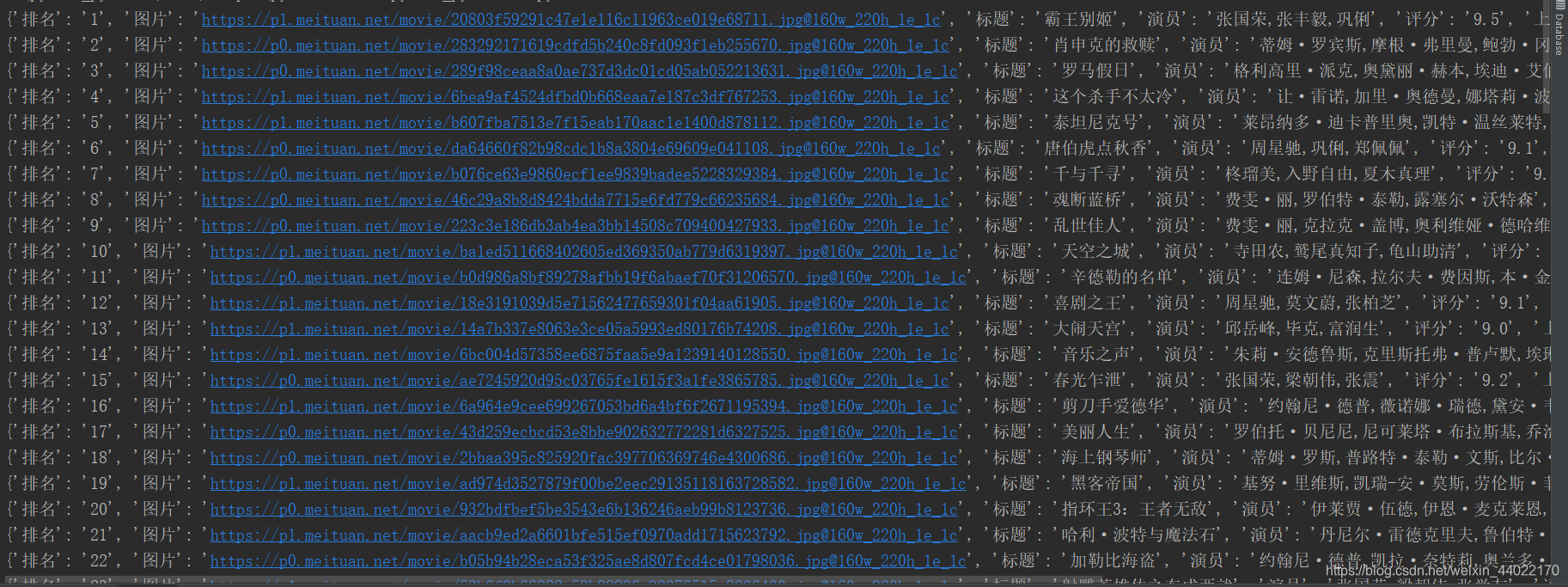
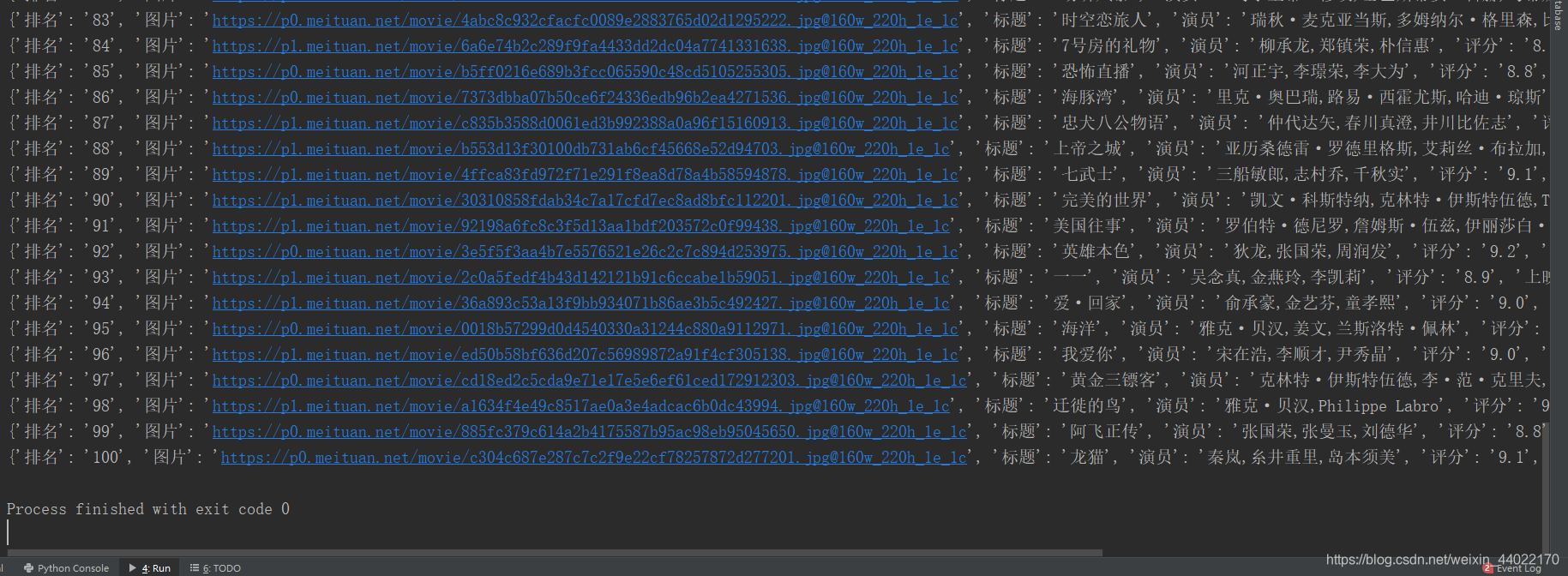
猫眼电影排行信息
python
import requests
from pyquery import PyQuery as pq
import json
#获取网页源码
def getPage(url):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code==200:
return response.text
else:
return None
#解析页面
def parsePage(html):
list=[]
doc=pq(html)
items=doc('dd').items()
for item in items:
#排名
ranking=item('.board-index').text()
#图片
img=item('.board-img').attr('data-src')
#标题
title=item('.name a').text()
#演员
actor=item('.star').text()
actor=actor.replace('主演:','')
#评分
score=item('.score').text()
#date
showTime=item('.releasetime').text().replace('上映时间:','')
info={'排名':ranking,'图片':img,'标题':title,'演员':actor,'评分':score,'上映时间':showTime}
list.append(info)
return list
#文件写入
def writeToFile(content):
with open('F:\\topTen.txt','a') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n--------------------------------------------------------------------\n')
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset) # url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = getPage(url)
items = parsePage(html)
for item in items:
writeToFile(item)
print(item)
for page in range(0,10):
offset = page * 10
main(offset)