正则表达式可以提高复杂文本分析的效率,面试时常会问到相关知识,本文我们将一起学习介绍了Python正则表达式基本概念、为什么使用正则表达式、正则语法、re模块及相关方法使用,如何使用正则表达式处理文件,让我们对python正则全面了解。
简单的文本处理可以使用字符串匹配,使用endwith和startwith函数加上字符串切片可以完成,但是当匹配的量太大,规则太多,使用正则表达式显得更游刃有余。
正则表达式的概念
- 使用单个字符串来描述匹配一系列符合某个句法规则的字符串
- 是对字符串操作的一种逻辑公式
- 应用场景:处理文本和数据
- 正则表达式过程:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功,否则匹配失败
正则表达式之re模块使用:
re:python正则表达式模块
实例

import re #导入re模块
pa = re.compile(r'imooc') #匹配的字符,r指的是原字符串,返回的是pattern 对象
ma = pa.match('imooc.com') #使用pattern对象的match()方法,返回none或一个match对象
ma.group() ==>imooc #返回匹配的字符
ma.span() ==>(0,5) #被匹配字符串所在索引位置
ma.string ==>'imooc.com' #返回被匹配字符串
上面实例中,re.compile(r"***")是主要用来匹配正则表达式的方法,可以添加不同的参数,比如加括号,用ma.groups()返回一个数组,可以加上re.I来ignore大小写匹配
而且
——str1=‘imooc python’
pa=re.compile(r’imooc’) #先生成一个对象,这个对象可以重复使用
ma=pa.match(str1) #再调用对象的match方法
——ma=re.match(r’imooc’,str1) #这样写的效果与上面的是一样的,只是用re生成临时对象,没调用一次就要生成一次
正则表达式的基本语法语法不仅适用于python,对其他的语言也适用,让我们一起来熟悉正则表达式的基本语法:
1.匹配单个字符语法:
| 字符 | 匹配 |
|---|---|
| . | 匹配任意字符(除\n以外) |
| […] | 匹配字符集,比如[a-zA-Z0-9] |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \d | 匹配一个数字字符。等价于 [0-9] |
| \w | 匹配任何单词字符等价于 [A-Za-z0-9] |
| \W | 匹配任何非单词字符等价于[^A-Za-z0-9_] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等 等价于 [ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [A-Z] | 匹配任何大写字母 |
| [a-z] | 匹配任何小写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
- 匹配多个字符语法:
| 字符 | 匹配 |
|---|---|
| + | 匹配前一个字符1次或者无限次 |
| ? | 匹配前一个字符0次或者1次 |
| {m}/{m,n} | 匹配前一个字符m次或者m到n次 |
| * | 匹配前一个字符0次或者无限次 |
| *?/+?/?? | 匹配模式为非贪婪,尽可能少匹配字符,不加?为贪婪模式 |
实例:判断变量Python有效性,变量必须以下划线或者字母开头
正则表达式为r’[_a-zA-z]+[下划线\w]*'
*非贪婪模式匹配,就是尽量匹配少一点,所以如果是 * 可以匹配0或多次,那么 ? 就只匹配0次, 同理 + 匹配1到多次,那么 +? 就只匹配1次
- 边界匹配基本语法
| 字符 | 匹配 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \A/\Z | 指定字符串必须出现在开头/结尾(\Aimooc表示以imooc开头) |
- 分组匹配基本语法
| 字符 | 匹配 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 括号中表达式作为一个分组 |
| (?P) | 分组起一个别名 |
| <number> | 引用编号为number的分组匹配到的字符串 |
| (?P=name) | 引用别名为name的分组匹配字符串 |
re模块的其他方法:
- search(pattern,string,flags=0)在一个 字符串中 查找 匹配
- findall(pattern,string,flags=0)找到匹配,返回所有匹配部分的列表
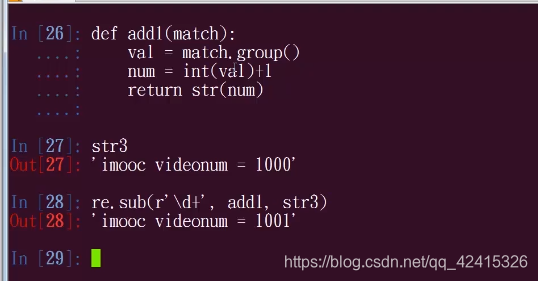
- sub(pattern,repl,string,count=0,flags=0) 将字符串中正则表达式的部分替换成其他值
sub中的repl可以是pattern匹配后返回match对象的函数操作
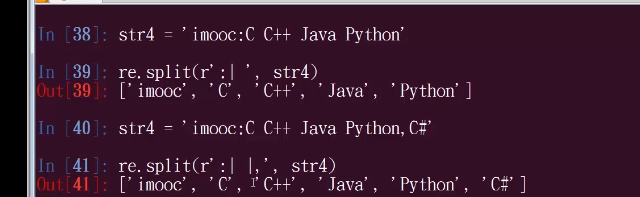
- split(pattern,string,maxsplit=0,flags=0),根据匹配分割字符串,返回分割字符串组成的列表
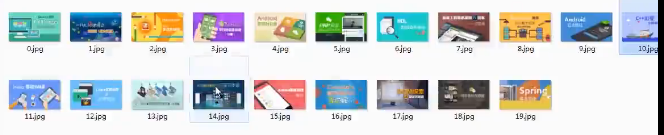
python正则练习之抓取网页图片——慕课网课程图片为例:
简单爬取网页图片步骤:
1)分析网页元素
2)使用urllib2打开链接
3)读取链接文本
4)使用re匹配出期望文本内容并分条存入list
5)创建文件定义文件名规则,并将list中的链接逐条用urllib2打开后写入
#导入re模块和urllib模块中的request
import re
from urllib import request
#匹配图片网址,存入列表变量listurl
url = 'https://www.imooc.com/course/list'
buf = request.urlopen(url).read().decode('utf-8')
listurl = re.findall(r'src=.+\.jpg',html)
#把src="去掉
for i in range(len(listurl)):
listurl[i] = re.sub(r'src="',"",listurl[i])
#遍历列表listurl中的图片网址,取出图片写入本地文件中
i = 0 #图片编号变量
for url in listurl:
f = open(str(i)+'.jpg','wb+') #相对路径, wb+方式打开
buf = request.urlopen(”https:"+url).read() #要加https:,是通过查看网页审查元素得出的
f.write(buf)
f.close()
i += 1
结果如下: