这算是核心部分了,首先下载hadoop-2.6.4.tar.gz源文件,放入/opt目录下
指令:# tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
解压到/usr/local目录,依次修改/usr/local/hadoop-2.6.4/etc/hadoop目录下的配置文件
一
[root@master hadoop]# vi core-site.xml
添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<property>
</configuration>
二
[root@master hadoop]# vi hadoop-env.sh
修改为
export JAVA_HOME=/usr/java/jdk.1.8.0_201(P.S.:实时版本)
三
[root@master hadoop]# vi yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/java/jdk.1.8.0_201
四
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:19888</value>
</property>
</configuration>
五
[root@master hadoop]# vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tacker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<propertv>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
<description>URI for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>varn.nodemanager.aux-services</name>
<value>map.reduce_shuffle</value>
</property>
<property>
<name>varn.nodemanager.aux-services.mapreduce.shuffle.class </name>
<value>>org.apache.hadoop.mapred.Shufflehandle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048<value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
<property>
<name>yarn.nodemanager.resourcecpu-vcores</name>
<value>1</value>
</property>
</configuration>
六
[root@master hadoop]# vi slaves
添加
slave1
slave2
slave3
七
[root@master hadoop]# vi hdfs-site.xml
添加
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
八
[root@master ~]# vi /etc/hosts
192.168.1.130 master master.centos.com
192.168.1.131 slave1 slavel1.centos.com
192.168.1.132 slave2 slavel2.centos.com
192.168.1.133 slave3 slavel3.centos.com
下面就是克隆虚拟机的过程
克隆功能再虚拟机的管理选项中,复制三个分别为slave1、slave2、slave3
针对slave1说明,其他的重复操作

删除该文件
ifconfig -a,查看HWADDR,作记录之后修改
![]()
修改网络设置如下(黄色为修改部分)

修改机器名
![]()
![]()
完成后重启虚拟机
从master检验slave1是否配置成功
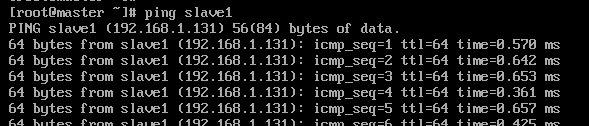
之后的虚拟机都重复此操作
P.S.:这部分手打代码较多,不确定以后会不会出现问题。。。祈祷顺利进行