-
每个索引都对应一棵
B+树,B+树分为好多层,最下边一层是叶子节点,其余的是内节点。所有用户记录都存储在B+树的叶子节点,所有目录项记录都存储在内节点。 -
InnoDB存储引擎会自动为主键(如果没有它会自动帮我们添加)建立聚簇索引,聚簇索引的叶子节点包含完整的用户记录。 -
我们可以为自己感兴趣的列建立
二级索引,二级索引的叶子节点包含的用户记录由索引列 + 主键组成,所以如果想通过二级索引来查找完整的用户记录的话,需要通过回表操作,也就是在通过二级索引找到主键值之后再到聚簇索引中查找完整的用户记录。 -
B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引的话,则页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序。 -
通过索引查找记录是从
B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory(页目录),所以在这些页面中的查找非常
首先我们需要知道在innoDB中一条记录的格式:
将记录格式的其他信息去掉并把它竖起来的效果就是这样
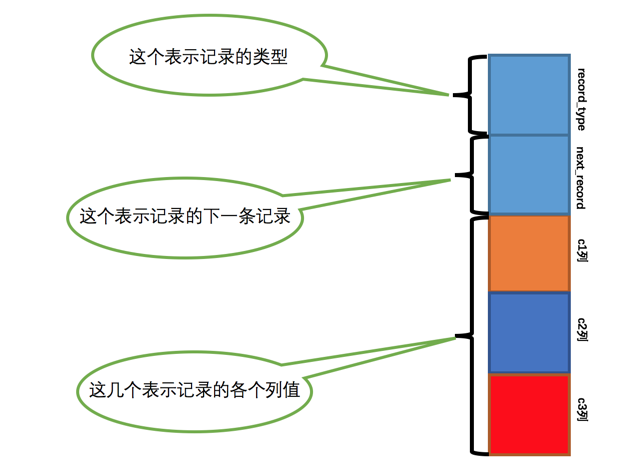
把一些记录放到页里边的示意图就是:
注意record_type的取值不同,代表着该条记录有不同的含义:
一个页面里面里的记录通过next_record指针串成一个链表,为了查找方便,为这个链表设置了两个虚拟头节点: 最小记录和最大记录:
record_type = 1表示是最小记录,record_type = 3表示是最大记录。
record_type = 0表示是普通用户记录。
record_type = 2表示是索引项目记录。这个后面再说。
页分裂
假设我们的每个数据页最多能存放3条记录(实际上一个数据页非常大,可以存放下好多记录),innoDB在插入数据项的时候,会按照主键值的大小顺序串联成一个单向链表:
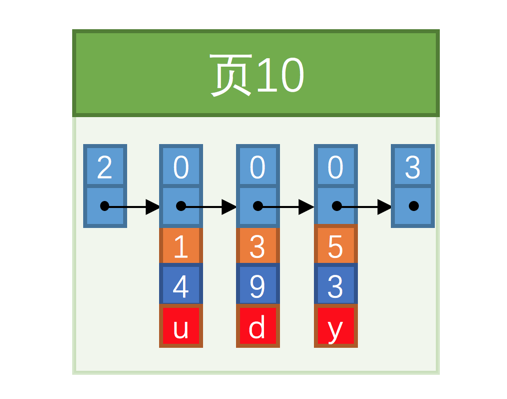
上图中的三条记录按照主键(橙色)由小到大的顺序串成一个链表
此时我们再插入一条记录,因为页10最多只能放3条记录,所以我们不得不再分配一个新页:
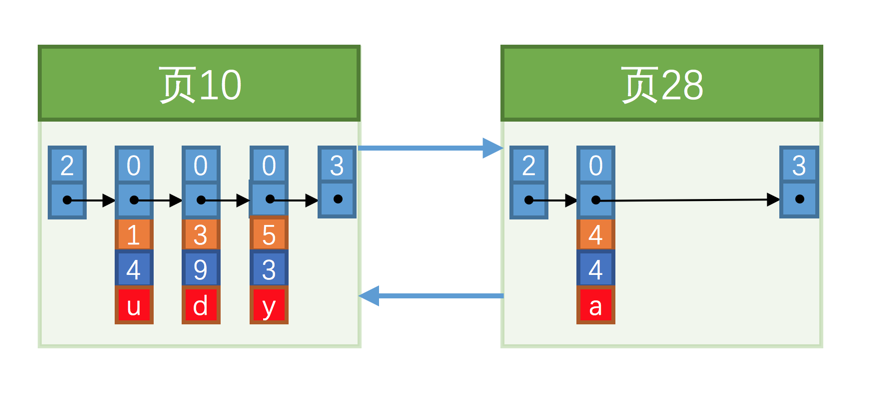
页10中用户记录最大的主键值是5,而页28中有一条记录的主键值是4,因为5 > 4,所以这就不符合下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所以在插入主键值为4的记录的时候需要伴随着一次记录移动,也就是把主键值为5的记录移动到页28中,然后再把主键值为4的记录插入到页10中。我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。这个过程我们也可以称为页分裂。
其他的部分见掘金小测!