版权声明:本文版权归作者和CSDN共有,欢迎转载。转载时请注明原作者并保留此段声明,若不保留我也不咬你,随你了=-=。 https://blog.csdn.net/TeFuirnever/article/details/89072686
近期在看KNN代码时碰到了一个readline()函数,所以顺便特意对比了三个函数,特此记录。
python read()、readline()、readlines()函数用于读取文件。
准备工作:
1、read()函数
read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象。
f = open("a.txt")
lines = f.read()
print lines
print(type(lines))
f.close()
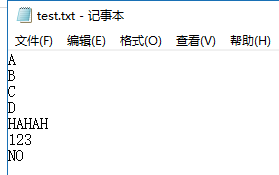
> A
B
C
D
HAHAH
123
NO
<class 'str'>
2、readline()函数
readline()每次读出一行内容,所以,读取时占用内存小,比较适合大文件,返回字符串对象,每次读取时遇到换行符\n就停止,下一次从下一行继续读取。
fr = open("test.txt","r")
for i in range(8):
text1 = fr.readline()
print(type(text1))
print(text1)
fr.close()
> <class 'str'>
A
<class 'str'>
B
<class 'str'>
C
<class 'str'>
D
<class 'str'>
HAHAH
<class 'str'>
123
<class 'str'>
NO
<class 'str'>
3、readlines()函数
readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,读取大文件会比较占内存。
fr = open("test.txt","r")
text = fr.readlines()
print(text)
print(type(text))
fr.close()
> ['A\n', 'B\n', 'C\n', 'D\n', 'HAHAH\n', '123\n', 'NO']
<class 'list'>