版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/github_36923418/article/details/89116606
一、原理:
朴素贝叶斯必须要有的先决假设:特征条件独立,意思就是 X这个特征向量中的x1,x2,x3.。。。等,相互之间都是条件独立的。
先验概率:
![]()
条件概率:
![]()
根据条件独立这个假设,可以得到如下条件概率的计算方式:

那么在利用 朴素贝叶斯 进行分类时,计算后验概率的方式如下:
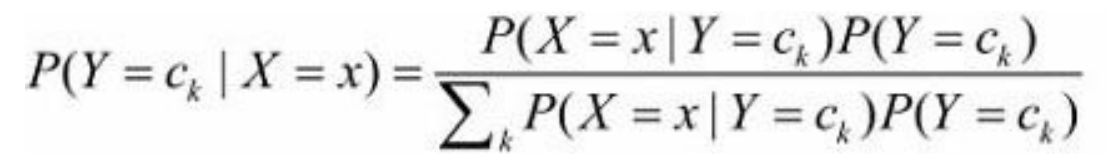

扫描二维码关注公众号,回复:
5823909 查看本文章

那么“朴素贝叶斯”模型可以表示为:
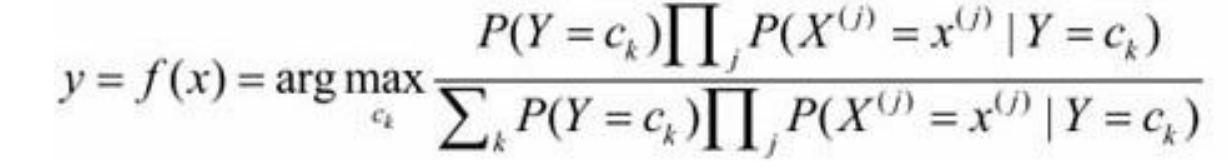
因为,对于任何分子,他们的分母都是相同的,所以又可以简化为如下内容:
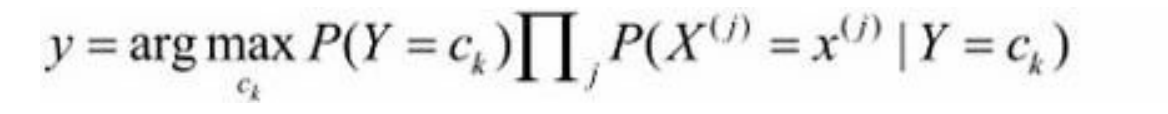
二、代码:
依然会利用第三章中用到的“鸢尾属植物 iris数据集”,对于这个数据集假设服从的是“高斯分布”。那么我们可以得到如下的概率密度函数:

概率密度函数 对应于 上面的 “条件概率” 这个概念。
#倒入全部用得到,用不到的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math#创建数据
# data
#这里代码来自于某个开源放出来的“机器学习初学者”这个公众号那边放出来的代码
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, :])
# print(data)
return data[:,:-1], data[:,-1]
#建立模型
class NaiveBayes:
def __init__(self,):
self.model=None
#数学期望 ,用来求出训练集不同特征的的均值
def mean(self,X):
return sum(X)/float(len(X))
#标准差/方差 ,求出训练集,不同特征的std
def stdev(self,X):
average = self.mean(X)
std=sum([math.pow(x-average,2) for x in X]) / float(len(X))
std = math.sqrt(std)
return std
#条件概率
def gaussian_probability(self,x,mean,stdev):
exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2))))
return (1./math.sqrt(2*math.pi*math.pow(stdev,2)))*exponent
def get_mean_std(self,x_feature):
mean_std=[(self.mean(i), self.stdev(i)) for i in zip(*x_feature)]
return mean_std
def train_model(self,X,y):
labels=list(set(y)) #利用set可以获取 y的所有不同取值
data = {label:[] for label in labels} # 给每一个类别建立 list
for feature, label in zip(X,y):
data[label].append(feature) #把每个类别的特征进行搜集
#计算出,在某个类别下,某个特征的概率 =》条件概率 =》概率密度 ,因此要现求出某个类别下,某个特征的mean和std
self.model = {label: self.get_mean_std(x_i_list_value) for label,x_i_list_value in data.items()}
print("model ready!")
def calculate_probabilities(self,input_data):
# 需要计算,所有类别的可能概率,最后选择概率最大的类别
probabilities={}
for label, value in self.model.items():
probabilities[label]=1 #先验概率直接假设为1
assert len(value)==4
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(input_data[i], mean, stdev)
return probabilities
def predict(self,X_test):
#print(sorted(self.calculate_probabilities(X_test).items(), key=lambda x: x[-1])[-1][0])
#利用 【(lable, probability),(lable, probability)】中的倒数第一个内容进行排序
label = sorted(self.calculate_probabilities(X_test).items(), key=lambda x: x[-1])[-1][0]
return label
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)model = NaiveBayes()
model.train_model(X_train, y_train)
model.predict([4.4, 3.2, 1.3, 0.2])
#0.0