1 )损失函数 推导
encoder 是要拟合一个p(z)
由 p(x,z)=p(z|x)*p(x) 得到p(x)=p(x,z)/p(z|x),上下同时除以一个q(z) 得到
p(x) =(p(x,z)/q(z))/(p(z|x)/q(z)) 求极大似然是要对两边取log 得到:
lnp(x)= ln(p(x,z)/q(z))-ln(p(z,x)/q(z)) .
用q(z) 积分得到:![]()
因为p(x) 与z无关,所以左边的式子可以提出来得到
![]()
因![]() 等于1 ,
等于1 ,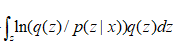 为KL(q(z)||p(z|x) ),
为KL(q(z)||p(z|x) ),![]()
第一项减去第二项为ELBO,KL >=0
优化是 KL 尽可能小,ELBO 尽可能大。
扫描二维码关注公众号,回复:
5835295 查看本文章

接下来是最大化ELBO: ELBO=ln(px)-KL(q(z)||p(z|x))
又因为p(x,z)=p(x|z)p(z),
其中  对q(z) 的积分就是q(z) 的期望。
对q(z) 的积分就是q(z) 的期望。
ELBO=![]()
=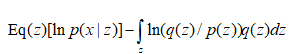 第二项为KL(q(z)|p(z))
第二项为KL(q(z)|p(z))
= 第一项为reconstruction loss 对于分类问题是交叉熵函数,假设q的分布为多元高斯分布,要让q 无限逼近于p,p(z) 为真实的z的分布。多元高斯分布可以通过复杂变化逼近任何一个其它的分布
第一项为reconstruction loss 对于分类问题是交叉熵函数,假设q的分布为多元高斯分布,要让q 无限逼近于p,p(z) 为真实的z的分布。多元高斯分布可以通过复杂变化逼近任何一个其它的分布
autoencoder :https://blog.csdn.net/changyuanchn/article/details/15681853