前言
做了这么多准备工作之后,终于正式进入Hadoop的配置了
避免CentOS中的bug
这一步只有CentOS需要做,Ubuntu那些系统不需要
进入etc下的hadoop

1.固定hadoop_env.sh中的JAVA_HOME

2.固定mapred-env.sh中的JAVA_HOME
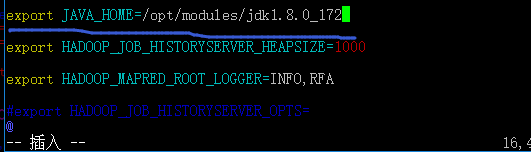
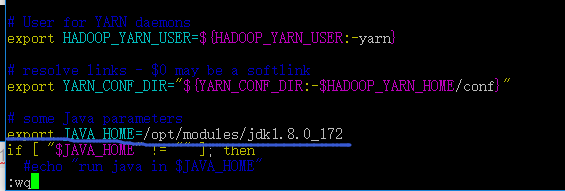
3.固定yarn-env.sh中的JAVA_HOME
修改配置文件
进入etc下的hadoop
1.修改core-site.xml
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node107:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.6/data/tmp</value>
</property>
直接在配置中粘贴上面的信息,记得修改地址与路径

2.修改hdfs-site.xml
<!-- 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 辅助名称结点 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node108:50090</value>
</property>
添加以上内容,值根据自己需要修改

3.修改slaves
这个是用来设置DataNode,一般NameNode不会和DataNode设置在一起,但我只有三个机器就把它也设置上了。
4.修改yarn-site.xml
这里的ResourceManager一般也不会和NameNode开在一起,但我为了省事也开在一起了。

5.修改mapred-site.xml
mv mapred-site.xml.template mapred-site.xml重命名一下
vim mapred-site.xml添加如下内容
<!-- 指定 mr 运行在 yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

分发文件
为了让配置在每台机器都生效

格式化namenode
hdfs namenode -format
这步一定要在大数据用户下操作,看看日志有没有什么异常信息

其中常见的一种错误是权限不够,需要修改父目录的所有者

如果格式化出现问题,记得删除上一次生成的存储目录
启动集群
进入Hadoop下的sbin目录
1.start-all.sh启动
注意第一次启动千万别是root,否则其他用户启动会出现权限问题

2.hdfs界面
能连上就启动成功了

3.yarn界面
能连上就启动成功了

4.jps查看一下所有进程
如果之前两个脚本完成后,未将jps放到用户的sbin或者系统的bin下,那将无法使用jps命令


常见权限问题
总结了以上操作容易出现的权限问题
以root进行格式化
1.删除存储目录并以bduser再次格式化,我的存储目录就是data

以root进行首次启动
1.将存储目录下的所有者改为bduesr

2.将logs所有者改为bduser

3.将/tmp/下面与Hadoop相关文件所有者改为bduser
