版权声明:本文为博主原创文章,未经博主允许不得转载 https://blog.csdn.net/qq_34018840/article/details/79883039
PM的模拟
参考链接:如何模拟PM。但是这样使用DRAM模拟出来的PM在未做任何修改(添加写入延迟)的情况下实际是以DRAM速度在进行读写访问。
添加写入延迟
通过在系统的cflush操作后添加写入延迟(个人添加为150ns)来模拟PM。具体操作为:
1、将头文件latency.h放入目录/linux-nova/linux-nova/include/linux下,latency.h的代码如下所示。
/* Emulate latency */
#undef PCM_EMULATE_LATENCY
#define PCM_EMULATE_LATENCY 0x1
/* CPU frequency */
#define PCM_CPUFREQ 2100LLU /* GHz */
/* PCM write latency*/
#define PCM_LATENCY_WRITE 150 /* ns */
/* PCM write bandwidth */
#define PCM_BANDWIDTH_MB 4000
//#define PCM_BANDWIDTH_MB 600
//#define PCM_BANDWIDTH_MB 300
//2000:150ns(PCM speed in theory),300:1000ns(practical speed of PCM),150:2000ns
/* DRAM system peak bandwidth */
#define DRAM_BANDWIDTH_MB 24000
#define NS2CYCLE(__ns) ((__ns) * PCM_CPUFREQ / 1000)
#define CYCLE2NS(__cycles) ((__cycles) * 1000 / PCM_CPUFREQ)
#define gethrtime asm_rdtsc
/* Public types */
typedef uint64_t pcm_hrtime_t;
#if defined(__i386__)
static inline unsigned long long asm_rdtsc(void)
{
unsigned long long int x;
__asm__ volatile (".byte 0x0f, 0x31" : "=A" (x));
return x;
}
static inline unsigned long long asm_rdtscp(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtscp" : "=a"(lo), "=d"(hi)::"ecx");
return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 );
}
#elif defined(__x86_64__)
static inline unsigned long long asm_rdtsc(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));
return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 );
}
static inline unsigned long long asm_rdtscp(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtscp" : "=a"(lo), "=d"(hi)::"rcx");
return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 );
}
#else
#error "What architecture is this???"
#endif
static inline
void
emulate_latency_ns(int ns)
{
pcm_hrtime_t cycles;
pcm_hrtime_t start;
pcm_hrtime_t stop;
start = asm_rdtsc();
cycles = NS2CYCLE(((ns + 63) / 64) * PCM_LATENCY_WRITE);
do {
/* RDTSC doesn't necessarily wait for previous instructions to complete
* so a serializing instruction is usually used to ensure previous
* instructions have completed. However, in our case this is a desirable
* property since we want to overlap the latency we emulate with the
* actual latency of the emulated instruction.
*/
stop = asm_rdtsc();
} while (stop - start < cycles);
}
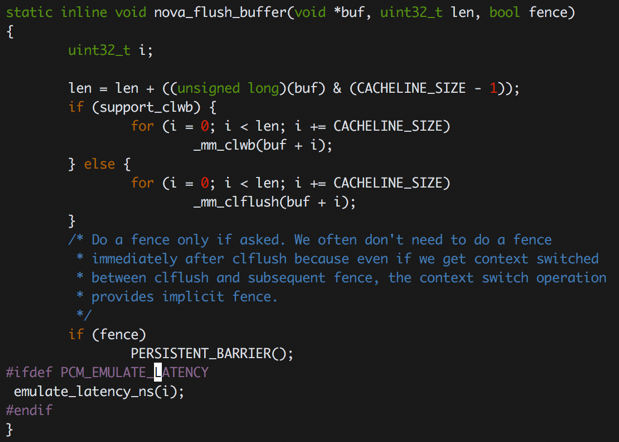
2、修改/linux-nova/fs/fs/nova目录下的nova_def.h头文件中的nova_flush_buffer()函数如下图所示,添加最后三行代码,并在文件开头添加引用#include <linux/latency.h>。其中emulate_latency_ns()函数为头文件latency.h中的。
3、之后重新在/linux-nova/fs/nova目录下编译nova模块,完成挂载即可。