一:引言
- 今天,我们搞了一个聚会,邀请整个家庭的人来参加,有A,B,C......等十几个人
- 这时候,突然A的儿子来了,说我想知道A是否来参加了聚会。
- 于是我们拿出了参会人员的名单册(哈希表等内存方法),根据这个表,我们马上找出了A来参加了这个聚会,完美的解决的这个问题。
- 之后过来一段时间,我们在学校搞了一场讲座,人很多,足足有两千多人
- 这时,有个同学过来了,说导师找C有些事,想问下是不是在我们这个讲座里面。
- 这时我们拿出来名单册,这时我们犯了愁,这个表很多,于是我们一个个找,终于找到了C......
- 这时又来了很多同学询问D.E.F....的存在,我们焦头烂额的把这些人找了出来。
- 后来,有一个大型的集会需要组织,足足有几万人,吸取了上次的教训,我们不打算记录所有人的名字了。
- 这时候,我们列出了3百多项人的特性(身高,体重,性别.....)
- 这时A来参加集会,我们记录(男,180左右,红帽子,绿衣服,黑裤子,白鞋子)
- 这时B来参加集会,我们记录(女,170左右,没帽子,黑衣服,黑裤子,白鞋子)
- ....
- 这时候有人来问 A 是否在这个集会中,我们只需要看你的特征是否满足就可以了。
- 这就是 布隆过滤器
二:算法背景
- 在查询一个元素是否存在一个集合时候,一般想到的方式是把内容保存起来,之后可以通过 哈希/链表/树 等存储,之后可以快速查找(类似上面故事中的名单册一样)。
- 这种以空间换时间的方式,在大部分情况下是可行的。
- 但是在面对很大数据量的时候,存储量/检索时间 都会变得难以控制。
- 布隆过滤器(Bloom-Filter) 就是为了解决这种情况,消耗小的空间/时间,来检索数据。
二:什么是布隆过滤器(Bloom-Filter)
- 布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。
- 它实际上是一个很长的二进制向量和一系列随机映射函数。
- 布隆过滤器可以用于检索一个元素是否在一个集合中。
- 它的优点是空间效率和查询时间都远远超过一般的算法。
- 缺点是有一定的误识别率和删除困难。
三:原理
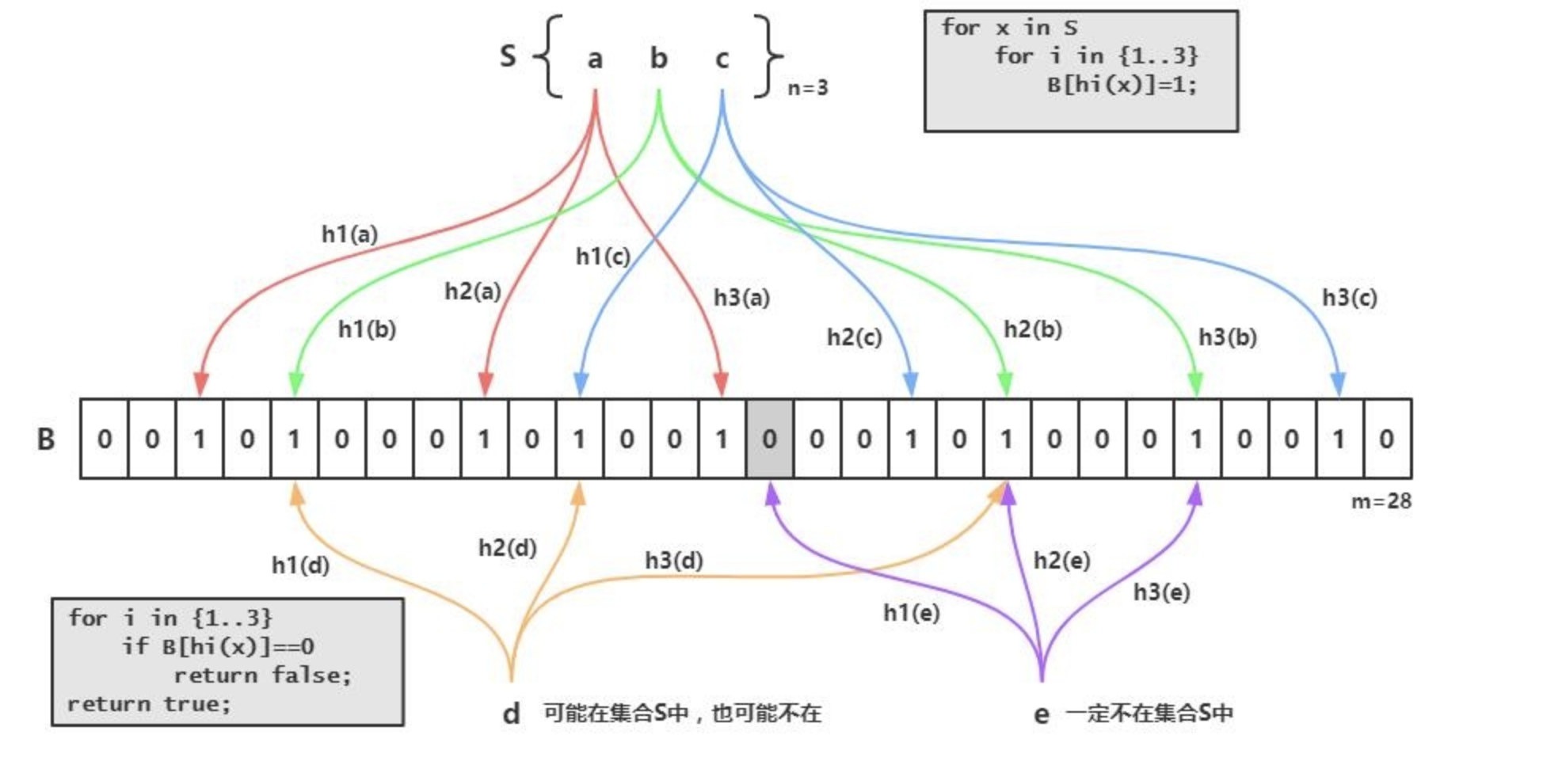
- 布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点(特征),把它们置为1。
- 检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;
- 如果都是1,则被检元素很可能在。
- 这就是布隆过滤器的基本思想。
- 
四:缺点
- 存在误判
- 可能冲突,就像两个人的特性很相似一样
- 删除困难
- 一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。
五:参考