什么是PCA
主成分分析,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。在数据压缩消除冗余和数据噪音消除领域都有广泛应用。
具体的,假如我们的数据集是n维的,共有m个数据(x(1),x(2),…,x(m))。我们希望将这m个数据的维度从n维降到n’维,希望这m个n’维的数据集尽可能的代表原始数据集。我们知道数据从n维降到n’维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这n’维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2,n’=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
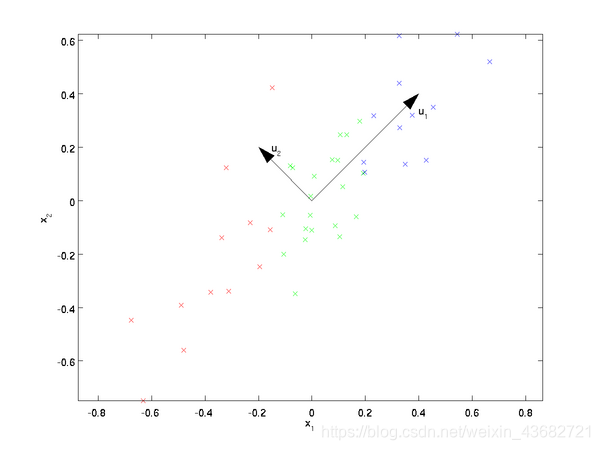
为什么u1比u2好呢?可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开。
假如我们把n’从1维推广到任意维,则我们的希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导。
更多推导过程可以参见:https://www.cnblogs.com/pinard/p/6239403.html
下面这篇文章讲得也非常详细:
https://blog.csdn.net/zhongkelee/article/details/44064401
使用梯度上升法求解PCA问题
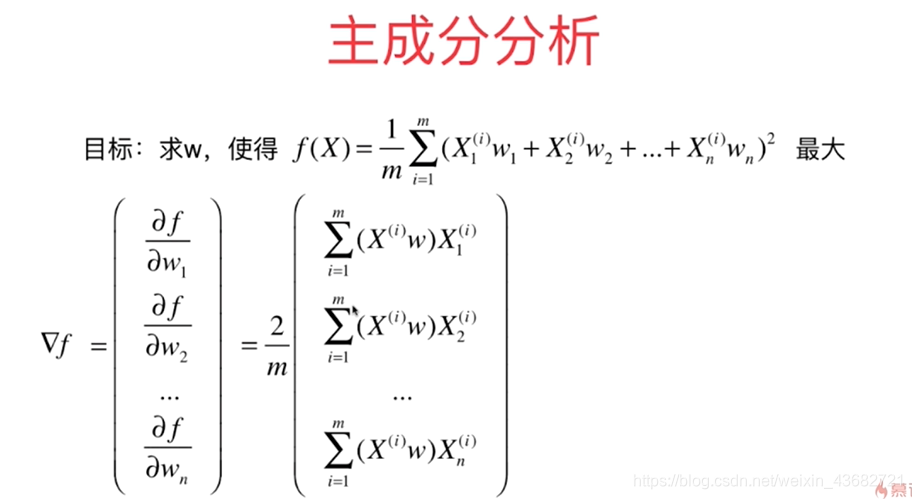
目标函数及其梯度:

求数据的主成分PCA
import numpy as np
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
'''目标函数,求该函数最大值'''
return np.sum((X.dot(w) ** 2)) / len(X)
def df_math(w, X):
'''求解梯度方法1'''
return X.T.dot(X.dot(w)) * 2. / len(X)
def df_debug(w, X, epsilon=0.0001):
'''求解梯度方法2'''
res = np.empty(len(w))
for i in range(len(w)):
w_1 = w.copy()
w_1[i] += epsilon
w_2 = w.copy()
w_2[i] -= epsilon
res[i] = (f(w_1, X) - f(w_2, X)) / (2 * epsilon)
return res
def direction(w):
'''化为单位向量'''
return w / np.linalg.norm(w)
def gradient_ascent(df, X, initial_w, eta, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w) # 注意1:初始向量不能使用0向量
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w) # 注意2:每次求一个单位方向
if(abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10., size=100)
X_demean = demean(X)
print(np.mean(X_demean[:, 1]))
initial_w = np.random.random(X.shape[1])
eta = 0.001
ga1 = gradient_ascent(df_math, X_demean, initial_w, eta)
print(ga1)
ga2 = gradient_ascent(df_debug, X_demean, initial_w, eta)
print(ga2)
求数据的前n个主成分
Q:求出第一主成分后,如何求出下一个主成分?
A:将数据进行改变,即将数据在第一主成分的分量去掉,然后在新的数据上求第一主成分即可求出下一主成分。
def first_n_component(n,X,eta=0.01,n_iters= 1e4,epsilon=1e8):
X_pca = X.copy()
X_pca = demean(X_pca)
res = []
for i in range(n):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca,initial_w,eta) #first_component与上面的gradient_ascent相同
res.append(w)
X_pca = X_pca - X_pca.dot(w).reshape(-1,1) * w
return res
高维数据向低维数据映射
将高维数据中表示数据的向量与计算得到的主成分向量相乘,可以得到该数据在该主成分上的表示;同理可以得到在其他主成分上的表示。最终高维数据向低维数据映射变成数据矩阵与前k个主成分组成的矩阵的转置相乘。
PCA数据降维方法封装如下:
import numpy as np
class PCA:
def __init__(self, n_components):
'''初始化PCA'''
assert n_components >= 1, 'n_components must be valid'
self.n_components = n_components
self.components_ = None
def fit(self, X, eta=0.01, n_iters=1e4):
'''获得数据集X的前n个主成分'''
assert X.shape[1] >= self.n_components, 'n_components must smaller than the feature of X'
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
'''目标函数,求该函数最大值'''
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w, X):
'''求解梯度'''
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
return w / np.linalg.norm(w)
def first_component(X, initial_w, eta, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w) # 注意2:初始向量不能使用0向量
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w) # 注意1:每次求一个单位方向
if(abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X_pca = demean(X)
self.components_ = np.empty(shape=(self.n_components, X.shape[1]))
for i in range(self.n_components):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta, n_iters)
self.components_[i, :] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
'''将数据集X映射到PCA中得到的主成分中,实现数据降维'''
assert X.shape[1] == self.components_.shape[1], 'the feature number of X must equal to the feature number of self.components_'
return X.dot(self.components_.T)
def inverse_transform(self, X):
'''对于给定的数据集X,反向映射回原来的高维特征空间'''
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return 'PCA(n_components=%d)' % self.n_components
# 模拟数据集
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10., size=100)
# 测试
pca = PCA(n_components=1)
pca.fit(X)
X_reduction = pca.transform(X)
print(pca.components_)
print(X_reduction.shape)
X_restore = pca.inverse_transform(X_reduction)
print(X_restore.shape)
scikit-learn中的PCA
对数据进行降维后,可能会丢失一定的信息,但是可以换取运行时间。
import numpy as np
from sklearn.decomposition import PCA
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 导入数据集
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 666)
# 用PCA对数据进行降维
pca = PCA(0.95) #也可以指定识别率,自动确定降维后的维数
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
print(pca.explained_variance_ratio_)
# 将降维后的数据用kNN进行分析
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
score = knn_clf.score(X_test_reduction,y_test)
print(score)
试手MNIST数据集
PCA除对数据进行降维外,还对数据进行降噪,因此在对MNIST数据集进行PCA处理后,再使用kNN进行预测,不仅能节省计算时间,还能提高识别准确度。
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_mldata
from sklearn.neighbors import KNeighborsClassifier
mnist = fetch_mldata('MNIST original',data_home='./')
X,y = mnist['data'],mnist['target']
X_train = np.array(X[:60000],dtype=float)
y_train = np.array(y[:60000],dtype=float)
X_test = np.array(X[60000:],dtype=float)
y_test = np.array(y[60000:],dtype=float)
# 用PCA对数据进行降维
pca = PCA(100) #也可以指定识别率,自动确定降维后的维数
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
# 将降维后的数据用kNN进行分析
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
score = knn_clf.score(X_test_reduction,y_test)
print(score)
使用PCA对数据进行降噪
将数据从高维降到低维的过程中,丢失了一些信息,因此也丢失了一些噪音,所以PCA对数据具有降噪作用。
人脸识别与特征脸
from sklearn.datasets import fetch_lfw_people
上面的数据为人脸数据,特征脸即为降维后新的特征。