三范式是关系型数据库设计的基本准则,一般没有特殊需求的增删改查业务,满足三范式没错的!
注: 本文不对三范式的概念进行介绍,只举例说明本人对三范式的理解!欢迎斧正!
第一范式:1NF
1、确保创建表时的每一列属性的原子性,即每一列属性都是不可再分的属性值。
(1)例如:

(1)解释:
user_address 属性不符合属性的原子性,该属性可以进一步进行拆分成,省、市、县、详细地址等信息!
(2)例如:

(2)解释:
将原user_address属性拆分成省份、地市信息(int类型数据字典值),根据具体需求可以将详细地址进一步进行拆分,定位到城区,县市,甚至是小区名称,建筑物名称等!
所以所谓属性的原子性也要结合具体需求实现相应粒度的原子性!例如:要对用户的省市信息进行分组表1显然不满足需求、要对区县信息进行分组表2仍不满足需求,应进一步将user_address进行原子性拆分。
2、同一个数据表中不得存在类型相似的属性
(1)例如:
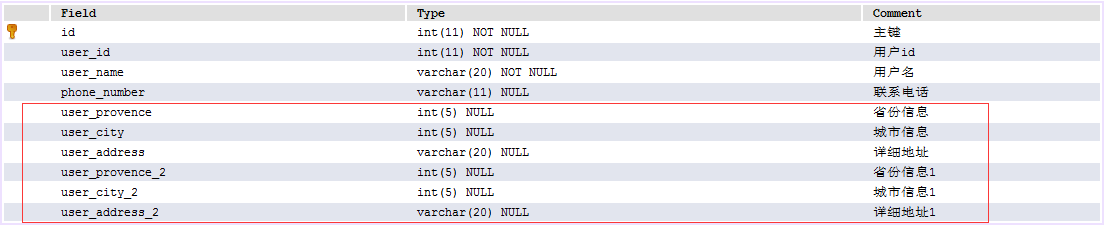
(1)解释:
user_provence_2 等属性与user_provence等属性重复,当前表既无法满足用户有多个收货地址的情况,当只存在一个收货地址的情况下,又会造成字段冗余!
创建收货地址表,解决属性相似问题,及多个收货地址的情况!

第二范式:2NF
1、一张表在满足1NF的前提下,表中其他非主属性又统一直接依赖表中唯一主属性(primary key),即不能出现两列主属性被其他非主属性分别依赖。则满足2NF!
(1)例如:

(1)解释:
在用户表中存在非主属性[order_info]不与该表主属性[user_id]直接关联(order_info与order_id直接关联),即当前表不满足2NF。
应将订单表与用户表分离,订单表通过关联用户表user_id实现 [用户—订单] 绑定。保证了一个表只保存一类业务实体。
第三范式:3NF
1、数据表中不存在属性的依赖传递
(1)示例:

(1)解释:乍一看,code能决定其他非主属性,符合2NF。但是在同系的学生中,系相关信息被保存n份。
(1)造成了数据冗余,同系学生的系相关信息相同。
(2)修改系相关信息,则需要修改所有学生的系信息。
解决办法:分表操作!
解决表中的依赖传递现象,code—>d_code ,d_code 能决定d_name/d_address ,则code影响d_name/d_address是通过code—>d_code 进行的依赖传递实现的。

