文章目录
- 一、RDD
- 二、RDD的操作
- 1、RDD的类型
- 2、RDD的创建
- 3、RDD的转换
- Transformation
- <1>map
- <2>filter
- <3>flatMap
- <4>mapPartitions
- <5>mapPartitionsWithIndex
- <6>sample
- <7>union
- <8>intersection
- <9>distinct
- <10>partitionBy
- <11>reduceByKey
- <12>groupByKey
- <13>combineByKey
- <14>aggregateByKey
- <15>foldByKey
- <16>sortByKey
- <17>sortBy
- <18>join
- <19>repartition
- <20>coalesce
- <21>subtract
- 4、RDD的行动
- Action
- <1>reduce
- <2>collect
- <3>count
- <4>take
- <5>first
- <6>takeSample
- <7>takeOrdered
- <8>aggregate
- <9>fold
- <10>saveAsTextFile
- <11> saveAsSequenceFile
- <12>saveAsObjectFile
- <13>countByKey
- <14>foreach
- 5、数值RDD的统计操作
一、RDD
1、什么是RDD
RDD是Spark为简化用户的使用,对所有的底层数据进行的抽象,以面向对象的方式提供了RDD很多的方法,通过这些方法来对RDD进行计算和输出。RDD是Spark的基石,所有上层模块全部都是由RDD来实现的。
2、RDD的特点
1、不可变:对于所有RDD的操作都是产生一个新的RDD。
2、可分区:RDD是通过将数据进行分区保存的。
3、弹性:
- [1 ]存储的弹性:内存与磁盘的自动转换
- [2 ]容错的弹性:数据丢失可以自动修复
- [3 ]计算的弹性:计算出错重试机制
- [4 ]分片的弹性:根据需要重新分片
3、Spark在内部都做了些什么

4、RDD的属性
注意:RDD是懒执行的,分为转换和行动操作,行动操作负责触发RDD执行
二、RDD的操作
1、RDD的类型
- [1]数值型RDD RDD.scala
- [2]键值对RDD PairRDDFunctions.scala
2、RDD的创建
- [1]从集合中创建
方法:使用makeRDD、parallelize
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
scala> sc.parallelize(Array(1, 2, 3))
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:25
scala> res0.collect
res1: Array[Int] = Array(1, 2, 3)
- [2] 从外面存储创建RDD
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,不如HDFS、HBase等 - [3]从其他RDD转换
3、RDD的转换
Transformation
<1>map
/** 一对一转换*/
def map[U: ClassTag](f: T => U): RDD[U]map ==>
scala> var source = sc.parallelize(1 to 10)
source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at parallelize at <console>:24
scala> source.collect()
res7: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val mapadd = source.map(_ * 2)
mapadd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[9] at map at <console>:26
<2>filter
/**filter => 传入一个布尔值、过滤数据 */
def filter(f: T => Boolean): RDD[T]
scala> var sourceFilter = sc.parallelize(Array("xiaoming","xiaojiang","xiaohe","tingting"))
sourceFilter: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[10] at parallelize at <console>:24
scala> val filter = sourceFilter.filter(_.contains("xiao"))
filter: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at filter at <console>:26
scala> sourceFilter.collect()
res9: Array[String] = Array(xiaoming, xiaojiang, xiaohe, tingting)
scala> filter.collect()
res10: Array[String] = Array(xiaoming, xiaojiang, xiaohe)
<3>flatMap
/** filterMap=>一对多,并将多压平 */
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
scala> val sourceFlat = sc.parallelize(1 to 5)
sourceFlat: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:24
scala> sourceFlat.collect()
res11: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val flatMap = sourceFlat.flatMap(1 to _)
flatMap: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[13] at flatMap at <console>:26
scala> flatMap.collect()
res12: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5)
<4>mapPartitions
/** mapPartitions =>对于一个分区中的所有数据执行一个函数 */
def mapPartitions[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U]
scala> sc.makeRDD(1 to 10)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> res1.mapPartitions(x=>x.filter(_ % 2==0).map("Partition"+_))
res12: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at mapPartitions at <console>:27
scala> res12.collect
res13: Array[String] = Array(Partition2, Partition4, Partition6, Partition8, Partition10)
<5>mapPartitionsWithIndex
/**类似于mapPartitions,但func带有一个整数参数表示分片的索引值,
因此在类型为T的RDD上运行时,
func的函数类型必须是(Int, Interator[T]) => Iterator[U]
*/
scala> var rdd = sc.makeRDD(1 to 50,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at makeRDD at <console>:24
scala> rdd.collect
res15: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50)
scala> rdd.partitions.size
res16: Int = 5
scala> rdd.mapPartitionsWithIndex((i,x)=>Iterator(i + ":["+x.mkString(",")+"]"))
res17: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[9] at mapPartitionsWithIndex at <console>:27
scala> res17.collect
res18: Array[String] = Array(0:[1,2,3,4,5,6,7,8,9,10], 1:[11,12,13,14,15,16,17,18,19,20], 2:[21,22,23,24,25,26,27,28,29,30], 3:[31,32,33,34,35,36,37,38,39,40], 4:[41,42,43,44,45,46,47,48,49,50])
<6>sample
/**sample 用于抽样
withReplacement:是否随机抽样
fraction:挑选出来元素的比例
seed:指定随机数生成器种子
*/
def sample(withReplacement: Boolean,fraction: Double,seed: Long = Utils.random.nextLong): RDD[T]
scala> val rdd = sc.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[20] at parallelize at <console>:24
scala> rdd.collect()
res15: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> var sample1 = rdd.sample(true,0.4,2)
sample1: org.apache.spark.rdd.RDD[Int] = PartitionwiseSampledRDD[21] at sample at <console>:26
scala> sample1.collect()
res16: Array[Int] = Array(1, 2, 2, 7, 7, 8, 9)
scala> var sample2 = rdd.sample(false,0.2,3)
sample2: org.apache.spark.rdd.RDD[Int] = PartitionwiseSampledRDD[22] at sample at <console>:26
scala> sample2.collect()
res17: Array[Int] = Array(1, 9)
<7>union
/** 联合一个RDD,组合成一个新的RDD*/
def union(other: RDD[T]): RDD[T]
scala> val rdd1 = sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(5 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[24] at parallelize at <console>:24
scala> val rdd3 = rdd1.union(rdd2)
rdd3: org.apache.spark.rdd.RDD[Int] = UnionRDD[25] at union at <console>:28
scala> rdd3.collect()
res18: Array[Int] = Array(1, 2, 3, 4, 5, 5, 6, 7, 8, 9, 10)
<8>intersection
/**求交集 */
def intersection(other: RDD[T]): RDD[T]
scala> val rdd1 = sc.parallelize(1 to 7)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(5 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:24
scala> val rdd3 = rdd1.intersection(rdd2)
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[33] at intersection at <console>:28
scala> rdd3.collect()
[Stage 15:=============================> (2 + 2)
res19: Array[Int] = Array(5, 6, 7)
<9>distinct
/**对源RDD去重后返回一个新的RDD */
def distinct(): RDD[T]
scala> val distinctRdd = sc.parallelize(List(1,2,1,5,2,9,6,1))
distinctRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at <console>:24
scala> val unionRDD = distinctRdd.distinct()
unionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[37] at distinct at <console>:26
scala> unionRDD.collect()
[Stage 16:> (0 + 4) [Stage 16:=============================> (2 + 2) res20: Array[Int] = Array(1, 9, 5, 6, 2)
scala> val unionRDD = distinctRdd.distinct(2)
unionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[40] at distinct at <console>:26
scala> unionRDD.collect()
res21: Array[Int] = Array(6, 2, 1, 9, 5)
<10>partitionBy
/**对RDD进行分区,如果分区数和原分区一样不进行分区,反之则进行分区 */
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
scala> val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4)
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[44] at parallelize at <console>:24
scala> rdd.partitions.size
res24: Int = 4
scala> var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[45] at partitionBy at <console>:26
scala> rdd2.partitions.size
res25: Int = 2
<11>reduceByKey
/** 根据key聚合,预聚合*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
scala> val rdd = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[46] at parallelize at <console>:24
scala> val reduce = rdd.reduceByKey((x,y) => x+y)
reduce: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[47] at reduceByKey at <console>:26
scala> reduce.collect()
res29: Array[(String, Int)] = Array((female,6), (male,7))
<12>groupByKey
/**将key相同的value聚合在一起 */
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
scala> val words = Array("one", "two", "two", "three", "three", "three")
words: Array[String] = Array(one, two, two, three, three, three)
scala> val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
wordPairsRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at map at <console>:26
scala> val group = wordPairsRDD.groupByKey()
group: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[5] at groupByKey at <console>:28
scala> group.collect()
res1: Array[(String, Iterable[Int])] = Array((two,CompactBuffer(1, 1)), (one,CompactBuffer(1)), (three,CompactBuffer(1, 1, 1)))
scala> group.map(t => (t._1, t._2.sum))
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[6] at map at <console>:31
scala> res2.collect()
res3: Array[(String, Int)] = Array((two,2), (one,1), (three,3))
<13>combineByKey
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
scala> var rdd = sc.makeRDD(Array(("a",100),("a",90),("a",80),("b",90),("b",80),("c",70),("c",60)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> rdd.combineByKey(v=>(v,1),(c:(Int,Int),v)=>(c._1+v,c._2+1),(c1:(Int,Int),c2:(Int,Int))=>(c1._1+c2._1,c1._2+c2._2))
res0: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[1] at combineByKey at <console>:27
scala> res0.collect
res1: Array[(String, (Int, Int))] = Array((a,(270,3)), (b,(170,2)), (c,(130,2)))
scala> res0.map{case (k,v:(Int,Int))=>(k,v._1/v._2)}.collect
res2: Array[(String, Int)] = Array((a,90), (b,85), (c,65))
<14>aggregateByKey
/** 是combineByKey简化版,可以通过zeroValue直接提供一个初始值*/
def aggregateByKey[U: ClassTag]
(zeroValue: U, partitioner: Partitioner)
(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[12] at parallelize at <console>:24
scala> val agg = rdd.aggregateByKey(0)(math.max(_,_),_+_)
agg: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[13] at aggregateByKey at <console>:26
scala> agg.collect()
res7: Array[(Int, Int)] = Array((3,8), (1,7), (2,3))
<15>foldByKey
/** 是aggregateByKey的简化版,seqOp、combOp相等 */
def foldByKey(zeroValue: V, numPartitions: Int)(func: (V, V) => V): RDD[(K, V)]
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[91] at parallelize at <console>:24
scala> val agg = rdd.foldByKey(0)(_+_)
agg: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[92] at foldByKey at <console>:26
scala> agg.collect()
res61: Array[(Int, Int)] = Array((3,14), (1,9), (2,3))
<16>sortByKey
/** 根据key聚合,预聚合进行排序,如果key目前不支持排序,
需要with Ordering接口,实现compare方法,告知spark key的大小判定
*/
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length):RDD[(K, V)]
scala> val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[14] at parallelize at <console>:24
scala> rdd.sortByKey(true).collect()
res9: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
scala> rdd.sortByKey(false).collect()
res10: Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))
<17>sortBy
/** 根据f函数提供可以对key进行排序 */
def sortBy[K](f: (T) => K,ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
scala> val rdd = sc.parallelize(List(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[21] at parallelize at <console>:24
scala> rdd.sortBy(x => x).collect()
res11: Array[Int] = Array(1, 2, 3, 4)
scala> rdd.sortBy(x => x%3).collect()
res12: Array[Int] = Array(3, 4, 1, 2)
<18>join
/** 将俩个RDD数据连接在一起组合成一个新的RDD */
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
scala> val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[32] at parallelize at <console>:24
scala> val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[33] at parallelize at <console>:24
scala> rdd.join(rdd1).collect()
res13: Array[(Int, (String, Int))] = Array((1,(a,4)), (2,(b,5)), (3,(c,6)))
<19>repartition
/** 对RDD原有的分区进行重新分区*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
scala> val rdd = sc.parallelize(1 to 16,4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at parallelize at <console>:24
scala> rdd.partitions.size
res22: Int = 4
scala> val rerdd = rdd.repartition(2)
rerdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[60] at repartition at <console>:26
scala> rerdd.partitions.size
res23: Int = 2
<20>coalesce
/** 缩减分区数,用于大数据集过滤后,提高小数据集的执行效率 */
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null): RDD[T]
scala> val rdd = sc.parallelize(1 to 16,4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[54] at parallelize at <console>:24
scala> rdd.partitions.size
res20: Int = 4
scala> val coalesceRDD = rdd.coalesce(3)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[55] at coalesce at <console>:26
scala> coalesceRDD.partitions.size
res21: Int = 3
<21>subtract
/** 去掉和other相同的元素*/
def subtract(other: RDD[T]): RDD[T]
scala> val rdd = sc.parallelize(3 to 8)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[70] at parallelize at <console>:24
scala> val rdd1 = sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[71] at parallelize at <console>:24
scala> rdd.subtract(rdd1).collect()
res27: Array[Int] = Array(8, 6, 7)
4、RDD的行动
Action
<1>reduce
/** 通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 */
def reduce(f: (T, T) => T): T
scala> val rdd1 = sc.makeRDD(1 to 10,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[85] at makeRDD at <console>:24
scala> rdd1.reduce(_+_)
res50: Int = 55
<2>collect
/** 将RDD的数据返回到driver层输出 */
def collect(): Array[T]
scala> val rdd = sc.makeRDD(1 to 10,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> rdd.collect
res0: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
<3>count
/** 计算RDD的数据数量,并输出 */
def count(): Long
scala> rdd.count
res1: Long = 10
<4>take
/** 返回RDD的前n个元素 */
def take(num: Int): Array[T]
scala> rdd.take(5)
res2: Array[Int] = Array(1, 2, 3, 4, 5)
<5>first
/** 返回RDD的第一个元素 */
def first(): T
scala> rdd.first
res3: Int = 1
<6>takeSample
/** 返回一个随机抽样后的结果集 */
def takeSample(
withReplacement: Boolean,
num: Int,
seed: Long = Utils.random.nextLong): Array[T]
scala> val rdd = sc.makeRDD(1 to 10,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> rdd.takeSample(true, 5, 3)
res4: Array[Int] = Array(3, 5, 5, 9, 7)
<7>takeOrdered
/** 返回一个排序后的结果集 */
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
scala> val rdd1 = sc.parallelize(Array(1, 4, 10, 9, 2))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> rdd1.takeOrdered(5)
res7: Array[Int] = Array(1, 2, 4, 9, 10)
<8>aggregate
/** aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。 */
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
scala> var rdd1 = sc.makeRDD(1 to 10,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[88] at makeRDD at <console>:24
scala> rdd1.aggregate(1)(
| {(x : Int,y : Int) => x + y},
| {(a : Int,b : Int) => a + b}
| )
res56: Int = 58
scala> rdd1.aggregate(1)(
| {(x : Int,y : Int) => x * y},
| {(a : Int,b : Int) => a + b}
| )
res57: Int = 30361
<9>fold
/** aggregate简化操作,seqOp、combOp相等*/
def fold(zeroValue: T)(op: (T, T) => T): T
scala> var rdd1 = sc.makeRDD(1 to 4,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[90] at makeRDD at <console>:24
scala> rdd1.fold(1)(_+_)
res60: Int = 13
<10>saveAsTextFile
/**将数据集的元素以文件的形式保存到HDFS文件系统或者其他支持的文件系统 */
def saveAsTextFile(path: String): Unit
<11> saveAsSequenceFile
/**将文件存为SequenceFile */
def saveAsSequenceFile(
path: String,
codec: Option[Class[_ <: CompressionCodec]] = None): Unit
<12>saveAsObjectFile
/** 将文件存为ObjectFile */
def saveAsObjectFile(path: String): Unit
<13>countByKey
/** 返回每个key的数据的数量 */
def countByKey(): Map[K, Long]
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[95] at parallelize at <console>:24
scala> rdd.countByKey()
res63: scala.collection.Map[Int,Long] = Map(3 -> 2, 1 -> 3, 2 -> 1)
<14>foreach
/** 对每一个元素进行处理 */
def foreach(f: T => Unit): Unit
scala> var rdd = sc.makeRDD(1 to 10,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[107] at makeRDD at <console>:24
scala> rdd.collect().foreach(println)
1
2
3
4
5
6
7
8
9
10
5、数值RDD的统计操作
1、RDD数值统计操作
1、Spark对包含数值数据的RDD提供了一些描述性的统计操作。Spark的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建模型。这些统计数据都会在调用stats()时通过一次遍历将数据计算出来,并以StatsCounter对象返回。
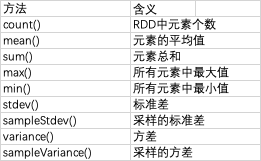
2、向RDD操作传递函数注意
Spark的大部分转化操作和部分行动操作,都需要依赖用户传递的函数来计算。在Scala中,可以把定义的内联函数、方法的引用或者是静态方法传给Spark,就像是Scala的其他函数API一样。还有一些细微的细节需要考虑:如传递的函数及引用的数据需要可序列化的(实现了Serializable接口);传递一个对象的方法或字段时,会包含对整个对象的引用。
注意:如果是在Scala中出现了NotSerializableException,问题通常在于我们传递了一个不可以序列化的类中的函数或者字段。