0 引言
学过了线性列表字符串str""、列表list[]、元组tuple(),今天我们来聊聊另外两个非常重要的数据类型: bytes、bytearray。

1.概念
bytes 与bytearray都是Python3才引入的两个类型。
bytes 表示字节序列,是一个不可变的数据类型。
bytearray 表示字节数组,是一个可变的数据类型。
定义这两种类型的数据,在内存中开辟的空间都得是连续的。
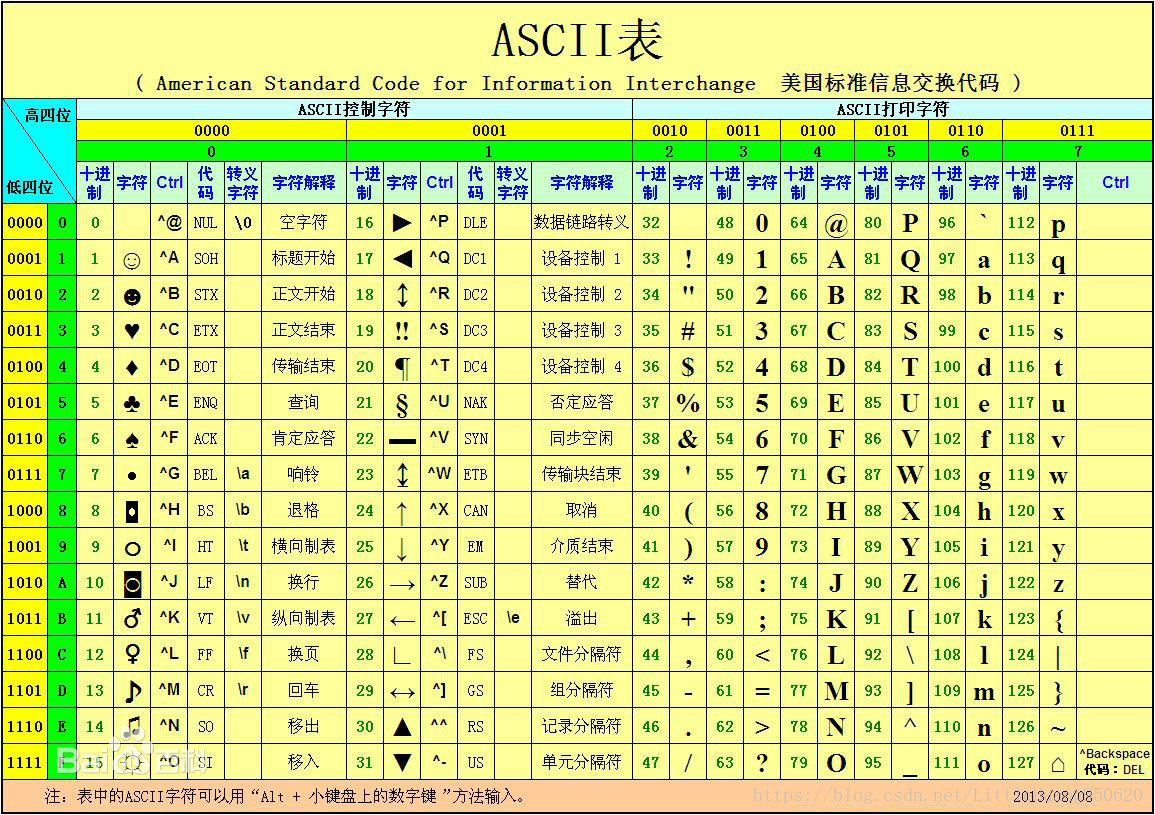
首先科普一下字母数字等字符在计算机不同编码中所占的字节数:
ASCII码:
一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。如一个ASCII码就是一个字节。 UTF-8编码:
一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
Unicode编码:
一个英文等于两个字节,一个中文(含繁体)等于两个字节。
符号:
英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
记住常用的几个ASCII 编码:(以16进制为例)
9: 代表制表符 13: 代表回车 10: 代表换行
31: 代表数字1 41: 代表大写字母A 61:代表小写字母a
2、bytes 类型
2、1 bytes 的定义
- bytes:
定义空字节,空字节前面有个 b 来区分。
bytes()
>>>b''
- bytes(int):
直接定义字节的个数,就是创造了几个空字节,但是每个字节里面是空的。
bytes(3)
>>>b'\x00\x00\x00' ## 这是ASCII 0 ,不是阿拉伯数字0,阿拉伯数字0是十进制48,十六进制30.
- bytes(iteratable):
创造可迭代对象的元素个数相等的字节,然后把每个元素填充进去。
注意,必须是整型int 的可迭代对象。
bytes(range(5))
>>>b'\x00\x01\x02\x03\x04'
bytes([1,2,3])
>>>b'\x01\x02\x03'
bytes[0x61,0x62] #按16进制的ACCII码
>>>b'ab'
- bytes(byte) or bytes(‘string’,encode) :
等价于string.encode()
s1='a'
s1.encode()
>>>b'a'
s1='中'
s1.encode(encoding='utf8')
>>>b'\xe4\xb8\xad'
s1='中'
s1.encode(encoding='gbk')
>>>b'\xd6\xd0'
b2=bytes('abc','utf-8')
>>>b'abc'
等价于'abc'.encoding()
b3=bytes(b2)
>>>b'ab'#带入之前bytes对象输出新的,输出是同一个对象,python对某些常量进行了优化,bytes和str 一样属于字面常量
b4=b'abc'
b5=b'\x61\x62\x63'
b4,b5
>>>b'abc' b'abc'
#不同的编码输出不同的结果,默认为utf-8编码
#从上可得,在定义bytes时,可以采用字符串直接定义,并不需要知道定义对象的ASCII码,直接采用字符串定义即可,简单快捷。
2.2 bytes 的修改
bytes 和 str 一样,都是不可修改的类型,所以,所谓的修改,都是创造一个新的bytes 和str。
二者的用法也类似。只不过bytes的方法,输入是bytes,输出的也是bytes。
- bytes.fromhex
bytes.fromhex(string)
b1=bytes.fromhex('6162 09 6a 6b00')
>>b'ab\tjk\x00'#string必须是2个字符的16进制的形式,'6162 6a 6b',空格将被忽略
b1.hex()#返回bytes对象的十六进制数
- bytes.replace
b'abcdef'.replace(b'f',b'k')
>>>b'abcdk'
- find
b'abc'.find(b'b')
>>>1 #存在则返回1,不存在则返回-1
- 索引
b'abc'[2]
>>>99#返回该字节对应的数,int类型 字符串索引返回的还是字符串
3、bytearray 类型
3、1 bytearray的定义
bytearray() #空bytearray
bytearray(int) #指定字节的bytearray,被0填充
bytearray(iterable_of_ints) #--> bytearray [0,255]的int组成的可迭代对象
bytearray(string, encoding[, errors]) #-> bytearray #近似string.encode(),不过返回可变对象
bytearray(bytes_or_buffer) #从一个字节序列或者buffer复制出一个新的可变的bytearray对象
注意,b前缀定义的类型是bytes类型 前缀是bytearray
3.2、sbytearray操作
和bytes类型的方法相同
bytearray(b'abcdef').replace(b'f',b'k')
bytearray(b'abc').find(b'b')
bytearray.fromhex(string)
string#必须是2个字符的16进制的形式,'6162 6a 6b',空格将被忽略
bytearray.fromhex('6162 09 6a 6b00')
hex()
返回16进制表示的字符串
bytearray('abc'.encode()).hex()
索引
bytearray(b'abcdef')[2] #返回该字节对应的数,int类型
4、字节序
大端模式,big-endian;小端模式,little-endian
Itel X86 CPU使用小端模式
网络传输更多使用大端模式
Windows、Linux使用小端模式
Mac OS使用大端模式
Java虚拟机是大端模式
.png?raw=true)
字节与byets之间的相互转换
int.from_bytes(b'abcd','big') #大端输出
>>>1633837924#十进制表示法
hex(1633837924)#十六进制表示法
>>>'0x61626364'
int.from_bytes(b'abcd','little') #小端输出
>>>1684234849
hex('1684234849 ')
>>>'0x64636261'
st=int.from_bytes(b'abcd','big')
st.to_bytes(4,'big') #给出的字节长度只能大于等于原字节长度,多于的会被补零,少的则报错.
st.to_bytes(5,'big')
>>>b'\x00abcd'
st.to_bytes(4,'little')
>>>b'dcba'#原先为大端输出,这里用小端进行解码,得到的数据则会不一样,故在使用时大端与小端要一一对应.