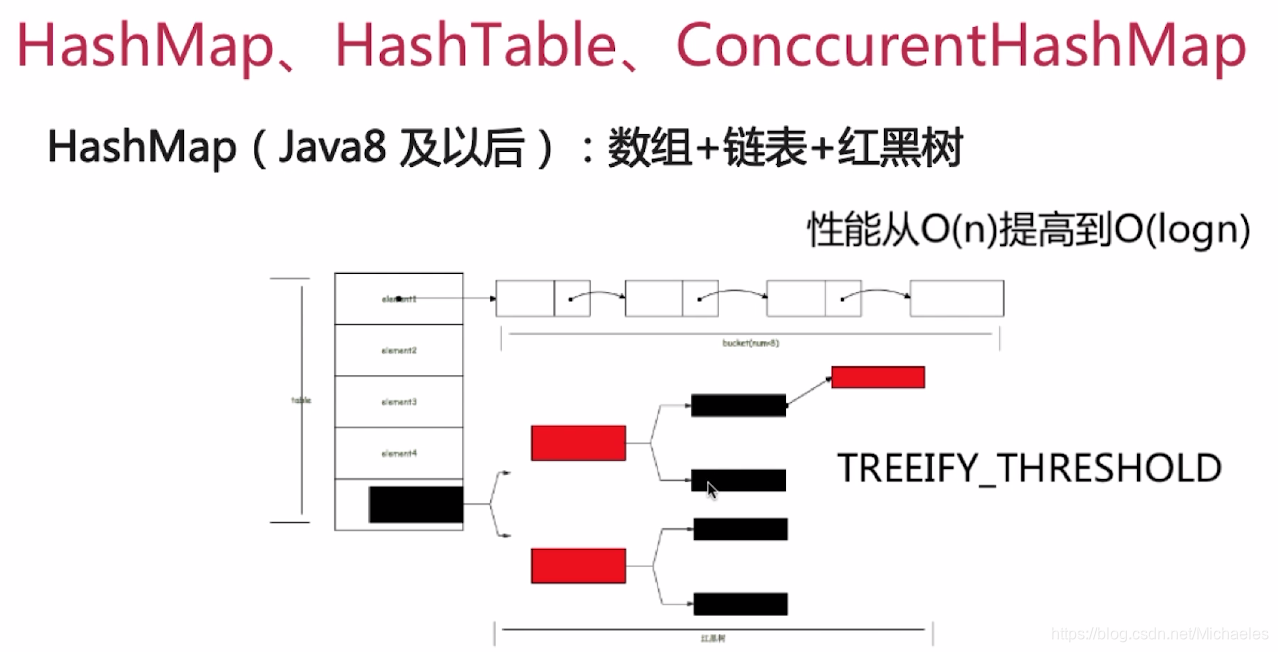
注:当链表大小超过8,会被改成红黑树;当低于6时,又会被改为链表;
2.put操作

流程:
(1)先调用putVal()方法,当table数组为空时调用resize()方法,进行初始化;
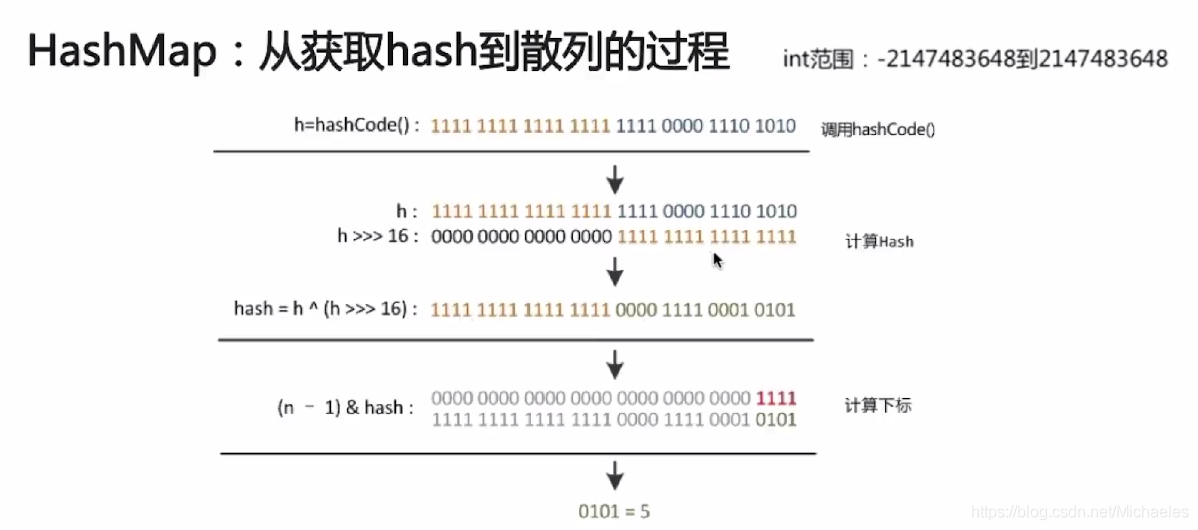
(2)对key进行求hash值(是hash方法的与或产生的结果),计算table的存储下标;
(3)通过hash计算得到table中对应的位置还没有键值对,就生成一个newnode放到该数组中;
(4)如果,数组的同一位置存在键值对,就以链表的方式放到后面;
(5)接下来判断是否是树化了的节点,如果是就按照树的方式存储键值对;
(6)如果不是就按照链表的插入方式向链表后面添加元素,同时判断是否超过8,超过就要进行树化(treeifbin);
(7)插入的节点已经存在就替换旧的值;
(8)如果桶满了,进行扩容;
关键代码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}3.链表进行树化的必要条件?
(1)链表中的元素个数要大于TREEIFY_THRESHOLD;
(2)整个哈希表的元素个数也要大于MIN_TREEIFY_CAPACITY;
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);3.get操作
(1)调用键值的hashcode()方法,找到bucket的位置;
(2)调用key.equals()方法找到链表中的节点,并返回。
4.为什么使用string作为键?
(1)是final对象、并且重写了equals()hashcode()方法
5.hashmap中的hashcode是怎么实现的?
(1)按位与运算符(&)、按位或运算符(|)、异或运算符(^);
(2)table数组的容量为什被调整为2^n?(目的就是减少hash碰撞)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
6.hashmap的扩容问题?
(1)默认负载因子为0.75;
(2)需要rehashing;
二、hashmap如何保证线程安全?ConcurrentHashmap原理?
1.hashtable?
原理就是将涉及到修改hashtable的方法,使用synchronized修饰。因为是串型化方式运行,性能较差。
2.synchronizedmap
定义一个Object 类型的 mutex互斥对象成员,对public方法使用synchronized锁住整个对象,
3.concureenthashmap原理?
(1)concurrenthashmap使用CAS插入头节点,失败则循环重试;若头节点已经存在,尝试获取头节点的synchronize同步锁,再进行操作。

(2)put方法逻辑

4.3者之间的区别?
