业务场景如下. 商业合作中有招揽人(attracter)和负责人(manager)以及业务的收入金额(amount). 现在需要根据部门去统计所有商业合作业务的收入金额. 部门为 招揽人 + 负责人的部门. (ps: 如果同一个业务中的attacter所属的部门和manager所属部门是同一个的话,那收入金额不叠加计算【只算一次】)

数据如上, 查询出来的结果应该是:

思路 :
attacterDept和managerDept需要聚合查询. 故要用到union all
select business,attractDept dept,amount from t_business
union all
select business,managerDept dept,amount from t_business结果如下:
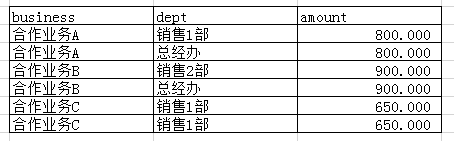
如果这个时候直接在这个表的基础上进行 group by dept. 销售1部的amount就会出现问题(因为业务和部门是同一个)
那么我们需要先把这个去重: 去重依据是 "如果同一个业务的招揽人部门和负责人部门相同,则去重". 此处使用group by去重
select o.business,o.dept,max(o.amount) amount from
(
select business,attractDept dept,amount from t_business
union all
select business,managerDept dept,amount from t_business
) o group by business,dept结果如下: 已经把销售1部去重了

接下来就在上面表的基础上进行group by dept. 即可得到结果
select v.dept,sum(v.amount) amount from
(
select o.business,o.dept,max(o.amount) amount from
(
select business,attractDept dept,amount from t_business
union all
select business,managerDept dept,amount from t_business
) o group by o.business,o.dept
) v group by v.dept查询的结果可以出来了.但以上sql存在union all和两重子查询,查询性能是较低的.
后面尝试把这个表直接查询出来,然后在分组中进行排序和统计
select business,attractDept, managerDept,amount from t_business
具体代码就不上了.主要思路是:
1.先把查询出来的集合中的所有dept都放在一个Map<String,Bigdecimal>中,key 是dept的id, key用于统计amount.
2.然后遍历查询出来的集合, 统计attractDept和managerDept的amount,其中统计managerDept 时则要判断下 两个dept是否相同.
排序的话就使用 Comparator 实现.