本次问答系统是复现实验,使用rdf作为知识存储的工具,原始的项目源码,原始参考:知乎专栏
作者源码是python2写的,我将其改写为python3,更改后项目源码链接,提取码:8fk4
在复现系统的过程中将自己遇到的一些问题记录下来,方便自己以后查阅以及让读者少走一些弯路
源码文件结构展示:
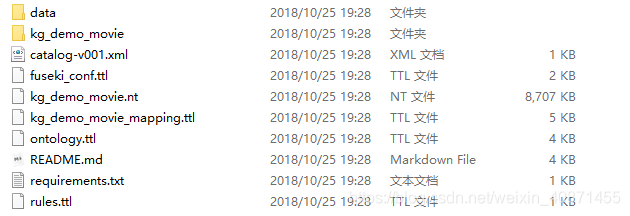
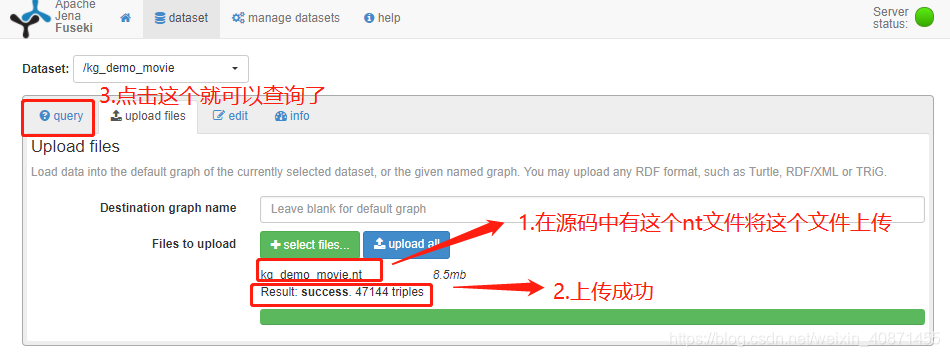
项目的主逻辑文件在 ./KG-demo-for-movie-master/kg_demo_movie下,其中crawler文件夹用于爬取数据,由于数据原作者已给出,所以这个文件夹不用,另一个文件夹KB_query,其子文件(如下图)为问答的逻辑文件
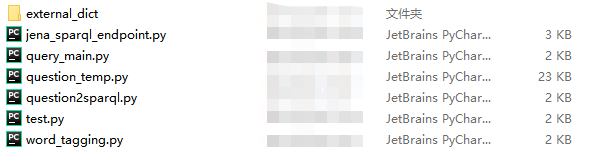
-
"external_dict"包含的是人名和电影名两个外部词典。csv文件是从mysql-workbench导出的,按照jieba外部词典的格式,我们将csv转为对应的txt。
-
"word_tagging",定义Word类的结构(即我们在REfO中使用的对象);定义"Tagger"类来初始化词典,并使用jieba对句子进行分词和词性标注,并实现自然语言到Word对象的方法,运行效果如下:

-
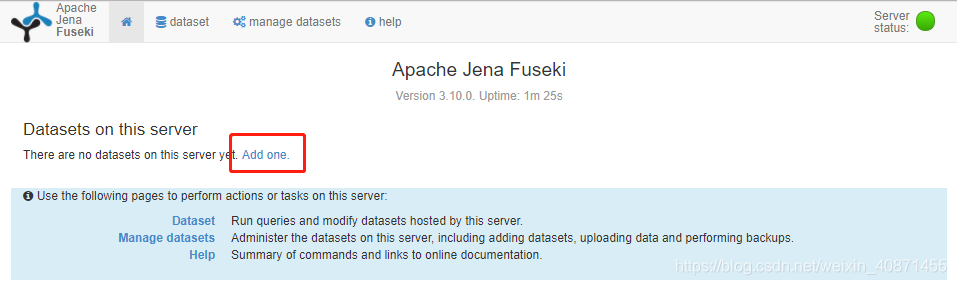
"jena_sparql_endpoint",用于完成与Fuseki的交互。首先我们需要启动fuseki服务,下载解压Apache-Jena和Apache-Jena-fuseki,下载地址:清华镜像站(fuseki使用方法请看我的另一篇博客),Jena我们后面用,先看Jena_fuseki
![]()
进入fuseki文件夹,双击fuseki-server.bat脚本文件,出现如图所示的界面

然后我们用浏览器访问:http://localhost:3030
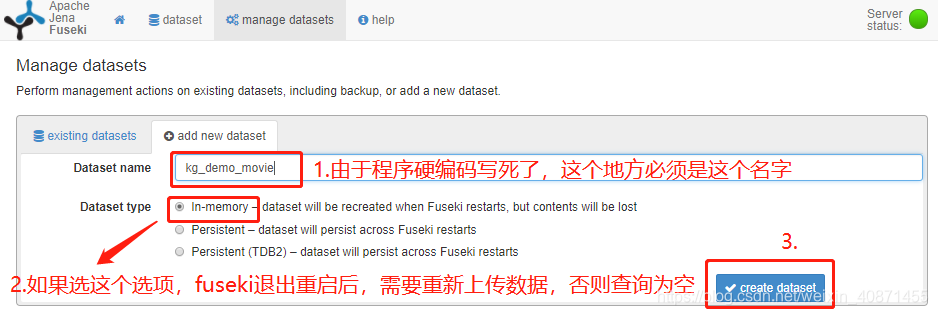

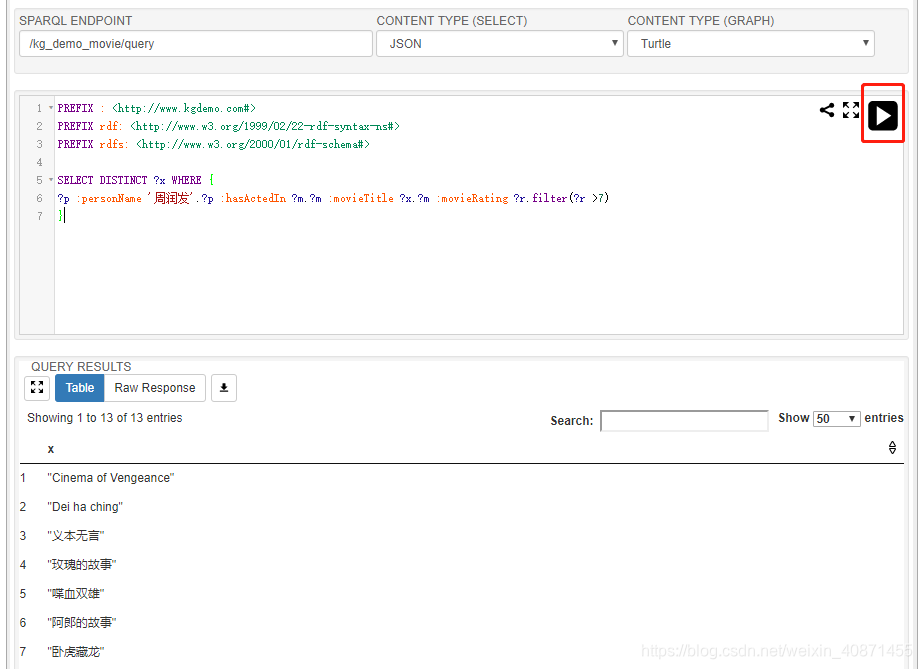
查询输入如下代码:
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?x WHERE {
?p :personName '周润发'.?p :hasActedIn ?m.?m :movieTitle ?x.?m :movieRating ?r.filter(?r >7)
}查询效果如下图:
这样fuseki服务器就启动好了,接下来在回到代码,在代码中访问fuseki服务,获取其返回值,例如我们查询周星驰的电影:
my_query = """
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?x WHERE {
?s :personName '周星驰'.?s :hasActedIn ?m.?m :movieTitle ?x
}
limit 1000
"""代码输出效果:
{'head': {'vars': ['x']}, 'results': {'bindings': [{'x': {'type': 'literal', 'value': '鹿鼎记 II : 神龙敎'}}, {'x': {'type': 'literal', 'value': 'Xiao tou a xing'}}, {'x': {'type': 'literal', 'value': '武状元苏乞儿'}}, {'x': {'type': 'literal', 'value': '最佳女婿'}}, {'x': {'type': 'literal', 'value': '大内密探零零发'}}, {'x': {'type': 'literal', 'value': '刑警本色'}}, {'x': {'type': 'literal', 'value': '长江七号'}}, {'x': {'type': 'literal', 'value': '无敌幸运星'}}, {'x': {'type': 'literal', 'value': '睹侠'}}, {'x': {'type': 'literal', 'value': '群星会'}}, {'x': {'type': 'literal', 'value': '少林足球'}}, {'x': {'type': 'literal', 'value': 'Man hua wei long'}}, {'x': {'type': 'literal', 'value': '师兄撞鬼'}}, {'x': {'type': 'literal', 'value': '整蛊专家'}}, {'x': {'type': 'literal', 'value': '逃学威龙'}}, {'x': {'type': 'literal', 'value': '审死官'}}, {'x': {'type': 'literal', 'value': 'Yi ben man hua chuang tian ya II miao xiang tian ka'}}, {'x': {'type': 'literal', 'value': '97 ga yau hei si'}}, {'x': {'type': 'literal', 'value': '阴阳界'}}, {'x': {'type': 'literal', 'value': '算死草'}}, {'x': {'type': 'literal', 'value': '龙的传人'}}, {'x': {'type': 'literal', 'value': '特技猛龙'}}, {'x': {'type': 'literal', 'value': '咖喱辣椒'}}, {'x': {'type': 'literal', 'value': '幸运一条龍'}}, {'x': {'type': 'literal', 'value': '喜剧之王'}}, {'x': {'type': 'literal', 'value': '龙在天涯'}}, {'x': {'type': 'literal', 'value': '望夫成龙'}}, {'x': {'type': 'literal', 'value': '破坏之王'}}, {'x': {'type': 'literal', 'value': '回魂夜'}}, {'x': {'type': 'literal', 'value': '济公'}}, {'x': {'type': 'literal', 'value': '捕风汉子'}}, {'x': {'type': 'literal', 'value': '神击大道'}}, {'x': {'type': 'literal', 'value': '国产凌凌漆'}}, {'x': {'type': 'literal', 'value': '龙凤茶楼'}}, {'x': {'type': 'literal', 'value': '千王之王 2000'}}, {'x': {'type': 'literal', 'value': 'Film ohne Fesseln - Das neue Hongkong Kino'}}, {'x': {'type': 'literal', 'value': '西游记第壹佰零壹回之月光宝盒'}}, {'x': {'type': 'literal', 'value': '新精武门1991'}}, {'x': {'type': 'literal', 'value': '百变星君'}}, {'x': {'type': 'literal', 'value': '江湖最后一个大路'}}, {'x': {'type': 'literal', 'value': '赌圣'}}, {'x': {'type': 'literal', 'value': '功夫'}}, {'x': {'type': 'literal', 'value': '风雨同路'}}, {'x': {'type': 'literal', 'value': '义胆群英'}}, {'x': {'type': 'literal', 'value': 'Fei zhou he shang'}}, {'x': {'type': 'literal', 'value': '豪门夜宴'}}, {'x': {'type': 'literal', 'value': '食神'}}, {'x': {'type': 'literal', 'value': '流氓差婆'}}, {'x': {'type': 'literal', 'value': '唐伯虎点秋香'}}, {'x': {'type': 'literal', 'value': '赌覇'}}, {'x': {'type': 'literal', 'value': '西游记大结局之仙履奇缘'}}, {'x': {'type': 'literal', 'value': '英雄本色'}}, {'x': {'type': 'literal', 'value': '九品芝麻官之白面包靑天'}}, {'x': {'type': 'literal', 'value': '一本漫画天涯'}}, {'x': {'type': 'literal', 'value': 'Final Justice'}}, {'x': {'type': 'literal', 'value': '建国大业'}}, {'x': {'type': 'literal', 'value': '琉璃樽'}}, {'x': {'type': 'literal', 'value': '逃学威龙 II'}}, {'x': {'type': 'literal', 'value': '家有囍事'}}, {'x': {'type': 'literal', 'value': '鹿鼎记'}}, {'x': {'type': 'literal', 'value': '逃学威龙 III 龙过鸡年'}}, {'x': {'type': 'literal', 'value': '赌侠 III 之上海滩赌圣'}}]}}
['鹿鼎记 II : 神龙敎', 'Xiao tou a xing', '武状元苏乞儿', '最佳女婿', '大内密探零零发', '刑警本色', '长江七号', '无敌幸运星', '睹侠', '群星会', '少林足球', 'Man hua wei long', '师兄撞鬼', '整蛊专家', '逃学威龙', '审死官', 'Yi ben man hua chuang tian ya II miao xiang tian ka', '97 ga yau hei si', '阴阳界', '算死草', '龙的传人', '特技猛龙', '咖喱辣椒', '幸运一条龍', '喜剧之王', '龙在天涯', '望夫成龙', '破坏之王', '回魂夜', '济公', '捕风汉子', '神击大道', '国产凌凌漆', '龙凤茶楼', '千王之王 2000', 'Film ohne Fesseln - Das neue Hongkong Kino', '西游记第壹佰零壹回之月光宝盒', '新精武门1991', '百变星君', '江湖最后一个大路', '赌圣', '功夫', '风雨同路', '义胆群英', 'Fei zhou he shang', '豪门夜宴', '食神', '流氓差婆', '唐伯虎点秋香', '赌覇', '西游记大结局之仙履奇缘', '英雄本色', '九品芝麻官之白面包靑天', '一本漫画天涯', 'Final Justice', '建国大业', '琉璃樽', '逃学威龙 II', '家有囍事', '鹿鼎记', '逃学威龙 III 龙过鸡年', '赌侠 III 之上海滩赌圣']
当然,如果代码真的这样写的话就是硬编码了,代码就被写死了,我们需要的效果是用户输入一句自然语言我们可以解析出一条查询语句,然后向fuseki服务器请求,如何将问句转换成sparql?
-
"question2sparql",这个文件就是将自然语言转为对应的SPARQL语句,看懂这个代码之前,我们需要知道基于规则的匹配
-
"question_temp",这个文件定义了SPARQL模板和匹配规则,我们就是通过这个匹配规则将自然语言转换成sparql的,主要的一些规则如下,当然这个只是句子的规则,还有词法的规则
rules = [
Rule(condition_num=2, condition=person_entity + Star(Any(), greedy=False) + movie + Star(Any(), greedy=False), action=QuestionSet.has_movie_question),
Rule(condition_num=2, condition=(movie_entity + Star(Any(), greedy=False) + actor + Star(Any(), greedy=False)) | (actor + Star(Any(), greedy=False) + movie_entity + Star(Any(), greedy=False)), action=QuestionSet.has_actor_question),
Rule(condition_num=3, condition=person_entity + Star(Any(), greedy=False) + person_entity + Star(Any(), greedy=False) + (movie | Star(Any(), greedy=False)), action=QuestionSet.has_cooperation_question),
Rule(condition_num=4, condition=person_entity + Star(Any(), greedy=False) + compare + number_entity + Star(Any(), greedy=False) + movie + Star(Any(), greedy=False), action=QuestionSet.has_compare_question),
Rule(condition_num=3, condition=person_entity + Star(Any(), greedy=False) + category + Star(Any(), greedy=False) + movie, action=QuestionSet.has_movie_type_question),
Rule(condition_num=3, condition=person_entity + Star(Any(), greedy=False) + genre + Star(Any(), greedy=False) + (movie | Star(Any(), greedy=False)), action=QuestionSet.has_specific_type_movie_question),
Rule(condition_num=3, condition=person_entity + Star(Any(), greedy=False) + several + Star(Any(), greedy=False) + (movie | Star(Any(), greedy=False)), action=QuestionSet.has_quantity_question),
Rule(condition_num=3, condition=person_entity + Star(Any(), greedy=False) + comedy + actor + Star(Any(), greedy=False), action=QuestionSet.is_comedian_question),
Rule(condition_num=3, condition=(person_entity + Star(Any(), greedy=False) + (when | where) + person_basic + Star(Any(), greedy=False)) | (person_entity + Star(Any(), greedy=False) + person_basic + Star(Any(), greedy=False)), action=QuestionSet.has_basic_person_info_question),
Rule(condition_num=2, condition=movie_entity + Star(Any(), greedy=False) + movie_basic + Star(Any(), greedy=False), action=QuestionSet.has_basic_movie_info_question)
]我们仔细观察,这些规则其实都是将人问问题的模式都考虑到了,如果你想法奇特,问了一个天马行空的问题,那系统就理解不了这句话,无法生成sparql进行查询,我们举个例子:我们问“周润发演了什么电影”,它就会匹配到上述规则的第一条,因为规则一condition后面跟的规则,首先就是person_entity人物实体,然后随便你再说点什么,它会匹配到Star(Any(), greedy=False),然后你提到电影这两个字,它会匹配到movie,后边你说或者不说话,它会匹配到Star(Any(), greedy=False);那么你可能就问了,凭什么周润发就能匹配到是一个人物实体?是这样,我们前面不是对句子进行了分词和词性标注吗,凡是标注为nr,我就认为这是个人物实体,标注为nz,我就认为是一个电影实体,另外还定义了很多其他比如电影分类、生日、出生地等,有了这些定义好的变量我们就可以进行匹配识别了
pos_person = "nr"
pos_movie = "nz"
pos_number = "m"
person_entity = (W(pos=pos_person))
movie_entity = (W(pos=pos_movie))
number_entity = (W(pos=pos_number))
adventure = W("冒险")
fantasy = W("奇幻")
animation = (W("动画") | W("动画片"))
drama = (W("剧情") | W("剧情片"))
thriller = (W("恐怖") | W("恐怖片"))
action = (W("动作") | W("动作片"))
comedy = (W("喜剧") | W("喜剧片"))
history = (W("历史") | W("历史剧"))
western = (W("西部") | W("西部片"))
horror = (W("惊悚") | W("惊悚片"))
crime = (W("犯罪") | W("犯罪片"))
documentary = (W("纪录") | W("纪录片"))
science_fiction = (W("科幻") | W("科幻片"))
mystery = (W("悬疑") | W("悬疑片"))
music = (W("音乐") | W("音乐片"))
romance = (W("爱情") | W("爱情片"))
family = W("家庭")
war = (W("战争") | W("战争片"))
TV = W("电视")
genre = (adventure | fantasy | animation | drama | thriller | action
| comedy | history | western | horror | crime | documentary |
science_fiction | mystery | music | romance | family | war | TV)
actor = (W("演员") | W("艺人") | W("表演者"))
movie = (W("电影") | W("影片") | W("片子") | W("片") | W("剧"))
category = (W("类型") | W("种类"))
several = (W("多少") | W("几部"))
higher = (W("大于") | W("高于"))
lower = (W("小于") | W("低于"))
compare = (higher | lower)
birth = (W("生日") | W("出生") + W("日期") | W("出生"))
birth_place = (W("出生地") | W("出生"))
english_name = (W("英文名") | W("英文") + W("名字"))
introduction = (W("介绍") | W("是") + W("谁") | W("简介"))
person_basic = (birth | birth_place | english_name | introduction)
rating = (W("评分") | W("分") | W("分数"))
release = (W("上映"))
movie_basic = (rating | introduction | release)
when = (W("何时") | W("时候"))
where = (W("哪里") | W("哪儿") | W("何地") | W("何处") | W("在") + W("哪"))这样匹配好之后就会调用规则中的 action = QuestionSet.has_movie_question,这个函数来生成sparql
def has_movie_question(word_objects):
select = u"?x"
sparql = None
for w in word_objects:
if w.pos == pos_person:
e = u"?s :personName '{person}'." \
u"?s :hasActedIn ?m." \
u"?m :movieTitle ?x".format(person=w.token.decode('utf-8'))
sparql = SPARQL_SELECT_TEM.format(prefix=SPARQL_PREXIX,
select=select,
expression=e)
break
return sparql-
"query_main",main函数,用户运行程序的入口函数,在启动这个程序之前,需要先启动fuseki服务器,如上所述。
主函数运行效果如下:

以上是这个项目的大概思路,其中用到的D2R,从关系数据库中提取rdf,使用Jena进行推理等,我这里并没有涉及,我的另一篇博客中有关于D2R的介绍。
总结:这种基于规则的问答可解释性比较强,如果某个问题解析错误,我们只要找到对应的匹配规则进行调试即可;相对于深度学习的端到端黑盒模型,如果有的地方问答出现谬误,我们并不能准确给出其原因,也并不能立即找到合适的解决方案;这种问答模型比较适合固定的业务领域,适合问题数量和问题模式可数可罗列的情况,我们可以将规则做的很细致,将其鲁棒性调试到最优,让其有很强的泛化能力;但是,如果用于开放领域的问答,那么问题的数量将是不可数的,我们没办法做出足够多的规则去匹配,这就需要借助一些机器学习和深度学习的方法;在没有数据或者数据极少的情况下,我们可以利用正则规则马上上线一个初级的问答系统。在现实情况中,由于上述优点,工业界也比较青睐用正则来做语义解析。基于规则的缺陷也是显而易见的,它并不能理解语义信息,而是基于符号的匹配。换个角度说,用规则的方法,就需要规则的设计者能够尽可能考虑到所有情况,然而这是不可能的。暂且不考虑同义词、句子结构等问题,光是罗列所有可能的问题就需要花费很大的功夫。尽管如此,在某些垂直领域,比如“音乐”,“电影”,由于问题集合的规模在一定程度上是可控的,基于规则的问答系统还是有很大的用武之地的。