版权声明:版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/z_feng12489/article/details/89188234
6. 多层感知机与分类器
逻辑回归
- 对于逻辑回归我们不能直接最大化 accuracy。
• acc.=
• grad 出现等于零的情况。
• grad 不连续。 - 为什么叫 regression。
• MSE−− >regression.
• cross entropy−− >classification. - 多类:
• 实现多个二分类器。
• softmax。
交叉熵
-
Entropy
- uncertain 不确定度
- measure of surprise 惊喜程度
- higher entropy = less info
-
Cross Entropy
对于分类什么不用MSE :
- sigmoid+MSE(梯度弥散)。
- 收敛非常慢。
- 但是有时可以试试MSE,求导简单。
小结
一般不建议自己单独使用 softmax 与 cross entropy。使用 pytorch 组合的框架。
import torch
from torch.nn import functional as F
x = torch.randn(1,784)
w = torch.randn(10,784)
logits = x@w.t()
pred = F.softmax(logits, dim=1)
pred_log = torch.log(pred)
F.nll_loss(pred_log, torch.tensor([1]))
#F.cross_entropy=F.softmax+log+F.nll_loss
F.cross_entropy(logits, torch.tensor([1]))
多分类实战-Minst
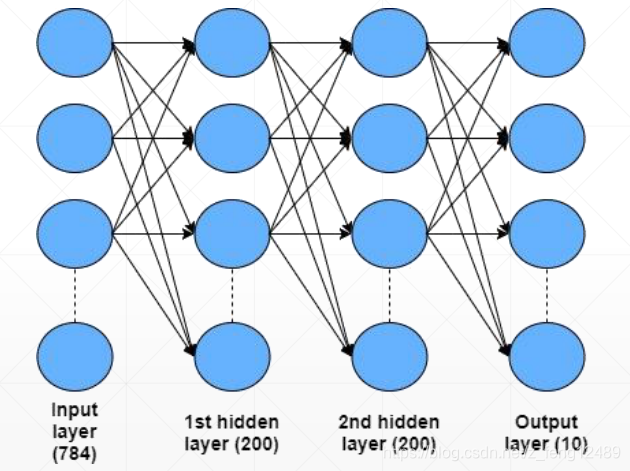
建立网络 :
w1, b1 = torch.randn(200, 784, requires_grad=True), torch.zeros(200,
requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True), torch.zeros(200,
requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True), torch.zeros(10,
requires_grad=True)
#向前传播
def forward(x):
x = x@w1.t()+b1
x = F.relu(x)
x = x@w2.t()+b2
x = F.relu(x)
x = x@w3.t()+b3
x = F.relu(x)
return x
训练 :
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
#训练
for batch_idx, (data, target) in enumerate(train_loader):
data = data.reshape(-1, 28*28) #torch.Size([200, 784])
logits = forward(data) #torch.Size([200, 10])
loss = criteon(logits, target)
optimizer.zero_grad() #梯度清零
loss.backward() #反向回传
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step() #更新梯度值
通过打印 weight.grad.norm(),得知常常陷入局部极小值。解决这个问题可以利用何
凯明的初始化方法。
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
全连接层
在上节中,我们未用 PyTorch 封装的 API 去建立神经网络,这节来使用 PyTorch
封装的 API。
- 继承 nn.module 类
- 用 init 来初始化
- 应用向前传播
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
PyTorch 两 种 风 格 的API
- class-style API (nn.***)
- function-style API (F.***)
没有遇到上节遇到的初始化问题,参数未暴露给用户,拥有自己的初始化体系,一
般来说够用,否则自己必须编写相应的初始化代码。
激活函数与GPU加速
常用激活函数
- Sigmoid
- ReLu
- tanh
- Leaky ReLu
- SELU
- softplus
一键部署 GPU 加速
device = torch.device(cuda)
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
time1 = time.time()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
测试与可视化
测试
神经网络的表达能力非 强,容易过拟合,所以要测试 。不能单一观测测Loss 的大小判断模型的好坏,还要观测测试集的准确度,确保模型的泛化能力。
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(1)
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
可视化
通过pip install visdom等方式成功安装完之后,开启服务
python -m visdom.server
出现了Mnist图片 viz.images() 全黑故障,是由于样本 normalization 引起的,要进行反归一化才可正常显示。