版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_36169781/article/details/89355441
本文记录了使用3台物理机部署Hadoop完全分布式集群的过程,所使用系统为Ubuntu16.04 LTS,Hadoop版本为Hadoop 2.7.7。
搭建前的准备
注意:
※ 下载密码:kevin
※ 教程中所有shell命令,如果没有特殊说明,全部都需要单步执行,不能批量粘贴。
免密登录
- 新装系统分别设置如下参数
| No. | 姓名 | 计算机名 | 用户名 |
|---|---|---|---|
| 1(主节点) | master | master | hadoop |
| 2(子节点) | slave1 | slave1 | hadoop |
| 3(子节点) | slava2 | slave2 | hadoop |
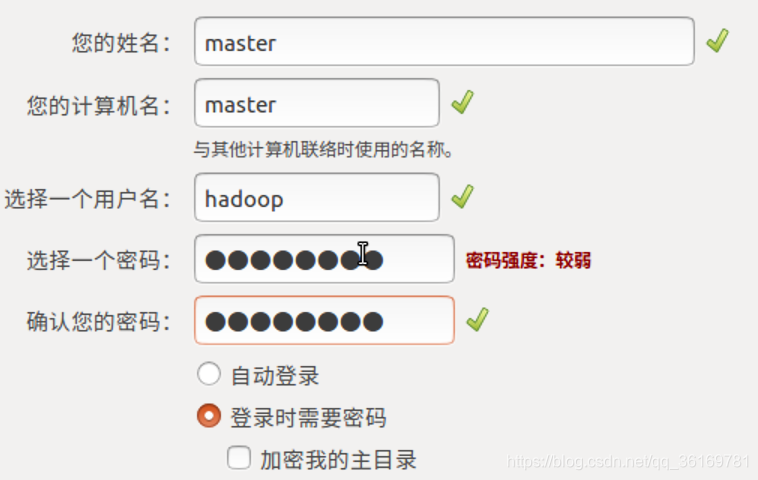
这里的情况是全新安装的系统,如果有已经安装的系统,可以为3台电脑分别创建hadoop用户并授予su权限加入hadoopGropu即可。
- 为3台物理机设置静态IP,方法参考百度。
- 检查hostname,以master机器为例,如果hostname不是master,需要修改为master,三台都需要检查。
$ sudo gedit /etc/hostname - 设置Hosts(三台同步操作)
输入以下命令编辑hosts文件ifconfig #查看IP
在hosts中添加master、slave1、slave2的映射,每条记录一行$ sudo gedit /etc/hosts
设置完后保存,在三台主机上互相ping,检测是否ping通:192.168.0.1 master 192.168.0.2 slave1 192.168.0.3 slave2$ ping slave1 -c 4 $ ping slave2 -c 4 $ ping master -c 4 - 安装SSH并生成密钥对(三台同步)
尝试登录本机后,如果出现$ sudo apt-get install opensssh-server #安装SSH $ ps -e | grep ssh #查看SSH进程是否启动 $ ssh localhost #尝试登陆本机Welcome to Ubuntu 16.04 LTS ....Last login: xxxxxx即为成功。$ ssh-keygen -t rsa #生成密钥对,输入后直接按三次回车,不需要输入密码。 $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #密钥追加到认证公钥 $ sudo chmod 600 authorized_keys #更改权限为600 - 分别在两个子节点上获取主节点master的密钥
完成后回到master上,测试登陆是否免密:$ cd ~/.ssh $ scp hadoop@master:~/.ssh/id_rsa.pub ./master_rsa.pub $ cat master_rsa.pub >> authorized_keys #将master的密钥增加到子节点的认证公钥$ ssh slave1 #测试登陆节点1 $ ssh slave2 #测试登陆节点2
安装JDK/Hadoop/Spark/Scala
master上,将博客开头的JDK和Hadoop包下载,并使用终端进入所在目录,逐条执行以下命令:
$ cd Downloads #进入下载目录
$ sudo tar -zxvf jdk-8u201-linux-x64.tar.gz -C /usr/lib/jvm #/ 解压java到/usr/lib/jvm目录下
$ sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local #解压hadoop到/usr/local目录下
$ sudo tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /usr/local #解压spark到/usr/local目录下
$ sudo tar -zxvf scala-2.12.0.tgz -C /usr/local #解压scala到/usr/local目录下
$ cd /usr/lib/jvm
$ sudo mv jdk1.8.0_201 java #重命名
$ cd /usr/local
$ sudo mv hadoop-2.7.7 hadoop #重命名
$ sudo mv spark-2.3.3-bin-hadoop2.7 spark
$ sudo mv scala-2.12.0 scala
$ sudo chown -R hadoop ./hadoop #修改权限
暂时先不配置环境变量。
修改Spark配置文件
spark-env.sh$ cd spark/conf $ cp spark-env.sh.template spark-env.sh $ sudo gedit spark-env.sh
修改内容:
export SCALA_HOME=/usr/local/scala
export JAVA_HOME=/usr/lib/jvm/java
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
slaves$ cp slaves.template slaves $ sudo gedit slaves
修改内容:
master
slave1
slave2
修改Hadoop配置文件
$ cd /usr/local/hadoop/etc/hadoop #进入Hadoop配置文件目录
本节涉及slaves hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml 6个文件的修改。
slaves
删除localhost,增加:$ sudo gedit slavesmaster slave1 slave2hadoop-env.sh
修改$ sudo gedit hadoop-env.shJAVA_HOME:export JAVA_HOME=/usr/lib/jvm/javacore-site.xml
修改configuration节:$ sudo gedit core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>hdfs-site.xml$ sudo gedit hdfs-site.xml<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <!-- 集群一共有多少机器就填几 --> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/hdfs/data</value> </property> </configuration>mapred-site.xml
修改配置节:$ cp mapred-site.xml.template mapred-site.xml #复制模板,生成xml $ sudo gedit mapred-site.xml # 打开<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:19888</value> </property> </configuration>yarn-site.xml
修改配置节:$ sudo gedit yarn-site.xml<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration>- 配置完成后,使用master将整个hadoop、Java、Spark和Scala发送到两个子节点:
$ scp -r /usr/local/hadoop hadoop@slave1:/usr/local $ scp -r /usr/local/hadoop hadoop@slave2:/usr/local $ scp -r /usr/local/spark hadoop@slave1:/usr/local $ scp -r /usr/local/spark hadoop@slave2:/usr/local $ scp -r /usr/local/scala hadoop@slave1:/usr/local $ scp -r /usr/local/scala hadoop@slave2:/usr/local $ scp -r /usr/lib/jvm hadoop@slave1:/usr/lib $ scp -r /usr/lib/jvm hadoop@slave2:/usr/lib - 在集群所有机器上分别配置hadoop、Java、Spark和Scala的环境变量,所有机器。
$ cd ~ $ sudo gedit ~/.bashrc
将下列内容追加到文件尾部:
#JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#Spark
export SPARK_HOME=/usr/local/spark
export PATH="$SPARK_HOME/bin:$PATH"
#Scala
export SCALA_HOME=/usr/local/scala
刷新环境变量
$ source ~/.bashrc
- 在所有机器上检查hadoop、Java、Spark和Scala环境,查看是否安装成功。
$ java -version #查看Java版本 $ hadoop version #查看hadoop版本 $ scala #查看Scala环境 $ spark-shell #查看Spark环境
启动集群(master上操作)
- 在master上格式化NameNode。(只在master上执行,且只执行一次)
$ hadoop namenode -format - 启动:
如果启动成功,此时master终端输入$ cd /usr/local/hadoop/sbin #Hadoop的执行目录 $ start-all.sh #启动jps可以看到NameNode和SecondaryNameNode等进程,slave有DataNode等进程。
因为只有3台机器,完全分布式至少有3个冗余,所以master在集群中既充当NameNode也充当DataNode,在master上jps也会出现DataNode进程。