当我们假设各个类别间相互独立且每个数据都同样重要,我们就可以利用条件概率公式:
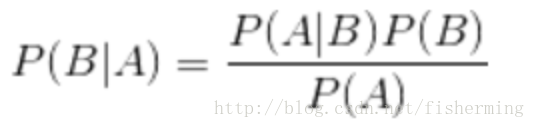
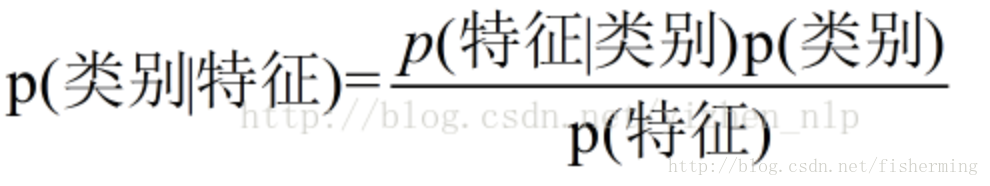
来计算各个数据属于每个类别的概率,最后概率最大的那个类别即该数据所属类别。
这样的方法称之为朴素贝叶斯分类器。
这两个假设当然是过于理想化了,但在实际应用中,这一分类器的实际效果却很好。
当进行文本分类时,对同一特征而言,p(特征)相等,因此不用计算,而p(类别)可以简单地通过该类别数据数处以总数据数来求得。而求p(特征|类别)时,就要使用到贝叶斯假设,我们将某一特征化为一个个地独立特征,计算每个特征的条件概率,再将其相乘,即得到总的条件概率。
我们在使用分类算法对数据进行分类后,往往需要对其进行评价,留存交叉验证即是一个验证算法。
留存交叉验证:随机选择数据的一部分作为训练集,剩余部分作为测试集的过程。
我们使用训练集作为输入数据,来构建贝叶斯分类器,并输入测试集计算其分类结果,将其与实际结果作比较,错误数除以测试集数据总数即为错误率。为了更精确地估计分类器的错误率,我们往往需要进行多次迭代,求其平均错误率。
|:求两个集合的并集
相应的:
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
compile():将字符串转为python的可执行代码
min():参数可为多个,给出最小值。相应的,还有max()。