聚合函数:
1.count() 计数,统计所有记录
语法和练习:
练习用表:score
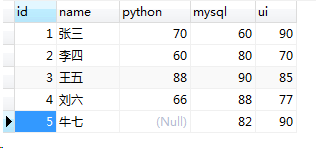
(1)统计班里有多少学生:
select count(id) from student;
(2)ui成绩大于70的学生个数:
select count(*) from score where ui>70;

(3)总分大于220的人数
select count(*) from score where (python+mysql+ui)>220;

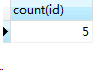
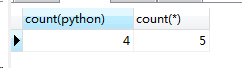
(4)count(*)不会忽略掉null
select count(python),count(*) from score;
2.sum() 求和函数
语法和练习:
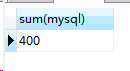
(1)统计一个班的mysql总成绩:
select sum(mysql) from score;
(2)统计一个班的各科的总成绩
select sum(python),sum(mysql),sum(ui) from score
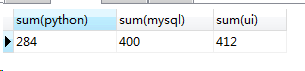
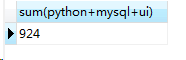
(3)统计一个班三科总成绩
select sum(python+mysql+ui) from score;
(4)统计每个人三科的总成绩
select name,python+mysql+ui from score;
或:select s1.name,s1.python+s1.mysql+s1.ui from score as s1,score as s2 where s1.id=s2.id;

3.avg() 求平均数
语法和练习:
(1)一个班python成绩的平均分:
select avg(python) from score;
或:select sum(python)/count(python) from score;

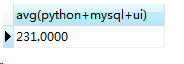
(2)一个班的总分平均分:
select avg(python+mysql+ui) from score;
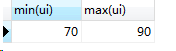
4.min() 求最小值
max() 求最大值
select min(ui),max(ui) from score;
5.group by 分组
GROUP BY子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。分组函数忽略空值。
create table t_order(
id int primary key,
product varchar(20),
price float(8,2)
);
insert into t_order values(1,'xiaomi', 1000);
insert into t_order values(2,'xiaomi',1100);
insert into t_order values(3,'huawei',2200);
insert into t_order values(4,'apple',8200);
select * from t_order;
-- 1.对订单表中商品归类后,显示每一类商品的总价
select product, SUM(price) from t_order GROUP BY product;
-- 2.对订单表中商品归类后,查询每一类商品总价格大于3000的商品
select product, SUM(price) as total from t_order GROUP BY product HAVING total>3000;
select product, SUM(price) from t_order GROUP BY product HAVING SUM(price)>3000;
注意:
(1)、分组函数的重要规则
如果使用了分组函数,或者使用GROUP BY 的查询:出现在SELECT列表 中的字段,要么出现在聚合函数里,要么出现在GROUP BY 子句中。
(上面的product出现在了group by中,price出现在了聚合函数中)
GROUP BY 子句的字段可以不出现在SELECT列表当中。
(2)、having where 的区别
①、where和having都是用来做条件限定的,
②、WHERE是在分组(group by)前进行条件过滤,
③、HAVING子句是在分组(group by)后进行条件过滤,
④、WHERE子句中不能使用聚合函数,HAVING子句可以使用聚合函数。
⑤、HAVING子句用来对分组后的结果再进行条件过滤
having sum(price)>2000 相当于 拿着 列名为sum(price)去查询。