版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/leadingsci/article/details/89286583
文章目录
数据下载地址
对比Excel,轻松学习Python数据分析
http://www.broadview.com.cn/book/5981
4.1 导入外部数据
4.1.1 导入.xlsx文件
路径方式为win \ ,签名加r可以不用反号,不加r需要反号
路径方式为linux /
# 基本导入,加r
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx")
df
# 不加r
df = pd.read_excel("C:/Users/leadi/Python/01.python/input/train-pivot.xlsx")
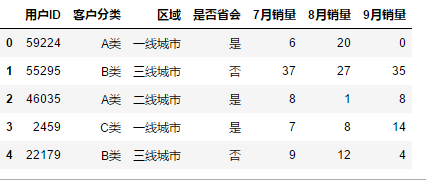
指定导入哪个Sheet
# 按名称
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = 0)
# 按序号,默认为0
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = "Sheet1")
df
指定行索引
默认为数字索引,
指定某列为行索引
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = "Sheet1",index_col = 0)
df
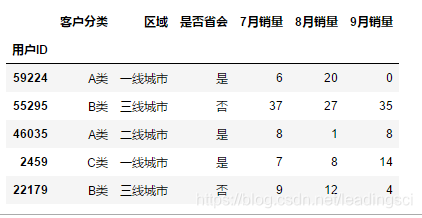
指定列索引
header参数默认为0行
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = "Sheet1",header=0)
df
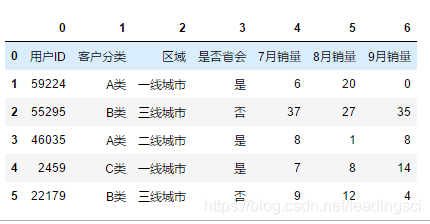
# 不要header时,自动以数字为索引
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = "Sheet1",header=None)
df
指定导入列
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = "Sheet1",usecols = 0)
df
df = pd.read_excel(r"C:\Users\leadi\Python\01.python\input\train-pivot.xlsx",sheet_name = "Sheet1",usecols = [1,2])
df

4.1.2 导入.csv文件
直接导入
报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
原因:有中文存在,csv不支持
将中文删去,再次读入
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot2.csv")
df
# 指定分隔符
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot2.csv",sep=",")
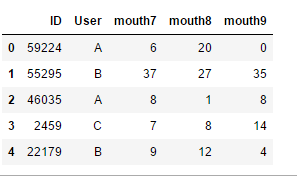
指定编码格式
中文回来了
# 指定编码格式,默认为utf-8
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot2.csv",encoding = "utf-8")
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.csv",encoding = "gbk")
df
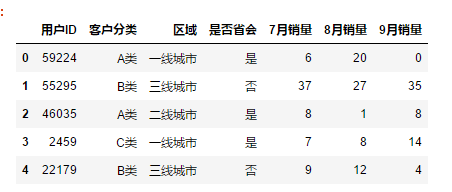
engine指定
当文件路径或文件名包含中文时,会报错;
原因:reads_csv() ,默认使用C语言作为解析语言,将C更改为Python,就能解决。
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.csv",encoding = "gbk",engine="python")
如果文件格式为csv utf-8(逗号分隔),编码格式需要给为utf-8-sig;
如果文件格式为csv (逗号分隔),编码格式需要给为gbk;
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.csv",encoding = "utf-8-sig")
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.csv",encoding = "gbk")
4.1.3 导入.txt文件
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.txt",sep = "\t",encoding="gbk")
df
4.1.4 导入sql文件
# 导入pymysql模块
import pymysql
# 创建连接
eng = pymysql.connet(host = "localhost",user = "user",password = "passwd",db = "db",charset = "ustf8")
# 用户名,密码,数据库地址,本机地址使用localhost,数据库名,数据集编码,一般为UTF-8
# 查询语句
pd.read_sql(sql,eng)
4.2 新建数据
pd.DataFrame()
4.3 熟悉数据
4.3.1 查看部分数据head()
df.head()
df.head(2)
df.tail()
4.3.2 利用shape获取数据表的大小
df.shape
输出
(5, 7)
4.3.3 利用info获取数据类型
df.info()

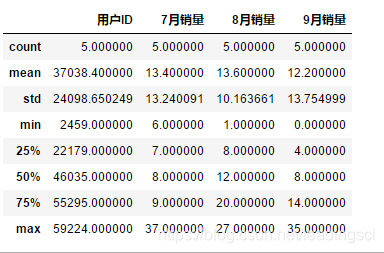
4.3.4 利用describe获取数值分布情况
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.txt",sep = "\t",encoding="gbk")
df.describe()