1.修改网卡
- vi /etc/udev/rules.d/70-persistent-ipoib.rules (进入后首先删除你复制的之前的网卡信息,接着修改 name=“当前网卡名”)
- vi /etc/sysconfig/network (修改主机名:HOSTNAME=*****这里是你的主机名)
- vi /etc/sysconfig/network-script/ifcfg-eno33 (修改 HWADDR=当前的主机MAC地址,如果IP地址相同的话,也要修改IP
- 这里的MAC地址


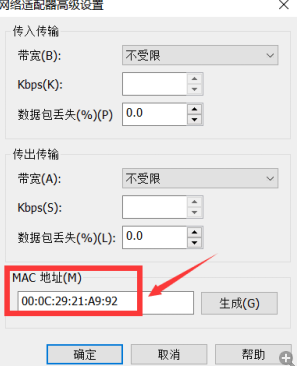
- vi /etc/hosts (添加其他主机IP地址和主机名称)
- service network restart (重启网卡)
- reboot 重启虚拟机
2.重启网卡后,执行失败,错误如下:
# service network restart
Restarting network (via systemctl): Job for network.service failed because the control process exited with error code. See "systemctl status network.service" and "journalctl -xe" for details.
修正:
大部分人常用
systemctl stop NetworkManager
systemctl disable NetworkManager
但是我之前试了很久,但是没用,之后使用了如下命令:
修改网卡名称 将所有的enoxxx改为eth0,
cd /etc/sysconfig/network-scripts/
mv ifcfg-ens33 ifcfg-eth0
vi /etc/sysconfig/network-scripts/ifcfg-eth0

vi /etc/sysconfig/grub
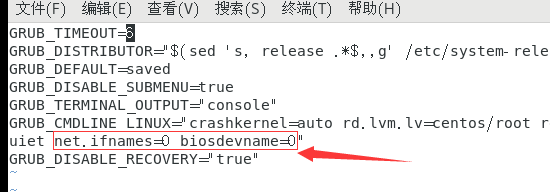
下一步,生成菜单
grub2-mkconfig -o /boot/grub2/grub.cfg
最后重启 reboot
开启后,就可使用 systemctl restart network
3.出现ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes时,如下图

- vi ./sbin/start-dfs.sh
- 顶部添加如下四行

- 然后重启就可以了
- 同时也得修改 ./sbin/start-dfs.sh
- TANODE_USER=root
- HADOOP_SECURE_DN_USER=hdfs
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
4. ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 10 10
可以执行,但是
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount ./input/ ./output
不可执行,错误代码如下:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount ./input/ ./output
2019-03-12 09:15:41,285 INFO impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-03-12 09:15:41,408 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2019-03-12 09:15:41,408 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2019-03-12 09:15:41,870 INFO mapreduce.JobSubmitter: Cleaning up the staging area file:/tmp/hadoop/mapred/staging/root1632457010/.staging/job_local1632457010_0001
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://master:9000/user/root/input
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:330)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:272)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:394)
修正以上错误,如下:
没有把input文件夹放入hadoop集群中
5.[root@master hadoop-3.0.3]# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 10 10
Number of Maps = 10
Samples per Map = 10
java.net.ConnectException: Call From master/192.168.13.132 to master:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
修正:
启动hadoop集群服务
./sbin/start-all.sh